Köra NAMD med Microsoft HPC Pack på Linux-beräkningsnoder i Azure
Viktigt
Klassiska virtuella datorer dras tillbaka den 1 mars 2023.
Om du använder IaaS-resurser från ASM slutför du migreringen senast den 1 mars 2023. Vi rekommenderar att du gör bytet snabbare för att dra nytta av de många funktionsförbättringarna i Azure Resource Manager.
Mer information finns i Migrera dina IaaS-resurser till Azure Resource Manager senast den 1 mars 2023.
Den här artikeln visar ett sätt att köra en HPC-arbetsbelastning (Databehandling med höga prestanda i Linux) på virtuella Azure-datorer. Här konfigurerar du ett Microsoft HPC Pack-kluster på Azure med Linux-beräkningsnoder och kör en NAMD-simulering för att beräkna och visualisera strukturen för ett stort biomolekylulärt system.
Anteckning
Azure har två olika distributionsmodeller för att skapa och arbeta med resurser: Resource Manager och klassisk. Den här artikeln täcker bägge modellerna, men Microsoft rekommenderar de flesta nya distributioner att använda Resource Manager-modellen.
- NAMD (för Nanoscale Molecular Dynamics-programmet) är ett parallellt molekylärt dynamikpaket som är utformat för högpresterande simulering av stora biomolekylära system som innehåller upp till miljontals atomer. Exempel på dessa system är virus, cellstrukturer och stora proteiner. NAMD skalas till hundratals kärnor för typiska simuleringar och till mer än 500 000 kärnor för de största simuleringarna.
- Microsoft HPC Pack innehåller funktioner för att köra storskaliga HPC- och parallella program i kluster med lokala datorer eller virtuella Azure-datorer. HPC Pack utvecklades ursprungligen som en lösning för Windows HPC-arbetsbelastningar och har nu stöd för att köra Linux HPC-program på virtuella Linux-beräkningsnoddatorer som distribuerats i ett HPC Pack-kluster. En introduktion finns i Komma igång med Linux-beräkningsnoder i ett HPC Pack-kluster i Azure .
Förutsättningar
- HPC Pack-kluster med Linux-beräkningsnoder – Distribuera ett HPC Pack-kluster med Linux-beräkningsnoder på Azure med hjälp av antingen en Azure Resource Manager-mall eller ett Azure PowerShell skript. Se Kom igång med Linux-beräkningsnoder i ett HPC Pack-kluster i Azure för att se förutsättningarna och stegen för något av alternativen. Om du väljer distributionsalternativet för PowerShell-skript kan du läsa exempelkonfigurationsfilen i exempelfilerna i slutet av den här artikeln. Den här filen konfigurerar ett Azure-baserat HPC Pack-kluster som består av en Windows Server 2012 R2-huvudnod och fyra stora CentOS 6.6-beräkningsnoder. Anpassa den här filen efter behov för din miljö.
- NAMD-programvara och självstudiefiler – Ladda ned NAMD-programvara för Linux från NAMD-webbplatsen (registrering krävs). Den här artikeln är baserad på NAMD version 2.10 och använder arkivet Linux-x86_64 (64-bitars Intel/AMD med Ethernet). Ladda också ned NAMD-självstudiefilerna. Nedladdningarna är .tar-filer och du behöver ett Windows-verktyg för att extrahera filerna på klustrets huvudnod. Om du vill extrahera filerna följer du anvisningarna senare i den här artikeln.
- VMD (valfritt) – Om du vill se resultatet av ditt NAMD-jobb laddar du ned och installerar det molekylära visualiseringsprogrammet VMD på en dator som du väljer. Den aktuella versionen är 1.9.2. Se hämtningsplatsen för VMD för att komma igång.
