Använda Delta Lake i Azure HDInsight på AKS med Apache Spark-kluster™ (förhandsversion)
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer med det här meddelandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt som ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. För frågor eller funktionsförslag, skicka en förfrågan till AskHDInsight- med detaljerna och följ oss för fler uppdateringar om Azure HDInsight Community.
Azure HDInsight på AKS är en hanterad molnbaserad tjänst för stordataanalys som hjälper organisationer att bearbeta stora mängder data. Den här handledningen visar användning av Delta Lake i Azure HDInsight på AKS med Apache Spark™-kluster.
Förutsättning
Skapa ett Apache Spark-kluster™ i Azure HDInsight på AKS
Kör Delta Lake-scenariot i Jupyter Notebook. Skapa en Jupyter-anteckningsbok och välj "Spark" när du skapar en notebook-fil, eftersom följande exempel finns i Scala.


Scenario
- Läs NYC Taxi Parquet Data-format - Lista över Parquet-filernas URL:er tillhandahålls från NYC Taxi & Limousine kommissionen.
- ** För varje URL (fil) utför en transformering och lagra i Delta-format.
- Beräkna genomsnittligt avstånd, genomsnittlig kostnad per mil och genomsnittlig kostnad från Delta Table med inkrementell belastning.
- Lagra beräknat värde från steg 3 i Delta-format i mappen KPI-utdata.
- Skapa Delta Table i utdatamappen Delta Format (automatisk uppdatering).
- KPI-utdatamappen har flera versioner av det genomsnittliga avståndet och den genomsnittliga kostnaden per mil för en resa.
Ange kräv konfigurationer för Delta Lake
Delta Lake med Apache Spark-kompatibilitetsmatris – Delta Lake, ändra Delta Lake-versionen baserat på Apache Spark-version.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Visa en lista över datafilen
Observera
Dessa fil-URL:er kommer från NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Skapa utdatakatalog
Den plats där du vill skapa deltaformatutdata, ändra variabeln transformDeltaOutputPath och avgDeltaOutputKPIPath om det behövs.
-
avgDeltaOutputKPIPath– för att lagra genomsnittlig KPI i deltaformat -
transformDeltaOutputPath– lagra transformerade utdata i deltaformat
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Skapa deltaformatdata från ett Parquet-format
Indata kommer från
listOfDataFile, och data som laddats ned från https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page är inkluderade.Om du vill demonstrera tidsresa och version läser du in data individuellt
Utför transformering och beräkning efter affärs-KPI vid inkrementell belastning:
- Genomsnittligt avstånd
- Den genomsnittliga kostnaden per mil
- Den genomsnittliga kostnaden
Spara transformerade data och KPI-data i deltaformat
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Läs deltaformat med deltatabell
- läsa transformerade data
- Läs KPI-data
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Utskriftsschema
- Skriv ut deltatabellschema för transformerade och genomsnittliga KPI-data1.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema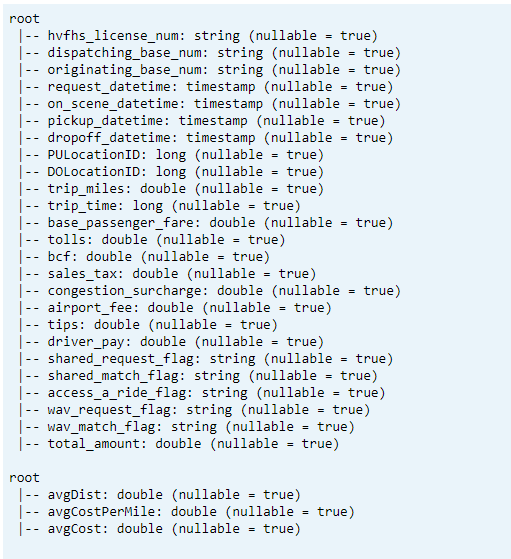
Visa senast beräknad KPI från datatabell
dtAvgKpi.toDF.show(false)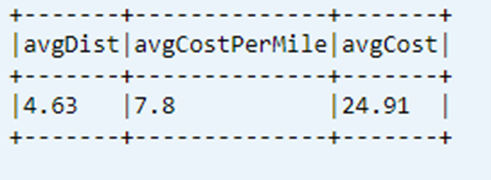


Visa beräknad KPI-historik
Det här steget visar historiken för KPI-transaktionstabellen från _delta_log
dtAvgKpi.history().show(false)

Visa KPI-data efter varje datainläsning
- Med tidsresor kan du visa KPI-ändringar efter varje inläsning
- Du kan lagra alla versionsändringar i CSV-format på
avgMoMKPIChangePath, så att Power BI kan läsa dessa ändringar
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Hänvisning
- Apache, Apache Spark, Spark och associerade projektnamn med öppen källkod är varumärken av Apache Software Foundation (ASF).