Hur du använder Azure Pipelines med Apache Flink® i HDInsight på AKS
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer genom det här meddelandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i beta, förhands- eller på annat sätt ännu inte släppta i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight i AKS-förhandsversionsinformationen. För frågor eller funktionsförslag, skicka en begäran till AskHDInsight med detaljerna och följ oss för fler uppdateringar om Azure HDInsight Community.
I den här artikeln får du lära dig hur du använder Azure Pipelines med HDInsight på AKS för att skicka Flink-jobb med klustrets REST API. Vi vägleder dig genom processen med hjälp av en YAML-exempelpipeline och ett PowerShell-skript, som båda effektiviserar automatiseringen av REST API-interaktionerna.
Förutsättningar
Azure-prenumeration. Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto.
Ett GitHub-konto där du kan skapa en lagringsplats. Skapa en kostnadsfri version.
Skapa
.pipelinekatalog, kopiera flink-azure-pipelines.yml och flink-job-azure-pipeline.ps1Azure DevOps-organisation. Skapa en kostnadsfritt. Om ditt team redan har ett kontrollerar du att du är administratör för det Azure DevOps-projekt som du vill använda.
Möjlighet att köra pipelines på agenter hostade av Microsoft. För att använda agenter som är värdbaserade av Microsoft måste din Azure DevOps-organisation ha åtkomst till parallella jobb som är värdbaserade av Microsoft. Du kan antingen köpa ett parallellt jobb eller begära ett kostnadsfritt bidrag.
Ett Flink-kluster. Om du inte har ett, skapa ett Flink-kluster i HDInsight på AKS.
Skapa en katalog i klusterlagringskontot för att kopiera jobbburken. Du måste senare konfigurera den här katalogen i pipeline-YAML för platsen för jobbfiler (<JOB_JAR_STORAGE_PATH>).
Steg för att konfigurera en pipeline
Skapa ett huvudnamn för tjänsten för Azure Pipelines
Skapa Microsoft Entra service principal för att få åtkomst till Azure – Bevilja behörighet att komma åt HDInsight i AKS-kluster med Contributor-rollen, anteckna appId, lösenord och klientorganisation från svaret.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Exempel:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Hänvisning
Not
Apache, Apache Flink, Flink och associerade projektnamn med öppen källkod är varumärken av Apache Software Foundation (ASF).
Skapa ett nyckelvalv
Skapa Azure Key Vault. Du kan följa den här guiden för att skapa ett nytt Azure Key Vault.
Skapa tre hemligheter
klusterlagringsnyckel för lagringsnyckel.
service-principal-key för principal clientId eller appId.
service-principal-secret för huvudhemlighet.
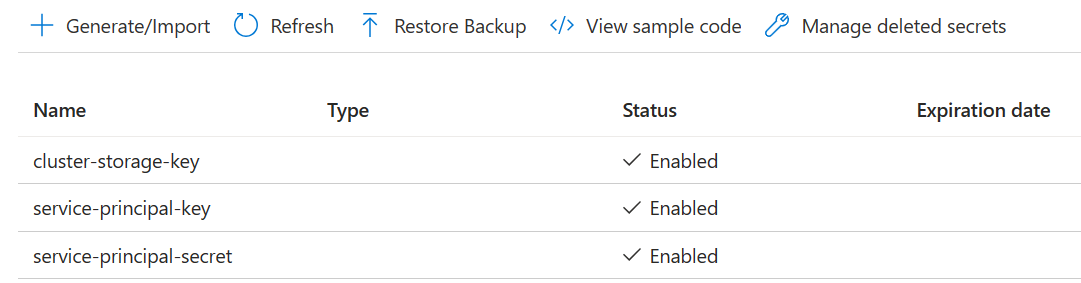
Bevilja behörighet att få åtkomst till Azure Key Vault med rollen "Key Vault Secrets Officer" till tjänstens huvudkonto.

