TripPin del 6 – Schema
Den här självstudien i flera delar beskriver hur du skapar ett nytt datakällans tillägg för Power Query. Självstudien är avsedd att utföras sekventiellt – varje lektion bygger på anslutningsappen som skapades i föregående lektioner och lägger stegvis till nya funktioner i anslutningsappen.
I den här lektionen kommer du att:
- Definiera ett fast schema för ett REST API
- Ange datatyper dynamiskt för kolumner
- Framtvinga en tabellstruktur för att undvika omvandlingsfel på grund av saknade kolumner
- Dölj kolumner från resultatuppsättningen
En av de stora fördelarna med en OData-tjänst jämfört med ett standard-REST API är dess $metadata definition. Dokumentet $metadata beskriver de data som finns i den här tjänsten, inklusive schemat för alla dess entiteter (tabeller) och fält (kolumner). Funktionen OData.Feed använder den här schemadefinitionen för att automatiskt ange information om datatyp, så i stället för att hämta alla text- och nummerfält (som du skulle göra från Json.Document) får slutanvändarna datum, heltal, tider och så vidare, vilket ger en bättre övergripande användarupplevelse.
Många REST-API:er kan inte programmatiskt fastställa sitt schema. I dessa fall måste du inkludera schemadefinitioner i anslutningsappen. I den här lektionen definierar du ett enkelt, hårdkodat schema för var och en av dina tabeller och tillämpar schemat på de data som du läser från tjänsten.
Kommentar
Metoden som beskrivs här bör fungera för många REST-tjänster. Framtida lektioner bygger på den här metoden genom att rekursivt framtvinga scheman på strukturerade kolumner (post, lista, tabell) och tillhandahålla exempelimplementeringar som programmatiskt kan generera en schematabell från CSDL- eller JSON-schemadokument .
Generellt sett har det flera fördelar att framtvinga ett schema för de data som returneras av anslutningsappen, till exempel:
- Ange rätt datatyper
- Ta bort kolumner som inte behöver visas för slutanvändare (till exempel interna ID:er eller tillståndsinformation)
- Se till att varje sida med data har samma form genom att lägga till kolumner som kanske saknas i ett svar (ett vanligt sätt för REST-API:er att ange att ett fält ska vara null)
Visa det befintliga schemat med Table.Schema
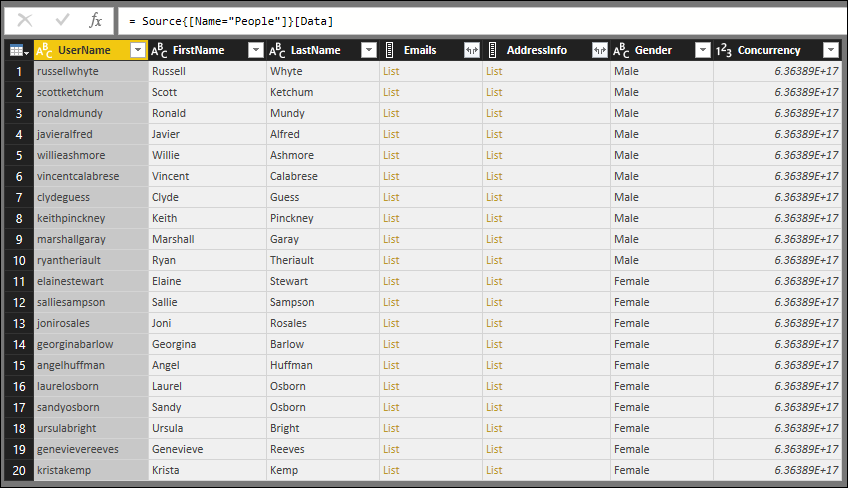
Anslutningsappen som skapades i föregående lektion visar tre tabeller från TripPin-tjänsten –Airlines och PeopleAirports . Kör följande fråga för att visa Airlines tabellen:
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
data
I resultatet visas fyra kolumner som returneras:
- @odata.id
- @odata.editLink
- AirlineCode
- Name
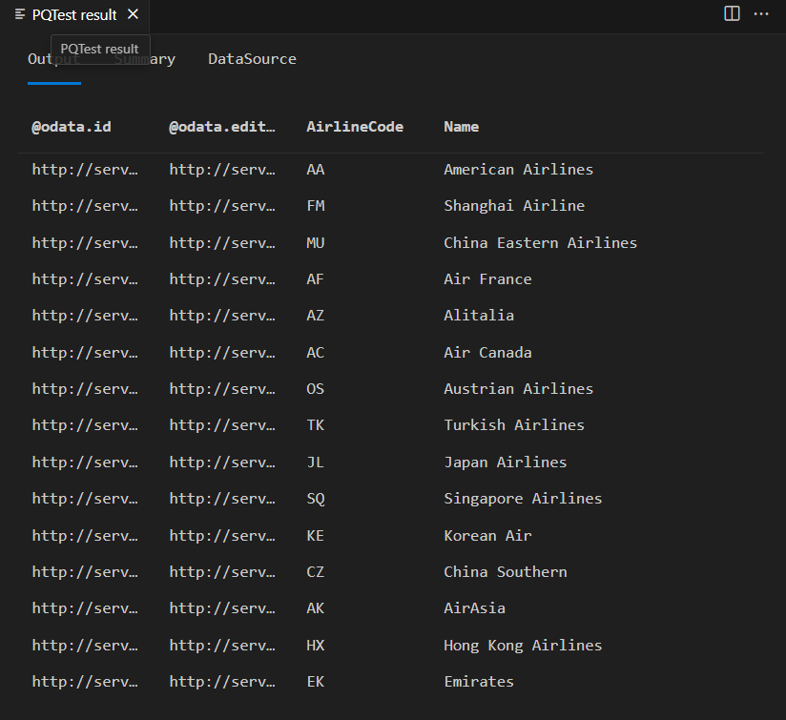
Kolumnerna "@odata.*" är en del av OData-protokollet och inte något du vill eller behöver visa för slutanvändarna av anslutningsappen. AirlineCode och Name är de två kolumner som du vill behålla. Om du tittar på schemat för tabellen (med hjälp av den praktiska funktionen Table.Schema ) kan du se att alla kolumner i tabellen har en datatyp av Any.Type.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