Konfigurera ömsesidigt förtroende mellan beräkningsnoder
Om du kör ett jobb mellan noder på flera Linux-noder måste noderna lita på varandra ( med rsh eller ssh). När du skapar HPC Pack-klustret med Microsoft HPC Pack IaaS-distributionsskriptet konfigurerar skriptet automatiskt permanent ömsesidigt förtroende för det administratörskonto som du anger. För icke-administratörsanvändare som du skapar i klustrets domän måste du konfigurera tillfälligt ömsesidigt förtroende mellan noderna när ett jobb allokeras till dem. Förstör sedan relationen när jobbet har slutförts. Om du vill göra detta för varje användare anger du ett RSA-nyckelpar till klustret som HPC Pack använder för att upprätta förtroenderelationen. Instruktioner följer.
Generera ett RSA-nyckelpar
Det är enkelt att generera ett RSA-nyckelpar som innehåller en offentlig nyckel och en privat nyckel genom att köra kommandot Linux ssh-keygen .
Logga in på en Linux-dator.
Kör följande kommando:
ssh-keygen -t rsaAnteckning
Tryck på Retur för att använda standardinställningarna tills kommandot har slutförts. Ange inte en lösenfras här. när du uppmanas att ange ett lösenord trycker du bara på Retur.
Ändra katalogen till katalogen ~/.ssh. Den privata nyckeln lagras i id_rsa och den offentliga nyckeln i id_rsa.pub.
Lägg till nyckelparet i HPC Pack-klustret
Anslut via fjärrskrivbord till den virtuella datorn med huvudnoden med de domänautentiseringsuppgifter som du angav när du distribuerade klustret (till exempel hpc\clusteradmin). Du hanterar klustret från huvudnoden.
Använd Windows Server-standardprocedurer för att skapa ett domänanvändarkonto i klustrets Active Directory-domän. Använd till exempel verktyget Active Directory-användare och datorer på huvudnoden. Exemplen i den här artikeln förutsätter att du skapar en domänanvändare med namnet hpcuser i hpclab-domänen (hpclab\hpcuser).
Lägg till domänanvändaren i HPC Pack-klustret som en klusteranvändare. Anvisningar finns i Lägga till eller ta bort klusteranvändare.
Skapa en fil med namnet C:\cred.xml och kopiera RSA-nyckeldata till den. Du hittar ett exempel i exempelfilerna i slutet av den här artikeln.
<ExtendedData> <PrivateKey>Copy the contents of private key here</PrivateKey> <PublicKey>Copy the contents of public key here</PublicKey> </ExtendedData>Öppna en kommandotolk och ange följande kommando för att ange autentiseringsuppgifterna för hpclab\hpcuser-kontot. Du använder parametern extendeddata för att skicka namnet på den C:\cred.xml fil som du skapade för nyckeldata.
hpccred setcreds /extendeddata:c:\cred.xml /user:hpclab\hpcuser /password:<UserPassword>Det här kommandot slutförs utan utdata. När du har angett autentiseringsuppgifterna för de användarkonton som du behöver för att köra jobb lagrar du cred.xml filen på en säker plats eller tar bort den.
Om du genererade RSA-nyckelparet på en av dina Linux-noder bör du komma ihåg att ta bort nycklarna när du har använt dem. HPC Pack konfigurerar inte ömsesidigt förtroende om det hittar en befintlig id_rsa fil eller id_rsa.pub-fil.
Viktigt
Vi rekommenderar inte att du kör ett Linux-jobb som klusteradministratör på ett delat kluster, eftersom ett jobb som skickas av en administratör körs under rotkontot på Linux-noderna. Ett jobb som skickas av en icke-administratörsanvändare körs under ett lokalt Linux-användarkonto med samma namn som jobbanvändaren. I det här fallet konfigurerar HPC Pack ömsesidigt förtroende för den här Linux-användaren för alla noder som allokerats till jobbet. Du kan konfigurera Linux-användaren manuellt på Linux-noderna innan du kör jobbet, eller så skapar HPC Pack användaren automatiskt när jobbet skickas. Om HPC Pack skapar användaren tar HPC Pack bort den när jobbet har slutförts. För att minska säkerhetshotet tas nycklarna bort när jobbet har slutförts på noderna.
