Lösning för övervakare av nätverksprestanda: Prestandaövervakning
Viktigt
Från och med den 1 juli 2021 kan du inte lägga till nya tester på en befintlig arbetsyta eller aktivera en ny arbetsyta i Övervakaren för nätverksprestanda. Du kan fortsätta att använda testerna som skapats före den 1 juli 2021. För att minimera tjänststörningar i dina aktuella arbetsbelastningar migrerar du dina tester från Övervakaren av nätverksprestanda till den nya Anslutningsövervakare i Azure Network Watcher före den 29 februari 2024.
Funktionen Prestandaövervakare i Övervakare av nätverksprestanda hjälper dig att övervaka nätverksanslutningar mellan olika punkter i nätverket. Du kan övervaka molndistributioner och lokala platser, flera datacenter och avdelningskontor och verksamhetskritiska program eller mikrotjänster på flera nivåer. Med Prestandaövervakaren kan du identifiera nätverksproblem innan användarna klagar. Viktiga fördelar är att du kan:
- Övervaka förlust och svarstid i olika undernät och ange aviseringar.
- Övervaka alla sökvägar (inklusive redundanta sökvägar) i nätverket.
- Felsöka tillfälliga och tidpunktsbaserade nätverksproblem som är svåra att replikera.
- Fastställ det specifika segmentet i nätverket, som ansvarar för försämrad prestanda.
- Övervaka nätverkets hälsa, utan att behöva SNMP.

Konfiguration
Öppna konfigurationen för Övervakare av nätverksprestanda genom att öppna lösningen Övervakare av nätverksprestanda och välja Konfigurera.
Skapa nya nätverk
Ett nätverk i Övervakare av nätverksprestanda är en logisk container för undernät. Det hjälper dig att organisera övervakningen av din nätverksinfrastruktur efter dina behov. Du kan skapa ett nätverk med ett eget namn och lägga till undernät i det enligt din affärslogik. Du kan till exempel skapa ett nätverk med namnet London och lägga till alla undernät i ditt datacenter i London. Eller så kan du skapa ett nätverk med namnet ContosoFrontEnd och lägga till alla undernät med namnet Contoso som betjänar appens klientdel i det här nätverket. Lösningen skapar automatiskt ett standardnätverk som innehåller alla undernät som identifieras i din miljö.
När du skapar ett nätverk lägger du till ett undernät i det. Sedan tas det undernätet bort från standardnätverket. Om du tar bort ett nätverk returneras alla dess undernät automatiskt till standardnätverket. Standardnätverket fungerar som en container för alla undernät som inte finns i något användardefinierat nätverk. Du kan inte redigera eller ta bort standardnätverket. Det finns alltid kvar i systemet. Du kan skapa så många anpassade nätverk som du behöver. I de flesta fall är undernäten i din organisation ordnade i fler än ett nätverk. Skapa ett eller flera nätverk för att gruppera dina undernät för din affärslogik.
Så här skapar du ett nytt nätverk:
- Välj fliken Nätverk .
- Välj Lägg till nätverk och ange sedan nätverksnamnet och beskrivningen.
- Välj ett eller flera undernät och välj sedan Lägg till.
- Välj Spara för att spara konfigurationen.
Skapa övervakningsregler
Prestandaövervakaren genererar hälsohändelser när tröskelvärdet för prestanda för nätverksanslutningar mellan två undernät eller mellan två nätverk överskrids. Systemet kan lära sig dessa tröskelvärden automatiskt. Du kan också ange anpassade tröskelvärden. Systemet skapar automatiskt en standardregel som genererar en hälsohändelse när förlust eller svarstid mellan nätverk eller undernätslänkar överskrider tröskelvärdet för systeminlärning. Den här processen hjälper lösningen att övervaka nätverksinfrastrukturen tills du inte uttryckligen har skapat några övervakningsregler. Om standardregeln är aktiverad skickar alla noder syntetiska transaktioner till alla andra noder som du har aktiverat för övervakning. Standardregeln är användbar med små nätverk. Ett exempel är ett scenario där du har ett litet antal servrar som kör en mikrotjänst och du vill se till att alla servrar har anslutning till varandra.
