Bibliotekshantering i Spark
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer med det här tillkännagivandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS förhandsversionsinformation. För frågor eller funktionsförslag, skicka en begäran på AskHDInsight med detaljerna och följ oss för fler uppdateringar om Azure HDInsight Community.
Syftet med bibliotekshantering är att göra öppen källkod eller anpassad kod tillgänglig för notebook-filer och jobb som körs i dina kluster. Du kan ladda upp Python-bibliotek från PyPI-lagringsplatser. Den här artikeln fokuserar på att hantera bibliotek i klustrets användargränssnitt. Azure HDInsight på AKS innehåller redan många vanliga bibliotek i klustret. Om du vill se vilka bibliotek som ingår i HDI i AKS-klustret läser du sidan för bibliotekshantering.
Installera bibliotek
Du kan installera bibliotek i två lägen:
- Klusterinstallerat
- Notebook-avgränsad
Kluster installerat
Alla notebook-filer som körs i ett kluster kan använda klusterbibliotek. Du kan installera ett klusterbibliotek direkt från en offentlig lagringsplats, till exempel PyPi. Möjligheten att ladda upp från Maven-lagringsplatser och ladda upp anpassade bibliotek från molnlagring finns med på färdplanen.

Notebook-omfång
Bibliotek med notebook-omfång som är tillgängliga för Python och Scala, som gör att du kan installera bibliotek och skapa en miljö som är begränsad till en notebook-session. De här biblioteken påverkar inte andra notebook-filer som körs i samma kluster. Bibliotek som är knutna till en notebook sparas inte och måste installeras om för varje session.
Not
Använd bibliotek med notebook-omfattning när du behöver en anpassad miljö för en specifik anteckningsbok.
Sätt för biblioteksinstallation
PyPI-: Hämta bibliotek från PyPI-lagringsplatsen med öppen källkod genom att nämna biblioteksnamnet och versionen i installationsgränssnittet.
Visa de installerade biblioteken
Från översiktssidan går du till Bibliotekshanteraren.
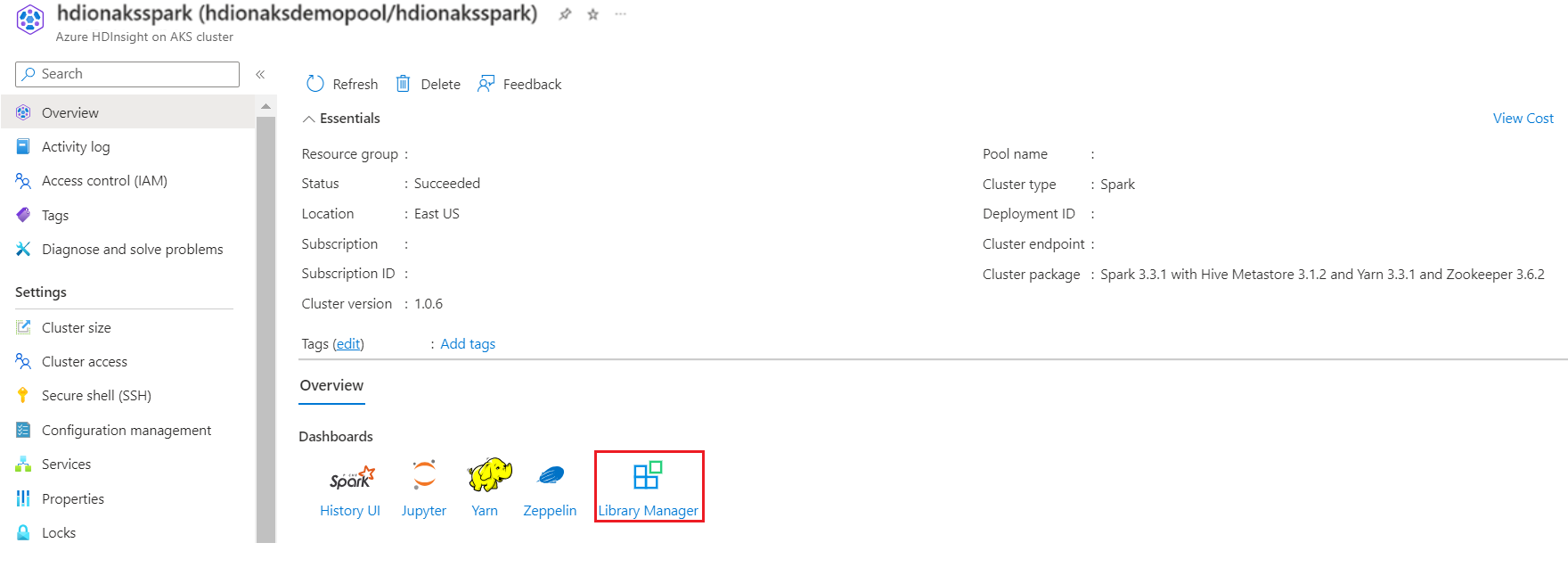
Från Spark Cluster Manager klickar du på Bibliotekshanteraren.