Konfigurera en filresurs för Linux-noder
Konfigurera nu en SMB-filresurs och montera den delade mappen på alla Linux-noder så att Linux-noderna kan komma åt NAMD-filer med en gemensam sökväg. Följande är steg för att montera en delad mapp på huvudnoden. En resurs rekommenderas för distributioner som CentOS 6.6 som för närvarande inte stöder Azure File-tjänsten. Om dina Linux-noder stöder en Azure-filresurs läser du Använda Azure File Storage med Linux. Ytterligare fildelningsalternativ med HPC Pack finns i Kom igång med Linux-beräkningsnoder i ett HPC Pack-kluster i Azure.
Skapa en mapp på huvudnoden och dela den till Alla genom att ange läs-/skrivbehörigheter. I det här exemplet är \\CentOS66HN\Namd namnet på mappen, där CentOS66HN är huvudnodens värdnamn.
Skapa en undermapp med namnet namd2 i den delade mappen. I namd2 skapar du en annan undermapp med namnet namdsample.
Extrahera NAMD-filerna i mappen med hjälp av en Windows-version av tar eller ett annat Windows-verktyg som fungerar på .tar-arkiv.
- Extrahera NAMD-tar-arkivet till \\CentOS66HN\Namd\namd2.
- Extrahera självstudiefilerna under \\CentOS66HN\Namd\namd2\namdsample.
Öppna ett Windows PowerShell fönster och kör följande kommandon för att montera den delade mappen på Linux-noderna.
clusrun /nodegroup:LinuxNodes mkdir -p /namd2 clusrun /nodegroup:LinuxNodes mount -t cifs //CentOS66HN/Namd/namd2 /namd2 -o vers=2.1`,username=<username>`,password='<password>'`,dir_mode=0777`,file_mode=0777
Det första kommandot skapar en mapp med namnet /namd2 på alla noder i gruppen LinuxNodes. Det andra kommandot monterar den delade mappen //CentOS66HN/Namd/namd2 i mappen med dir_mode och file_mode bitar inställda på 777. Användarnamnet och lösenordet i kommandot ska vara autentiseringsuppgifterna för en användare på huvudnoden.
Anteckning
Symbolen "'" i det andra kommandot är en escape-symbol för PowerShell. "'," betyder "," (kommatecken) är en del av kommandot.
Skapa ett Bash-skript för att köra ett NAMD-jobb
Ditt NAMD-jobb behöver en nodlistefil för charmrun för att fastställa antalet noder som ska användas när NAMD-processer startas. Du använder ett Bash-skript som genererar nodlistfilen och kör charmrun med den här nodlistfilen. Du kan sedan skicka ett NAMD-jobb i HPC Cluster Manager som anropar det här skriptet.
Använd valfri textredigerare och skapa ett Bash-skript i mappen /namd2 som innehåller NAMD-programfilerna och ge det namnet hpccharmrun.sh. Om du vill ha ett snabbt konceptbevis kopierar du exemplet hpccharmrun.sh skriptet som angavs i slutet av den här artikeln och går till Skicka ett NAMD-jobb.
Tips
Spara skriptet som en textfil med Linux-radslut (endast LF, inte CR LF). Detta säkerställer att den körs korrekt på Linux-noderna.
Nedan visas information om vad bash-skriptet gör.
Definiera vissa variabler.
#!/bin/bash # The path of this script SCRIPT_PATH="$( dirname "${BASH_SOURCE[0]}" )" # Charmrun command CHARMRUN=${SCRIPT_PATH}/charmrun # Argument of ++nodelist NODELIST_OPT="++nodelist" # Argument of ++p NUMPROCESS="+p"Hämta nodinformation från miljövariablerna. $NODESCORES lagrar en lista med delade ord från $CCP_NODES_CORES. $COUNT är storleken på $NODESCORES.