Installationspipeline
Gå till projektet och klicka på Projektinställningar.
Rulla nedåt och välj Tjänstanslutningar och sedan Ny tjänstanslutning.
Välj Azure Resource Manager.
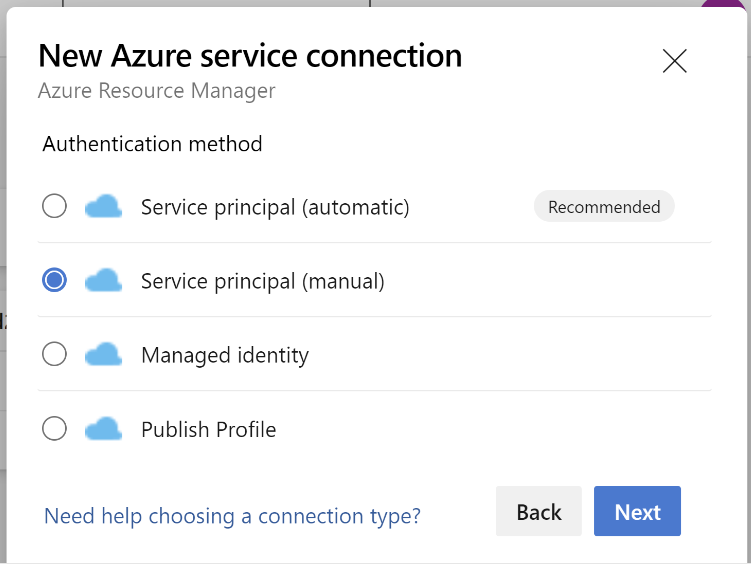
I autentiseringsmetoden väljer du Tjänstens huvudnamn (manuell).

Redigera tjänstanslutningsegenskaperna. Välj tjänstens huvudnamn som du nyligen skapade.
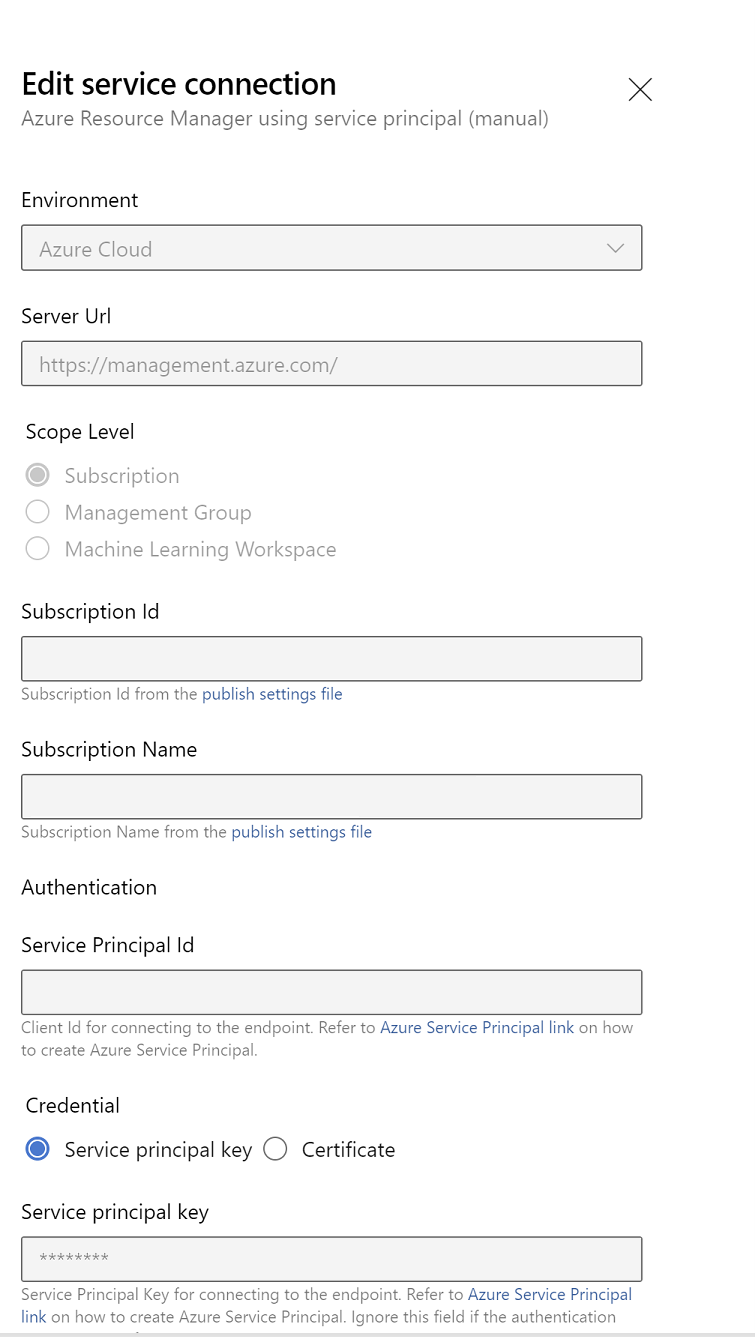
Klicka på Verifiera för att kontrollera om anslutningen har konfigurerats korrekt. Om du får följande fel:

