Migrera från Batch AI till Azure Machine Learning Service
Azure Batch AI-tjänsten tas ur bruk i mars. De skalenliga tränings- och bedömningsfunktionerna i Batch AI är nu tillgängliga i Azure Machine Learning Services, som blev allmänt tillgänglig den 4 december 2018.
Tillsammans med många andra funktioner för maskininlärning innehåller Azure Machine Learning-tjänsten ett molnbaserat hanterat beräkningsmål för att träna, distribuera och bedöms maskininlärningsmodeller. Den här beräkningsmålet kallas för Azure Machine Learning Compute. Börja migrera och använda det idag. Du kan interagera med Azure Machine Learning-tjänsten via dess Python SDK: er, kommandoradsgränssnitt och Azure Portal.
Genom att uppgradera från Förhandsversion av Batch AI till GA'ed Azure Machine Learning-tjänsten får du en bättre upplevelse genom begrepp som är enklare att använda, till exempel skattare och datalager. Du har även garanterad kundsupport och SLA:er på GA-nivå för Azure-tjänsten.
Azure Machine Learning-tjänsten innehåller även nya funktioner som automatiserad maskininlärning, hyperparameterjustering och ML-pipelines, som är användbara i de flesta storskaliga AI-arbetsbelastningar. Möjligheten att distribuera en tränad modell utan att växla till en separat tjänst hjälper till att slutföra data science-loopen från dataförberedelse (med dataförberedelse-SDK) hela vägen till driftsättning och modellövervakning.
Börja migrera
Att undvika avbrott i dina program och dra nytta av de senaste funktionerna ska du göra följande innan 31 mars 2019:
Skapa en Azure Machine Learning-tjänstarbetsyta och kom igång:
Installera Azure Machine Learning SDK och SDK för dataförberedelse.
Konfigurera en Azure Machine Learning Compute för att träna modellen.
Uppdatera dina skript så att de använder Azure Machine Learning Compute. Följande avsnitt visar hur vanlig kod du använder för Batch AI-kartor för att koda för Azure Machine Learning.
Skapa arbetsytor
Konceptet att initiera en arbetsyta med hjälp av en configuration.json i Azure Batch AI mappar på samma sätt som med hjälp av en konfigurationsfil i Azure Machine Learning-tjänsten.
I Batch AI gjorde du på det här sättet:
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
Azure Machine Learning Service försöker du att:
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
Du kan dessutom också skapa en arbetsyta direkt genom att ange konfigurationsparametrar som
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
Läs mer om klassen Azure Machine Learning Workspace i SDK-referensdokumentationen.
Skapa beräkningskluster
Azure Machine Learning har stöd för flera beräkningsmål, varav vissa hanteras av tjänsten och andra kan kopplas till din arbetsyta (t.ex. Ett HDInsight-kluster eller en fjärransluten virtuell dator. Läs mer om olika beräkningsmål. Konceptet att skapa ett Azure Batch AI-beräkningskluster mappar till att skapa ett AmlCompute-kluster i Azure Machine Learning-tjänsten. Skapandet av Amlcompute tar in en beräkningskonfiguration som liknar hur du skickar parametrar i Azure Batch AI. En sak att tänka på är att autoskalning är aktiverat som standard på ditt AmlCompute-kluster medan det är inaktiverat som standard i Azure Batch AI.
I Batch AI gjorde du på det här sättet:
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
I Azure Machine Learning Service försöker du att:
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Mer information om klassen för AMLCompute finns i SDK-referensdokumentationen. Observera att i konfigurationen ovan är endast vm_size och max_nodes obligatoriska. Resten av egenskaperna (t.ex. virtuella nätverk) används endast vid avancerad klusterkonfiguration.
Övervaka status för klustret
Det här är enklare i Azure Machine Learning-tjänsten som du ser nedan.
I Batch AI gjorde du på det här sättet:
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
I Azure Machine Learning Service försöker du att:
gpu_cluster.get_status().serialize()
Hämta referens till ett lagringskonto
Begreppet datalagring, till exempel blob, förenklas i Azure Machine Learning-tjänsten med hjälp av DataStore-objektet. Som standard skapar din Azure Machine Learning-tjänstarbetsyta ett lagringskonto, men du kan även koppla din egen lagring som en del av skapandet av arbetsytan.
I Batch AI gjorde du på det här sättet:
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
I Azure Machine Learning Service försöker du att:
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Läs mer om att registrera ytterligare lagringskonton eller hämta en referens till ett annat registrerat datalager i dokumentationen för Azure Machine Learning-tjänsten.
Ladda ned och ladda upp data
Du kan använda någon av tjänsterna till att ladda upp data till lagringskontot på ett enkelt sätt med datalagerreferensen ovan. För Azure Batch AI distribuerar vi även träningsskriptet som en del av fildelningen, även om du ser hur du kan ange det som en del av jobbkonfigurationen när det gäller Azure Machine Learning-tjänsten.
I Batch AI gjorde du på det här sättet:
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
I Azure Machine Learning Service försöker du att:
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
Skapa experiment
Som nämnts ovan har Azure Machine Learning-tjänsten ett koncept för ett experiment som liknar Azure Batch AI. Varje experiment kan sedan ha enskilda körningar, ungefär som vi har jobb i Azure Batch AI. Med Azure Machine Learning-tjänsten kan du också ha hierarki under varje överordnad körning för enskilda underordnade körningar.