# Get node information from the environment variables NODESCORES=(${CCP_NODES_CORES}) COUNT=${#NODESCORES[@]}Formatet för variabeln $CCP_NODES_CORES är följande:
<Number of nodes> <Name of node1> <Cores of node1> <Name of node2> <Cores of node2>…Den här variabeln visar det totala antalet noder, nodnamn och antalet kärnor på varje nod som allokeras till jobbet. Om jobbet till exempel behöver 10 kärnor för att köras liknar värdet för $CCP_NODES_CORES:
3 CENTOS66LN-00 4 CENTOS66LN-01 4 CENTOS66LN-03 2Om variabeln $CCP_NODES_CORES inte har angetts startar du charmrun direkt. (Detta bör bara inträffa när du kör det här skriptet direkt på dina Linux-noder.)
if [ ${COUNT} -eq 0 ] then # CCP_NODES is_CORES is not found or is empty, so just run charmrun without nodelist arg. #echo ${CHARMRUN} $* ${CHARMRUN} $*Eller skapa en nodelist-fil för charmrun.
else # Create the nodelist file NODELIST_PATH=${SCRIPT_PATH}/nodelist_$$ # Write the head line echo "group main" > ${NODELIST_PATH} # Get every node name and number of cores and write into the nodelist file I=1 while [ ${I} -lt ${COUNT} ] do echo "host ${NODESCORES[${I}]} ++cpus ${NODESCORES[$(($I+1))]}" >> ${NODELIST_PATH} let "I=${I}+2" doneKör charmrun med nodelist-filen, hämta dess returstatus och ta bort nodelist-filen i slutet.
${CCP_NUMCPUS} är en annan miljövariabel som anges av HPC Pack-huvudnoden. Den lagrar antalet totala kärnor som allokerats till det här jobbet. Vi använder den för att ange antalet processer för charmrun.
# Run charmrun with nodelist arg #echo ${CHARMRUN} ${NUMPROCESS}${CCP_NUMCPUS} ${NODELIST_OPT} ${NODELIST_PATH} $* ${CHARMRUN} ${NUMPROCESS}${CCP_NUMCPUS} ${NODELIST_OPT} ${NODELIST_PATH} $* RTNSTS=$? rm -f ${NODELIST_PATH} fiAvsluta med status för snabbkörningsreturen .
exit ${RTNSTS}
Följande är informationen i nodelist-filen, som skriptet genererar:
group main
host <Name of node1> ++cpus <Cores of node1>
host <Name of node2> ++cpus <Cores of node2>
…
Ett exempel:
group main
host CENTOS66LN-00 ++cpus 4
host CENTOS66LN-01 ++cpus 4
host CENTOS66LN-03 ++cpus 2
Skicka ett NAMD-jobb
Nu är du redo att skicka ett NAMD-jobb i HPC Cluster Manager.
Anslut till klusterhuvudnoden och starta HPC Cluster Manager.
I Resurshantering kontrollerar du att Linux-beräkningsnoderna är i onlinetillstånd . Om de inte är det väljer du dem och klickar på Bring Online.
I Jobbhantering klickar du på Nytt jobb.
Ange ett namn för jobbet, till exempel hpccharmrun.
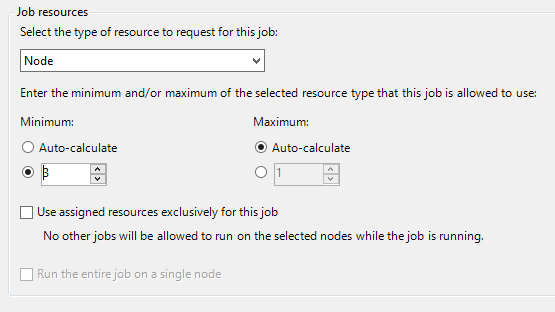
På sidan Jobbinformation under Jobbresurser väljer du resurstypen som Nod och anger Minimum till 3. kör vi jobbet på tre Linux-noder och varje nod har fyra kärnor.
Klicka på Redigera uppgifter i det vänstra navigeringsfältet och klicka sedan på Lägg till för att lägga till en uppgift i jobbet.
