Exempel: Skapa och distribuera en anpassad färdighet med Azure Machine Learning (arkiverad)
Det här exemplet är arkiverat och stöds inte. Den förklarade hur du skapar en anpassad färdighet med hjälp av Azure Machine Learning för att extrahera aspektbaserade sentiment från recensionerna. Detta möjliggjorde att positiva och negativa känslor inom samma recension korrekt kunde hänföras till identifierade enheter som personal, rum, lobby eller pool.
Om du vill träna den aspektbaserade attitydmodellen i Azure Machine Learning använder du lagringsplatsen nlp-recept. Modellen distribueras sedan som en slutpunkt i ett Azure Kubernetes-kluster. När slutpunkten har distribuerats läggs den till i berikande pipelinen som en AML-färdighet för användning av Cognitive Search-tjänsten.
Det finns två datauppsättningar. Om du vill träna modellen själv krävs den hotel_reviews_1000.csv filen. Föredrar du att hoppa över träningssteget? Ladda ned hotel_reviews_100.csv.
- Skapa en Azure Cognitive Search-instans
- Skapa en Azure Machine Learning-arbetsyta (söktjänsten och arbetsytan ska finnas i samma prenumeration)
- Träna och distribuera en modell till ett Azure Kubernetes-kluster
- Länka en AI-berikningspipeline till den distribuerade modellen
- Mata in utdata från distribuerad modell som en anpassad färdighet
Viktig
Den här färdigheten finns i offentlig förhandsversion under kompletterande användningsvillkor. REST API-förhandsversion stöder den här funktionen.
Förutsättningar
- Azure-prenumeration – skaffa en kostnadsfri prenumeration.
- Cognitive Search-tjänsten
- Cognitive Services-resurs
- Azure Storage-konto)
- Azure Machine Learning-arbetsyta
Inställning
- Klona eller ladda ned innehållet i exempellagringsplatsen.
- Extrahera innehåll om nedladdningen är en zip-fil. Kontrollera att filerna har läs- och skrivåtkomst.
- När du konfigurerar Azure-konton och -tjänster kopierar du namnen och nycklarna till en textfil som är enkel att komma åt. Namnen och nycklarna läggs till i den första cellen i notebook-filen där variabler för åtkomst till Azure-tjänsterna definieras.
- Om du inte känner till Azure Machine Learning och dess krav vill du granska dessa dokument innan du kommer igång:
- Konfigurera en utvecklingsmiljö för Azure Machine Learning
- Skapa och hantera Azure Machine Learning-arbetsytor i Azure-portalen
- När du konfigurerar utvecklingsmiljön för Azure Machine Learning bör du överväga att använda den molnbaserade beräkningsinstansen för att komma igång snabbt och enkelt.
- Ladda upp datamängdsfilen till en container i lagringskontot. Den större filen är nödvändig om du vill utföra träningssteget i notebook-filen. Om du föredrar att hoppa över utbildningssteget, rekommenderas den mindre filen.
Öppna notebook-filen och anslut till Azure-tjänster
- Placera all nödvändig information för variablerna som ger åtkomst till Azure-tjänsterna i den första cellen och kör cellen.
- Kör du den andra cellen, bekräftar det att du har anslutit till söktjänsten för din prenumeration.
- Avsnitten 1.1– 1.5 skapar söktjänstens datalager, kompetensuppsättning, index och indexerare.
Nu kan du välja att hoppa över stegen för att skapa träningsdatauppsättningen och experimentera i Azure Machine Learning och hoppa direkt till att registrera de två modeller som finns i mappen models på GitHub-lagringsplatsen. Om du hoppar över de här stegen kommer du i notebook-filen direkt att gå vidare till avsnitt 3.5, där du skriver bedömningsskriptet. Detta sparar tid. datahämtnings- och uppladdningsstegen kan ta upp till 30 minuter att slutföra.
Skapa och träna modellerna
Avsnitt 2 har sex celler som laddar ned handskeinbäddningsfilen från nlp-receptlagringsplatsen. Efter nedladdningen laddas filen upp till Azure Machine Learning-datalagret. Den .zip-filen är ungefär 2G och det kommer att ta lite tid att utföra dessa uppgifter. När du har laddat upp extraheras träningsdata och nu är du redo att gå vidare till avsnitt 3.