Anteckning
Vi rekommenderar att du inaktiverar standardregeln och skapar anpassade övervakningsregler, särskilt med stora nätverk där du använder ett stort antal noder för övervakning. Anpassade övervakningsregler kan minska den trafik som genereras av lösningen och hjälpa dig att organisera övervakningen av nätverket.
Skapa övervakningsregler enligt din affärslogik. Ett exempel är om du vill övervaka prestandan för nätverksanslutningen mellan två kontorsplatser till huvudkontoret. Gruppera alla undernät på office site1 i nätverket O1. Gruppera sedan alla undernät på office site2 i nätverket O2. Gruppera slutligen alla undernät i huvudkontoret i nätverk H. Skapa två övervakningsregler – en mellan O1 och H och den andra mellan O2 och H.
Så här skapar du anpassade övervakningsregler:
- Välj Lägg till regel på fliken Övervaka och ange regelnamnet och beskrivningen.
- Välj det par med nätverks- eller undernätslänkar som ska övervakas från listorna.
- Välj det nätverk som innehåller de undernät du vill använda i listrutan nätverk. Välj sedan undernäten från motsvarande undernätslistruta. Om du vill övervaka alla undernät i en nätverkslänk väljer du Alla undernät. På samma sätt väljer du de andra undernäten som du vill använda. Om du vill exkludera övervakning för vissa undernätslänkar från de val du har gjort väljer du Lägg till undantag.
- Välj mellan ICMP- och TCP-protokoll för att köra syntetiska transaktioner.
- Om du inte vill skapa hälsohändelser för de objekt som du har valt avmarkerar du Aktivera hälsoövervakning på länkarna som omfattas av den här regeln.
- Välj övervakningsvillkor. Om du vill ange anpassade tröskelvärden för generering av hälsohändelser anger du tröskelvärden. När värdet för villkoret överskrider det valda tröskelvärdet för det valda nätverket eller undernätsparet genereras en hälsohändelse.
- Välj Spara för att spara konfigurationen.
När du har sparat en övervakningsregel kan du integrera regeln med Aviseringshantering genom att välja Skapa avisering. En aviseringsregel skapas automatiskt med sökfrågan. Andra obligatoriska parametrar fylls i automatiskt. Med hjälp av en aviseringsregel kan du ta emot e-postbaserade aviseringar, förutom de befintliga aviseringarna i Övervakaren för nätverksprestanda. Aviseringar kan också utlösa åtgärdsåtgärder med runbooks, eller så kan de integreras med befintliga Service Management-lösningar med hjälp av webhooks. Välj Hantera avisering för att redigera aviseringsinställningarna.
Nu kan du skapa fler regler för prestandaövervakaren eller gå till instrumentpanelen för lösningen för att använda funktionen.
Välj protokoll
Övervakaren för nätverksprestanda använder syntetiska transaktioner för att beräkna nätverksprestandamått som paketförlust och länkfördröjning. Om du vill förstå det här konceptet bättre kan du överväga en agent för övervakare av nätverksprestanda som är ansluten till ena änden av en nätverkslänk. Den här network performance monitor-agenten skickar avsökningspaket till en andra network performance monitor-agent som är ansluten till en annan ände av nätverket. Den andra agenten svarar med svarspaket. Den här processen upprepas några gånger. Genom att mäta antalet svar och den tid det tar att ta emot varje svar utvärderar den första network performance monitor-agenten länkfördröjning och paketförluster.
Formatet, storleken och sekvensen för dessa paket bestäms av det protokoll som du väljer när du skapar övervakningsregler. Baserat på protokollet för paketen kan mellanliggande nätverksenheter, till exempel routrar och växlar, bearbeta dessa paket på olika sätt. Därför påverkar ditt protokollval resultatets noggrannhet. Ditt protokollval avgör också om du måste vidta några manuella åtgärder när du har distribuerat lösningen Övervakare av nätverksprestanda.