Sedan måste du tilldela rollen Läsare till prenumerationen.
Därefter bör verifieringen lyckas.
Spara tjänstanslutningen.

Navigera till pipelines och klicka på Ny Pipeline.

Välj GitHub som plats för koden.
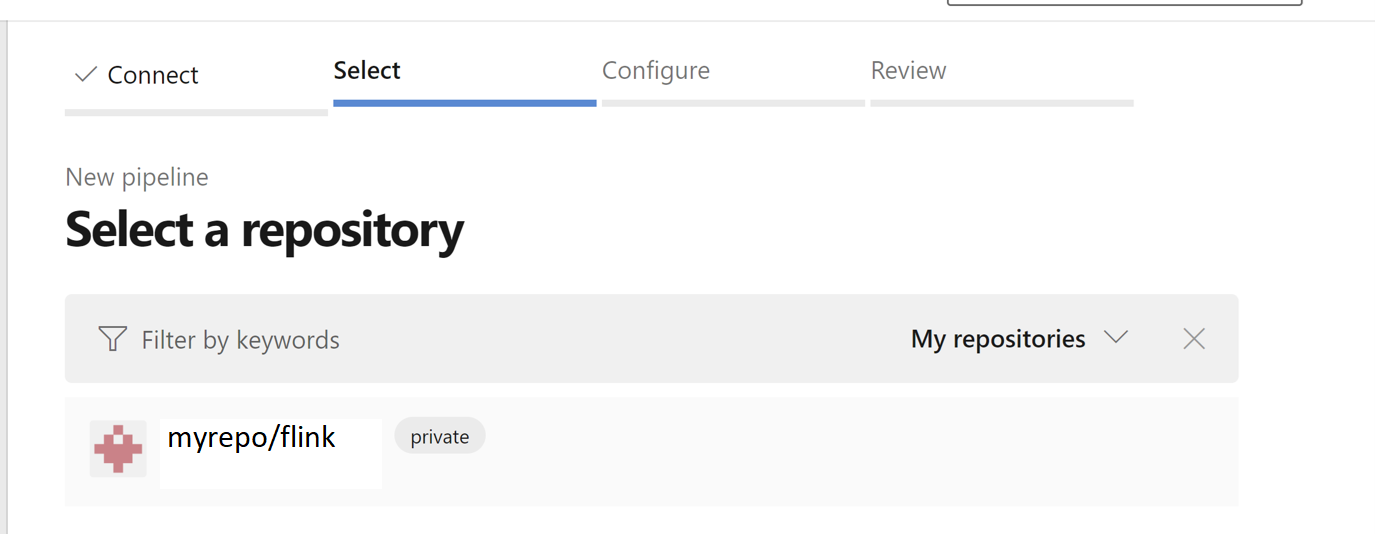
Välj lagringsplatsen. Se hur du skapar en lagringsplats i GitHub. välj-github-repo-bild
Välj lagringsplatsen. Mer information finns i Skapa en lagringsplats i GitHub.
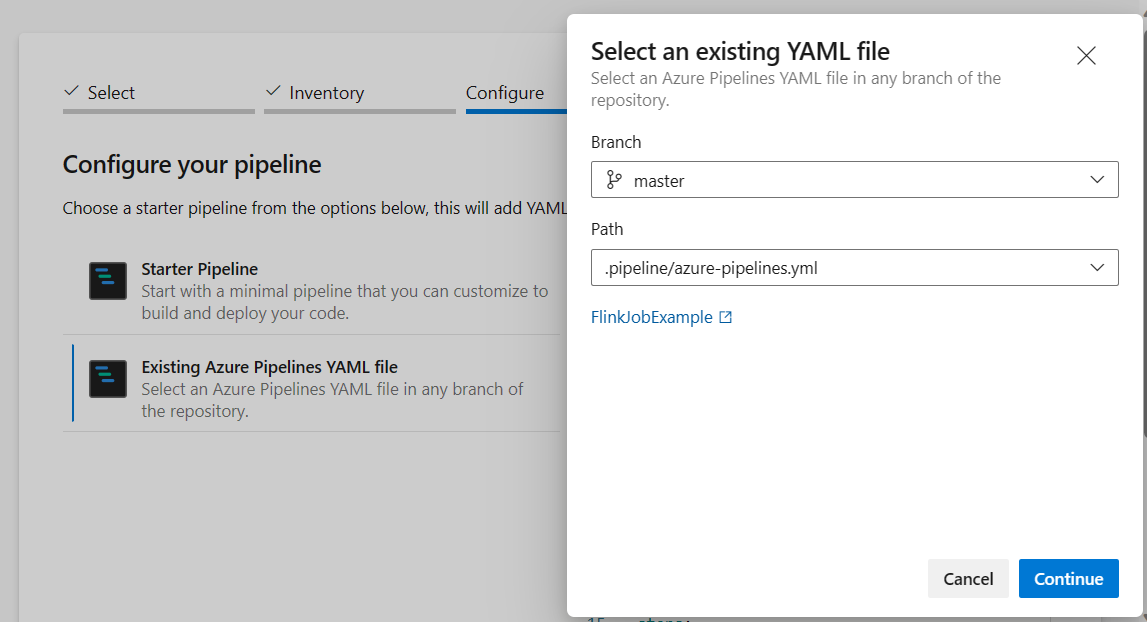
Från alternativet för att konfigurera din pipeline kan du välja befintlig Azure Pipelines YAML-fil. Välj gren- och pipelineskript som du kopierade tidigare. (.pipeline/flink-azure-pipelines.yml)
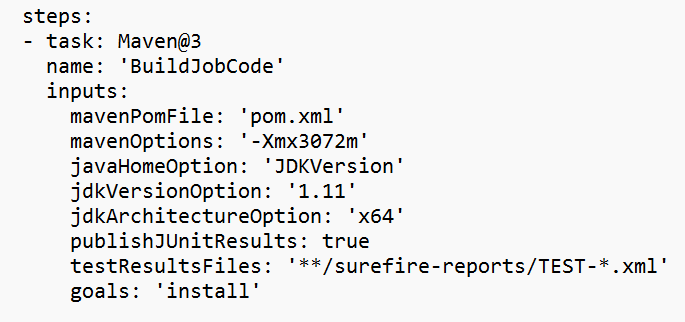
Ersätt värdet i variabelavsnittet.