I Batch AI gjorde du på det här sättet:
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
I Azure Machine Learning Service försöker du att:
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
Skicka jobb
När du skapar ett experiment finns det några olika sätt att skicka en körning på. I det här exemplet försöker vi skapa en djupinlärningsmodell med TensorFlow och använder en Azure Machine Learning-tjänstberäknare för att göra det. En beräkning är helt enkelt en omslutningsfunktion i den underliggande körningskonfigurationen, vilket gör det enklare att skicka körningar. Detta stöds för närvarande endast för Pytorch och TensorFlow. Via begreppet med datalager kan du även se hur enkelt det blir att ange monteringssökvägarna
I Batch AI gjorde du på det här sättet:
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
Att skicka själva jobbet i Azure Batch AI sker via create-funktionen.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
Den fullständiga informationen för det här kodfragmentet för träning (inklusive filen mnist_replica.py som vi hade laddat upp till filresursen ovan) finns i github-lagringsplatsen för Azure Batch AI-exempelanteckningsboken.
I Azure Machine Learning Service försöker du att:
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
Den fullständiga informationen för det här träningskodfragmentet (inklusive filen tf_mnist_replica.py) finns i Azure Machine Learning-tjänstens github-lagringsplats för exempel på notebook-filer. Datalagringen kan antingen monteras på enskilda noder eller så kan träningsdata hämtas från själva noden. Mer information om hur du refererar till datalagringen i uppskattningen finns i dokumentationen för Azure Machine Learning-tjänsten.
Att skicka en körning i Azure Machine Learning-tjänsten sker via funktionen submit.
run = experiment.submit(estimator)
print(run)
Det finns ett annat sätt att ange parametrar för din körning med en körningskonfiguration – vilket är särskilt användbart när en anpassad träningsmiljö ska definieras. Du hittar mer information i det här exemplet på en AmlCompute-anteckningsbok.
Övervaka körningar
När du har skickat en körning kan du antingen vänta tills den har slutförts eller övervaka den i Azure Machine Learning-tjänsten med hjälp av snygga Jupyter-widgetar som du kan anropa direkt från koden. Du kan också hämta kontexten för en tidigare körning genom att göra en loop genom olika experiment i en arbetsyta och genom enskilda körningar inom varje experiment.
I Batch AI gjorde du på det här sättet:
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
I Azure Machine Learning Service försöker du att:
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
Här är en ögonblicksbild av hur widgeten skulle läsas in i anteckningsboken för att titta på dina loggar i realtid: 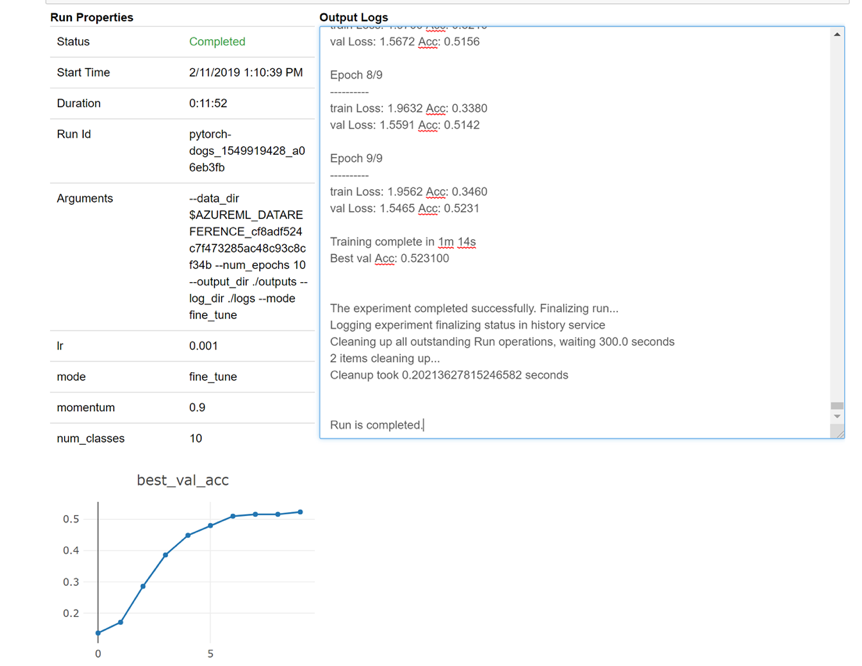
Redigera kluster
Det är enkelt att ta bort ett kluster. Dessutom kan du med Azure Machine Learning-tjänsten uppdatera ett kluster inifrån notebook-filen om du vill skala det till ett högre antal noder eller öka väntetiden för inaktivitet innan klustret skalas ned. Du kan inte ändra VM-storleken för själva klustret, eftersom det kräver en ny distribution i serverdelen.
I Batch AI gjorde du på det här sättet:
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
I Azure Machine Learning Service försöker du att:
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
Få support
Batch AI är tänkt att dra sig tillbaka den 31 mars och blockerar redan nya prenumerationer från att registreras mot tjänsten om den inte tillåts genom att skapa ett undantag via support. Kontakta oss på Förhandsversionen av Azure Batch AI-träningen om du har frågor eller feedback när du migrerar till Azure Machine Learning Service.
Microsoft Azure Machine Learning Service är nu allmänt tillgänglig. Det innebär att den innehåller ett dedikerat serviceavtal och olika supportplaner att välja bland.
Prissättningen för att använda Azure-infrastruktur antingen via Azure Batch AI-tjänsten eller via Azure Machine Learning-tjänsten bör inte variera, eftersom vi bara debiterar priset för den underliggande beräkningen i båda fallen. Mer information finns på sidan med priskalkylatorn.
Visa regional tillgänglighet mellan de två tjänsterna i Azure-portalen.
Nästa steg
Konfigurera ett beräkningsmål för modellträning med Azure Machine Learning-tjänsten.
Granska Azure-översikten för att lära dig av andra Azure-tjänstuppdateringar.