Övervakaren för nätverksprestanda ger dig möjlighet att välja mellan ICMP- och TCP-protokoll för körning av syntetiska transaktioner. Om du väljer ICMP när du skapar en syntetisk transaktionsregel använder network performance monitor-agenterna ICMP ECHO-meddelanden för att beräkna nätverksfördröjningen och paketförlusten. ICMP ECHO använder samma meddelande som skickas av det konventionella pingverktyget. När du använder TCP som protokoll skickar network performance monitor-agenter TCP SYN-paket via nätverket. Det här steget följs av en TCP-handskakning och anslutningen tas bort med hjälp av RST-paket.
Överväg följande information innan du väljer ett protokoll:
Identifiering av flera nätverksvägar. TCP är mer exakt när du identifierar flera vägar och behöver färre agenter i varje undernät. Till exempel kan en eller två agenter som använder TCP identifiera alla redundanta sökvägar mellan undernät. Du behöver flera agenter som använder ICMP för att uppnå liknande resultat. Om du använder ICMP behöver du fler än 5N-agenter i antingen ett käll- eller målundernät om du har ett antal vägar mellan två undernät.
Resultatprecision. Routrar och växlar brukar tilldela lägre prioritet till ICMP ECHO-paket jämfört med TCP-paket. I vissa situationer, när nätverksenheter är kraftigt inlästa, återspeglar de data som erhålls av TCP mer den förlust och svarstid som program upplever. Detta beror på att merparten av programtrafiken flödar över TCP. I sådana fall ger ICMP mindre exakta resultat jämfört med TCP.
Brandväggskonfiguration. TCP-protokollet kräver att TCP-paket skickas till en målport. Standardporten som används av network performance monitor-agenter är 8084. Du kan ändra porten när du konfigurerar agenter. Kontrollera att dina nätverksbrandväggar eller NSG-regler (nätverkssäkerhetsgrupp) (i Azure) tillåter trafik på porten. Du måste också se till att den lokala brandväggen på datorerna där agenter är installerade är konfigurerad för att tillåta trafik på den här porten. Du kan använda PowerShell-skript för att konfigurera brandväggsregler på datorer som kör Windows, men du måste konfigurera nätverksbrandväggen manuellt. ICMP fungerar däremot inte med hjälp av en port. I de flesta företagsscenarier tillåts ICMP-trafik via brandväggarna så att du kan använda verktyg för nätverksdiagnostik som ping-verktyget. Om du kan pinga en dator från en annan kan du använda ICMP-protokollet utan att behöva konfigurera brandväggar manuellt.
Anteckning
Vissa brandväggar kan blockera ICMP, vilket kan leda till vidareöverföring som resulterar i ett stort antal händelser i säkerhetsinformationen och händelsehanteringssystemet. Kontrollera att det protokoll som du väljer inte blockeras av en nätverksbrandvägg eller NSG. Annars kan övervakaren av nätverksprestanda inte övervaka nätverkssegmentet. Vi rekommenderar att du använder TCP för övervakning. Använd ICMP i scenarier där du inte kan använda TCP, till exempel när:
- Du använder Windows-klientbaserade noder eftersom TCP-råa socketar inte tillåts i Windows-klienter.
- Nätverksbrandväggen eller nätverkssäkerhetsgruppen blockerar TCP.
- Du vet inte hur du byter protokoll.
Om du väljer att använda ICMP under distributionen kan du växla till TCP när som helst genom att redigera standardövervakningsregeln.
- Gå till Övervakare av nätverksprestanda>>Konfigurera övervakare>. Välj sedan Standardregel.
- Rulla till avsnittet Protokoll och välj det protokoll som du vill använda.
- Välj Spara för att tillämpa inställningen.
Även om standardregeln använder ett specifikt protokoll kan du skapa nya regler med ett annat protokoll. Du kan till och med skapa en blandning av regler där vissa regler använder ICMP och andra använder TCP.