Korrigera byggsektionen för koden baserat på dina krav och konfigurera <JOB_JAR_LOCAL_PATH> i variabelavsnittet för den lokala sökvägen till job jar.
Lägg till pipelinevariabeln "action" och konfigurera värdet "RUN".
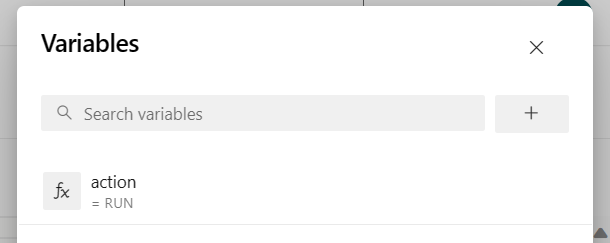
du kan ändra värdena för variabeln innan du kör pipelinen.
NYTT: Det här värdet är standard. Det startar ett nytt jobb och om jobbet redan körs uppdaterar det jobb som körs med den senaste jar-filen.
SAVEPOINT: Det här värdet anger en återställningspunkt för det körande jobbet.
TA BORT: Avbryt eller ta bort det pågående jobbet.
Spara och kör pipelinen. Du kan se jobbet som körs på Portalen i Flink-jobbsavsnittet.








Not
Det här är ett exempel för att skicka uppgiften genom en pipeline. Du kan följa dokumentationen för Flink REST API för att skriva din egen kod för att skicka in ett jobb.