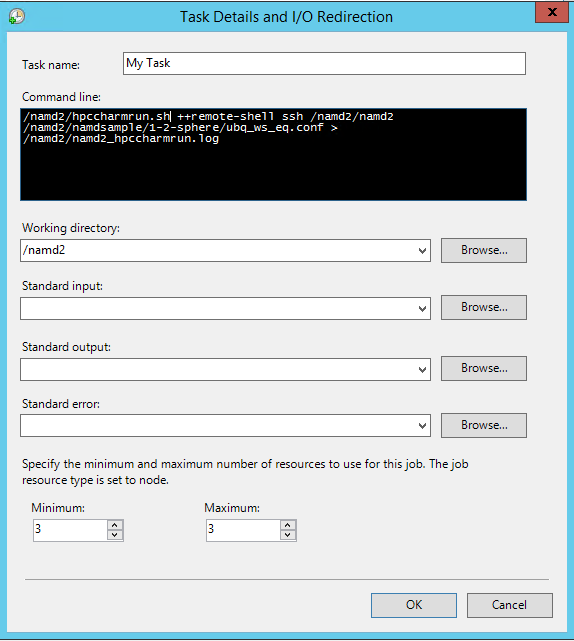
På sidan Aktivitetsinformation och I/O-omdirigering anger du följande värden:
Kommandoraden -
/namd2/hpccharmrun.sh ++remote-shell ssh /namd2/namd2 /namd2/namdsample/1-2-sphere/ubq_ws_eq.conf > /namd2/namd2_hpccharmrun.logTips
Föregående kommandorad är ett enda kommando utan radbrytningar. Den omsluts så att den visas på flera rader under kommandoraden.
Arbetskatalog – /namd2
Minimum - 3
Anteckning
Du anger arbetskatalogen här eftersom charmrun försöker navigera till samma arbetskatalog på varje nod. Om arbetskatalogen inte har angetts startar HPC Pack kommandot i en slumpmässigt namngiven mapp som skapats på en av Linux-noderna. Detta orsakar följande fel på de andra noderna:
/bin/bash: line 37: cd: /tmp/nodemanager_task_94_0.mFlQSN: No such file or directory.Om du vill undvika det här problemet anger du en mappsökväg som kan nås av alla noder som arbetskatalog.
Klicka på OK och klicka sedan på Skicka för att köra det här jobbet.
Som standard skickar HPC Pack jobbet som ditt aktuella inloggade användarkonto. En dialogruta kan uppmana dig att ange användarnamnet och lösenordet när du har klickat på Skicka.
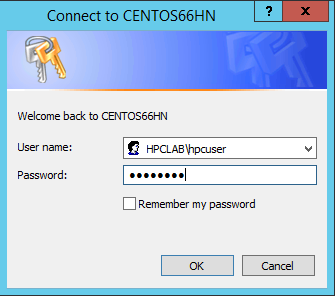
Under vissa förhållanden kommer HPC Pack ihåg den användarinformation som du har angett tidigare och visar inte den här dialogrutan. Om du vill att HPC Pack ska visa det igen anger du följande kommando i en kommandotolk och skickar sedan jobbet.
hpccred delcredsJobbet tar flera minuter att slutföra.
Hitta jobbloggen på \\Namd\namd2\namd2_hpccharmrun.log och utdatafilerna i \\Namd\namd2\namdsample\1-2-sphere.
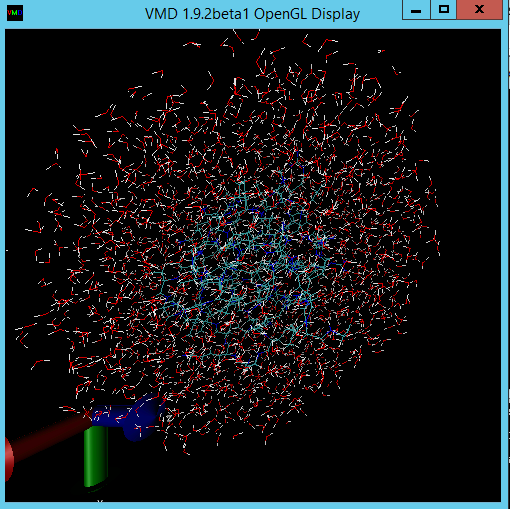
Du kan också starta VMD för att visa jobbresultatet. Stegen för att visualisera NAMD-utdatafilerna (i det här fallet en ubiquitin-proteinmolekyl i en vattensfär) ligger utanför omfattningen av den här artikeln. Mer information finns i NAMD-självstudien .