Genomgång
Titta nu på en enkel undersökning av rotorsaken till en hälsohändelse.
På lösningsinstrumentpanelen visar en hälsohändelse att en nätverkslänk inte är felfri. Om du vill undersöka problemet väljer du panelen Nätverkslänkar som övervakas .
Sidan för ökad detaljnivå visar att DMZ2-DMZ1-nätverkslänken inte är felfri. Välj Visa undernätslänkar för den här nätverkslänken.
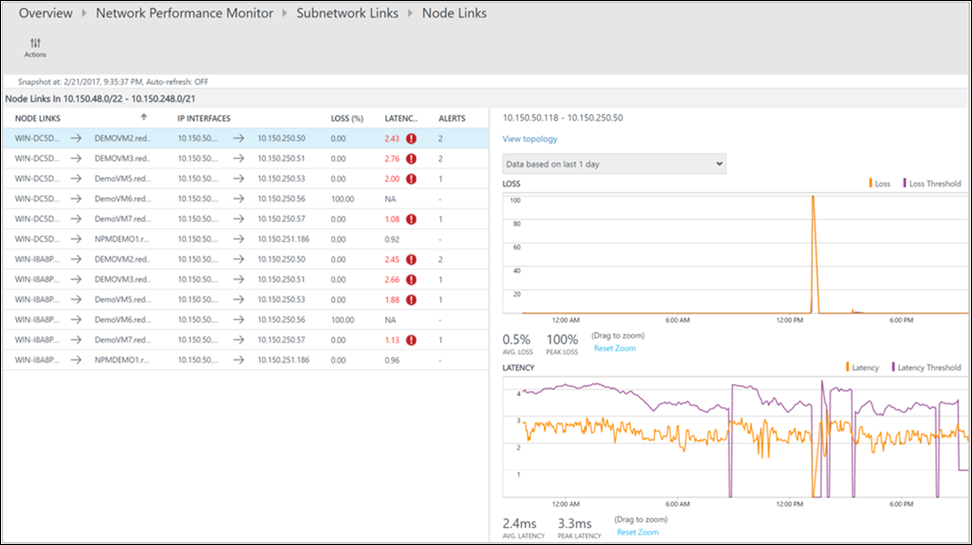
På sidan för ökad detaljnivå visas alla undernätslänkar i nätverkslänken DMZ2-DMZ1 . För båda undernätslänkarna passerade svarstiden tröskelvärdet, vilket gör att nätverkslänken inte är felfri. Du kan också se svarstidstrenderna för båda undernätslänkarna. Använd tidsmarkeringskontrollen i diagrammet för att fokusera på det tidsintervall som krävs. Du kan se den tid på dagen då svarstiden nådde sin topp. Sök i loggarna senare under den här tidsperioden för att undersöka problemet. Välj Visa nodlänkar för att öka detaljnivån ytterligare.

Precis som på föregående sida visar detaljnivån för den specifika undernätslänken dess nodlänkar. Du kan utföra liknande åtgärder här som du gjorde i föregående steg. Välj Visa topologi för att visa topologin mellan de två noderna.