Träna den aspektbaserade attitydmodellen och distribuera slutpunkten
Avsnitt 3 i notebook-filen tränar de modeller som skapades i avsnitt 2, registrerar dessa modeller och distribuerar dem som en slutpunkt i ett Azure Kubernetes-kluster. Om du inte känner till Azure Kubernetes rekommenderar vi starkt att du läser följande artiklar innan du försöker skapa ett slutsatsdragningskluster:
- Översikt över Azure Kubernetes-tjänsten
- Kubernetes grundläggande begrepp för Azure Kubernetes Service (AKS)
- Kvoter, storleksbegränsningar för virtuella datorer och regiontillgänglighet i Azure Kubernetes Service (AKS)
Det kan ta upp till 30 minuter att skapa och distribuera slutsatsdragningsklustret. Vi rekommenderar att du testar webbtjänsten innan du går vidare till de sista stegen, uppdaterar din kompetensuppsättning och kör indexeraren.
Uppdatera kompetensen
Avsnitt 4 i notebook har fyra celler som uppdaterar färdigheterna och indexeraren. Du kan också använda portalen för att välja och tillämpa den nya kunskapen på kompetensuppsättningen och sedan köra indexeraren för att uppdatera söktjänsten.
I portalen går du till Kompetensuppsättning och väljer länken Kompetensuppsättningsdefinition (JSON). Portalen visar JSON för din kompetens som skapades i de första cellerna i notebooken. Till höger om skärmen finns en nedrullningsbara meny där du kan välja mallen för färdighetsdefinition. Välj mallen Azure Machine Learning (AML). ange namnet på Azure ML-arbetsytan och slutpunkten för modellen som distribuerats till slutsatsdragningsklustret. Mallen uppdateras med slutpunkts-URI och nyckel.
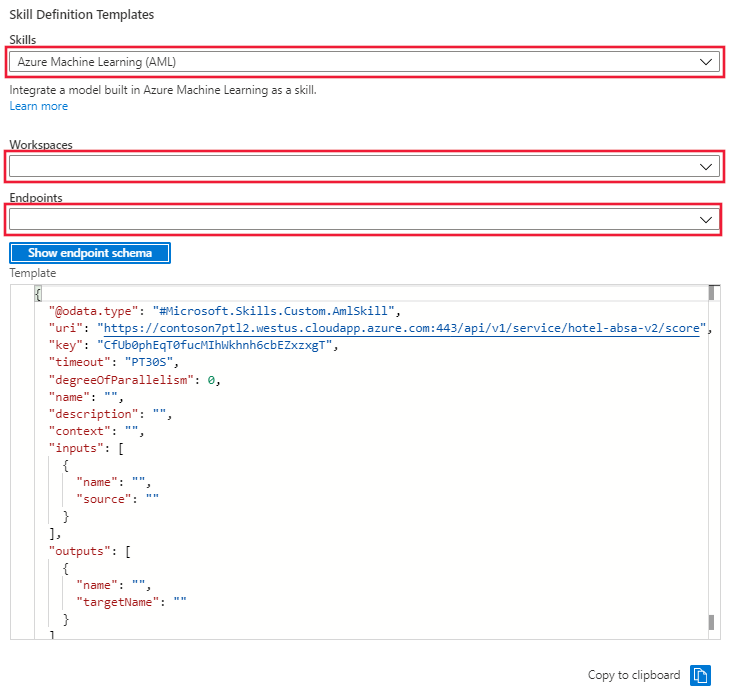
Kopiera färdighetsmallen från fönstret och klistra in den i kompetensdefinitionen till vänster. Redigera mallen för att ange saknade värden för:
- Namn
- Beskrivning
- Sammanhang
- Namn och källa för indata
- 'Utdatas' namn och målnamn
Spara kompetensen.
När du har sparat färdighetsuppsättningen går du till indexeraren och väljer länken Indexer-definition (JSON). Portalen visar JSON för indexeraren som skapades i anteckningsbokens första celler. Utdatafältmappningarna måste uppdateras med ytterligare fältmappningar för att säkerställa att indexeraren kan hantera och skicka dem korrekt. Spara ändringarna och välj sedan Kör.
Rensa resurser
När du arbetar i din egen prenumeration är det en bra idé i slutet av ett projekt att identifiera om du fortfarande behöver de resurser som du har skapat. Resurser som lämnas igång kan kosta dig pengar. Du kan ta bort resurser individuellt eller ta bort resursgruppen för att ta bort hela uppsättningen resurser.
Du kan hitta och hantera resurser i portalen med hjälp av länken Alla resurser eller Resursgrupper länk i det vänstra navigeringsfönstret.
Om du använder en kostnadsfri tjänst bör du komma ihåg att du är begränsad till tre index, indexerare och datakällor. Du kan ta bort enskilda objekt i portalen för att hålla dig under gränsen.