Exempelfiler
Exempel på XML-konfigurationsfil för klusterdistribution via PowerShell-skript
<?xml version="1.0" encoding="utf-8" ?>
<IaaSClusterConfig>
<Subscription>
<SubscriptionName>Subscription-1</SubscriptionName>
<StorageAccount>mystorageaccount</StorageAccount>
</Subscription>
<Location>West US</Location>
<VNet>
<VNetName>MyVNet</VNetName>
<SubnetName>Subnet-1</SubnetName>
</VNet>
<Domain>
<DCOption>HeadNodeAsDC</DCOption>
<DomainFQDN>hpclab.local</DomainFQDN>
</Domain>
<Database>
<DBOption>LocalDB</DBOption>
</Database>
<HeadNode>
<VMName>CentOS66HN</VMName>
<ServiceName>MyHPCService</ServiceName>
<VMSize>Large</VMSize>
<EnableRESTAPI />
<EnableWebPortal />
</HeadNode>
<LinuxComputeNodes>
<VMNamePattern>CentOS66LN-%00%</VMNamePattern>
<ServiceName>MyLnxCNService</ServiceName>
<VMSize>Large</VMSize>
<NodeCount>4</NodeCount>
<ImageName>5112500ae3b842c8b9c604889f8753c3__OpenLogic-CentOS-66-20150325</ImageName>
</LinuxComputeNodes>
</IaaSClusterConfig>
Exempel på cred.xml fil
<ExtendedData>
<PrivateKey>-----BEGIN RSA PRIVATE KEY-----
MIIEpQIBAAKCAQEAxJKBABhnOsE9eneGHvsjdoXKooHUxpTHI1JVunAJkVmFy8JC
qFt1pV98QCtKEHTC6kQ7tj1UT2N6nx1EY9BBHpZacnXmknpKdX4Nu0cNlSphLpru
lscKPR3XVzkTwEF00OMiNJVknq8qXJF1T3lYx3rW5EnItn6C3nQm3gQPXP0ckYCF
Jdtu/6SSgzV9kaapctLGPNp1Vjf9KeDQMrJXsQNHxnQcfiICp21NiUCiXosDqJrR
AfzePdl0XwsNngouy8t0fPlNSngZvsx+kPGh/AKakKIYS0cO9W3FmdYNW8Xehzkc
VzrtJhU8x21hXGfSC7V0ZeD7dMeTL3tQCVxCmwIDAQABAoIBAQCve8Jh3Wc6koxZ
qh43xicwhdwSGyliZisoozYZDC/ebDb/Ydq0BYIPMiDwADVMX5AqJuPPmwyLGtm6
9hu5p46aycrQ5+QA299g6DlF+PZtNbowKuvX+rRvPxagrTmupkCswjglDUEYUHPW
05wQaNoSqtzwS9Y85M/b24FfLeyxK0n8zjKFErJaHdhVxI6cxw7RdVlSmM9UHmah
wTkW8HkblbOArilAHi6SlRTNZG4gTGeDzPb7fYZo3hzJyLbcaNfJscUuqnAJ+6pT
iY6NNp1E8PQgjvHe21yv3DRoVRM4egqQvNZgUbYAMUgr30T1UoxnUXwk2vqJMfg2
Nzw0ESGRAoGBAPkfXjjGfc4HryqPkdx0kjXs0bXC3js2g4IXItK9YUFeZzf+476y
OTMQg/8DUbqd5rLv7PITIAqpGs39pkfnyohPjOe2zZzeoyaXurYIPV98hhH880uH
ZUhOxJYnlqHGxGT7p2PmmnAlmY4TSJrp12VnuiQVVVsXWOGPqHx4S4f9AoGBAMn/
vuea7hsCgwIE25MJJ55FYCJodLkioQy6aGP4NgB89Azzg527WsQ6H5xhgVMKHWyu
Q1snp+q8LyzD0i1veEvWb8EYifsMyTIPXOUTwZgzaTTCeJNHdc4gw1U22vd7OBYy
nZCU7Tn8Pe6eIMNztnVduiv+2QHuiNPgN7M73/x3AoGBAOL0IcmFgy0EsR8MBq0Z