Du kan visa listan över installerade bibliotek härifrån.



Lägg till bibliotekswidget
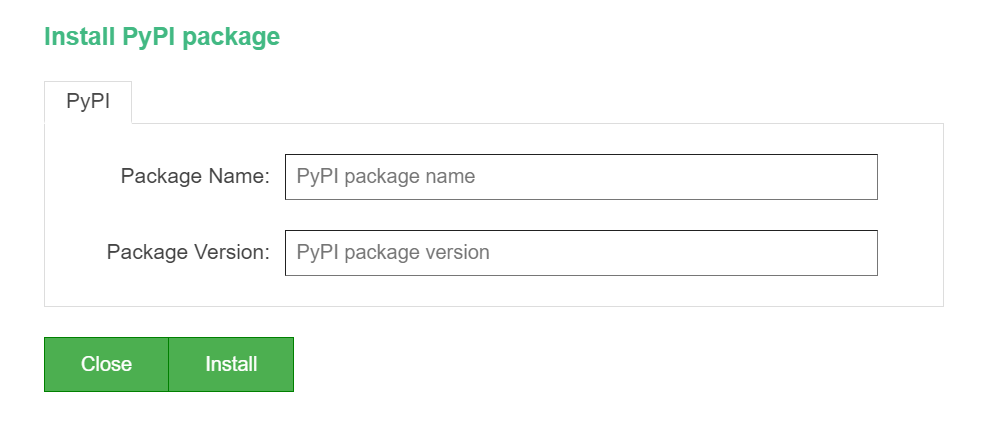
PyPI
På fliken PyPI anger du paketnamn och paketversion..
Klicka på Installera.
Avinstallera bibliotek
Om du bestämmer dig för att inte längre använda biblioteken kan du enkelt ta bort bibliotekspaketen via avinstallationsknappen på bibliotekshanteringssidan.
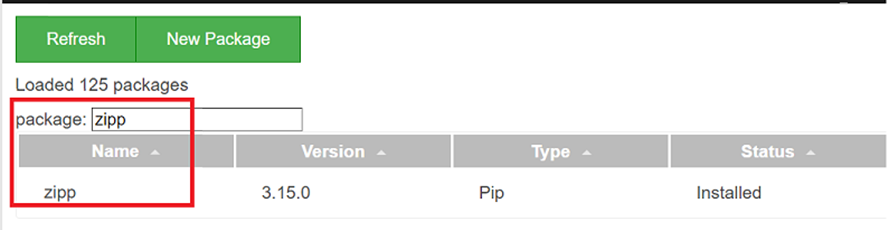
Välj och klicka på biblioteksnamnet
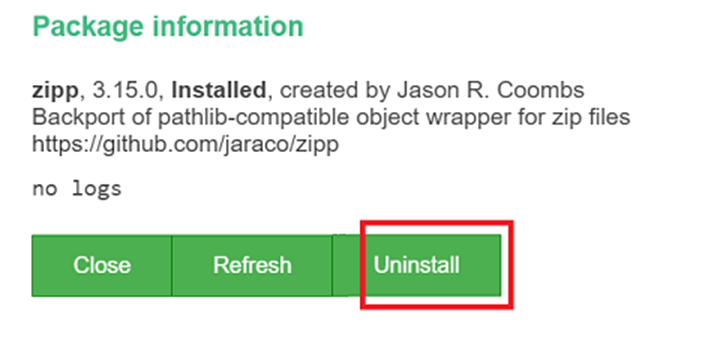
Klicka på Avinstallera i widgeten
Not
- Paket som är installerade från Jupyter Notebook kan bara tas bort från Jupyter Notebook.
- Paket som installeras från bibliotekshanteraren kan bara avinstalleras från bibliotekshanteraren.
- Om du vill uppgradera ett bibliotek/paket avinstallerar du den aktuella versionen av biblioteket och installerar om den nödvändiga versionen av biblioteket.
- Installation av bibliotek från Jupyter Notebook är specifik för sessionen. Det är inte beständigt.
- Det kan ta lite tid att installera tunga paket på grund av deras storlek och komplexitet.