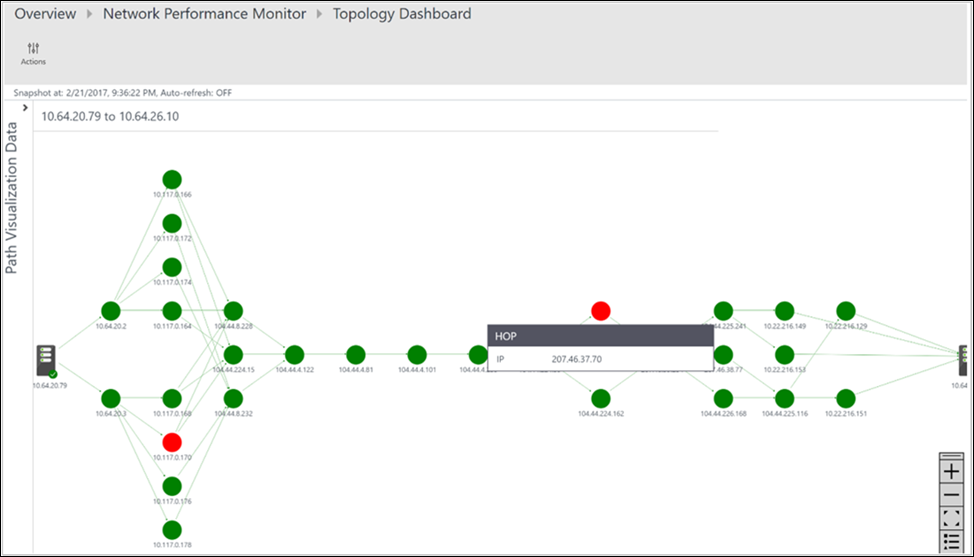
Alla sökvägar mellan de två valda noderna ritas i topologikartan. Du kan visualisera topologin hop-by-hop för vägar mellan två noder på topologikartan. Det ger dig en tydlig bild av hur många vägar som finns mellan de två noderna och vilka sökvägar datapaketen tar. Flaskhalsar för nätverksprestanda visas i rött. Om du vill hitta en felaktig nätverksanslutning eller en felaktig nätverksenhet kan du titta på de röda elementen på topologikartan.
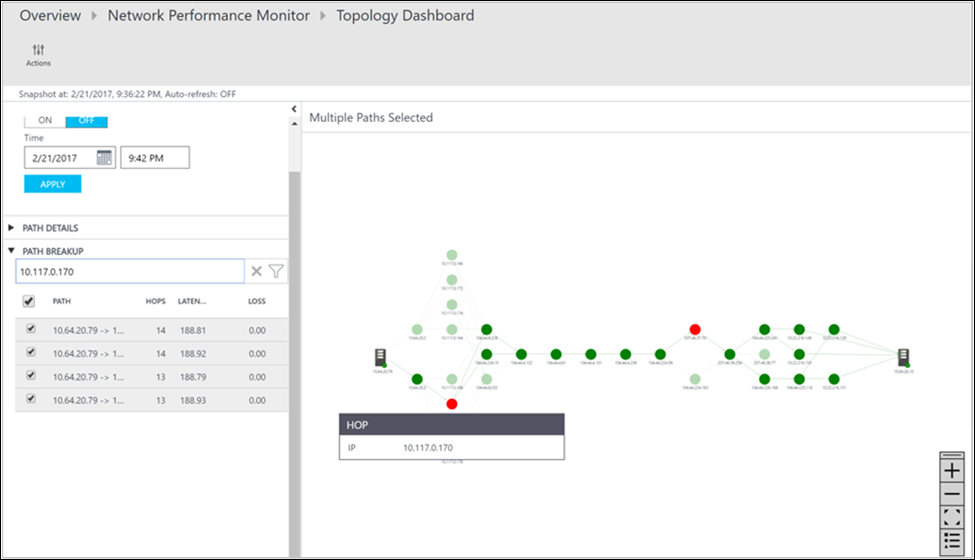
Du kan granska förlust, svarstid och antalet hopp i varje sökväg i åtgärdsfönstret . Använd rullningslisten för att visa information om sökvägar som inte är felfria. Använd filtren för att välja sökvägarna med det felaktiga hoppet så att topologin endast för de valda sökvägarna ritas. Om du vill zooma in eller ut från topologikartan använder du mushjulet.
I följande bild visas rotorsaken till problemområdena i det specifika avsnittet i nätverket i de röda sökvägarna och hoppen. Välj en nod i topologikartan för att visa egenskaperna för noden, som innehåller FQDN och IP-adressen. Om du väljer ett hopp visas hoppens IP-adress.
Nästa steg
Sök i loggar för att visa detaljerade dataposter för nätverksprestanda.