ge4gnniBXCYDptEINNBaeVStJUnNKzwab6PGwwm6w2VI3thbXbi3lbRAlMve7fKK
B2ghWNPsJOtppKbPCek2Hnt0HUwb7qX7Zlj2cX/99uvRAjChVsDbYA0VJAxcIwQG
TxXx5pFi4g0HexCa6LrkeKMdAoGAcvRIACX7OwPC6nM5QgQDt95jRzGKu5EpdcTf
g4TNtplliblLPYhRrzokoyoaHteyxxak3ktDFCLj9eW6xoCZRQ9Tqd/9JhGwrfxw
MS19DtCzHoNNewM/135tqyD8m7pTwM4tPQqDtmwGErWKj7BaNZARUlhFxwOoemsv
R6DbZyECgYEAhjL2N3Pc+WW+8x2bbIBN3rJcMjBBIivB62AwgYZnA2D5wk5o0DKD
eesGSKS5l22ZMXJNShgzPKmv3HpH22CSVpO0sNZ6R+iG8a3oq4QkU61MT1CfGoMI
a8lxTKnZCsRXU1HexqZs+DSc+30tz50bNqLdido/l5B4EJnQP03ciO0=
-----END RSA PRIVATE KEY-----</PrivateKey>
<PublicKey>ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEkoEAGGc6wT16d4Ye+yN2hcqigdTGlMcjUlW6cAmRWYXLwkKoW3WlX3xAK0oQdMLqRDu2PVRPY3qfHURj0EEellpydeaSekp1fg27Rw2VKmEumu6Wxwo9HddXORPAQXTQ4yI0lWSerypckXVPeVjHetbkSci2foLedCbeBA9c/RyRgIUl227/pJKDNX2Rpqly0sY82nVWN/0p4NAyslexA0fGdBx+IgKnbU2JQKJeiwOomtEB/N492XRfCw2eCi7Ly3R8+U1KeBm+zH6Q8aH8ApqQohhLRw71bcWZ1g1bxd6HORxXOu0mFTzHbWFcZ9ILtXRl4Pt0x5Mve1AJXEKb username@servername;</PublicKey>
</ExtendedData>
Exempel på hpccharmrun.sh skript
#!/bin/bash
# The path of this script
SCRIPT_PATH="$( dirname "${BASH_SOURCE[0]}" )"
# Charmrun command
CHARMRUN=${SCRIPT_PATH}/charmrun
# Argument of ++nodelist
NODELIST_OPT="++nodelist"
# Argument of ++p
NUMPROCESS="+p"
# Get node information from ENVs
# CCP_NODES_CORES=3 CENTOS66LN-00 4 CENTOS66LN-01 4 CENTOS66LN-03 4
NODESCORES=(${CCP_NODES_CORES})
COUNT=${#NODESCORES[@]}
if [ ${COUNT} -eq 0 ]
then
# If CCP_NODES_CORES is not found or is empty, just run the charmrun without nodelist arg.
#echo ${CHARMRUN} $*
${CHARMRUN} $*
else
# Create the nodelist file
NODELIST_PATH=${SCRIPT_PATH}/nodelist_$$
# Write the head line
echo "group main" > ${NODELIST_PATH}
# Get every node name & cores and write into the nodelist file
I=1
while [ ${I} -lt ${COUNT} ]
do
echo "host ${NODESCORES[${I}]} ++cpus ${NODESCORES[$(($I+1))]}" >> ${NODELIST_PATH}
let "I=${I}+2"
done
# Run the charmrun with nodelist arg
#echo ${CHARMRUN} ${NUMPROCESS}${CCP_NUMCPUS} ${NODELIST_OPT} ${NODELIST_PATH} $*
${CHARMRUN} ${NUMPROCESS}${CCP_NUMCPUS} ${NODELIST_OPT} ${NODELIST_PATH} $*
RTNSTS=$?
rm -f ${NODELIST_PATH}
fi
exit ${RTNSTS}