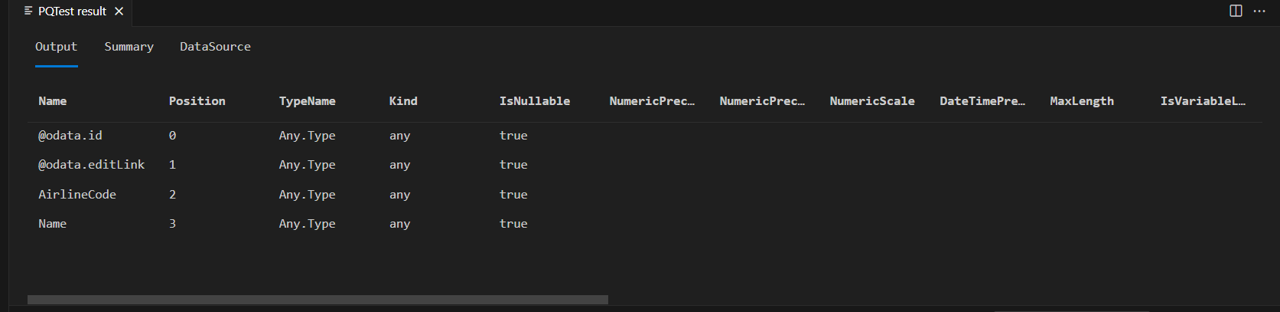
Table.Schema returnerar många metadata om kolumnerna i en tabell, inklusive namn, positioner, typinformation och många avancerade egenskaper, till exempel Precision, Skala och MaxLength.
Framtida lektioner ger designmönster för att ange dessa avancerade egenskaper, men för tillfället behöver du bara bekymra dig om den tillskrivna typen (TypeName), primitiv typ (Kind) och om kolumnvärdet kan vara null (IsNullable).
Definiera en enkel schematabell
Schematabellen består av två kolumner:
| Column | Details |
|---|---|
| Name | Kolumnens namn. Detta måste matcha namnet i de resultat som returneras av tjänsten. |
| Typ | Den M-datatyp som du ska ange. Det kan vara en primitiv typ (text, number, datetimeoch så vidare) eller en tillskriven typ (Int64.Type, Currency.Typeoch så vidare). |
Den hårdkodade schematabellen Airlines för tabellen anger dess AirlineCode och Name kolumner till text, och ser ut så här:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
});
Tabellen Airports har fyra fält som du vill behålla (inklusive ett av typen record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
});
Slutligen har tabellen People sju fält, inklusive listor (Emails, AddressInfo), en nullbar kolumn (Gender) och en kolumn med en tillskriven typ (Concurrency).
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Hjälpfunktionen SchemaTransformTable
Hjälpfunktionen SchemaTransformTable som beskrivs nedan används för att framtvinga scheman för dina data. Det tar följande parametrar:
| Parameter | Typ | Beskrivning |
|---|---|---|
| table | table | Den datatabell som du vill tillämpa schemat på. |
| schema | table | Schematabellen som du vill läsa kolumninformation från med följande typ: type table [Name = text, Type = type]. |
| enforceSchema | Nummer | (valfritt) En uppräkning som styr funktionens beteende. Standardvärdet ( EnforceSchema.Strict = 1) ser till att utdatatabellen matchar schematabellen som angavs genom att lägga till eventuella kolumner som saknas och ta bort extra kolumner. Alternativet EnforceSchema.IgnoreExtraColumns = 2 kan användas för att bevara extra kolumner i resultatet. När EnforceSchema.IgnoreMissingColumns = 3 används ignoreras både saknade kolumner och extra kolumner. |
Logiken för den här funktionen ser ut ungefär så här:
- Kontrollera om det finns kolumner som saknas i källtabellen.
- Kontrollera om det finns några extra kolumner.
- Ignorera strukturerade kolumner (av typen
list,recordochtable) och kolumner som är inställda påtype any. - Använd Table.TransformColumnTypes för att ange varje kolumntyp.
- Ändra ordning på kolumnerna baserat på den ordning de visas i schematabellen.
- Ange typen i själva tabellen med hjälp av Value.ReplaceType.
Kommentar
Det sista steget för att ange tabelltypen tar bort behovet av att Power Query-användargränssnittet härleder typinformation när resultatet visas i frågeredigeraren. Detta tar bort problemet med dubbel begäran som du såg i slutet av föregående självstudie.
Följande hjälpkod kan kopieras och klistras in i tillägget:
EnforceSchema.Strict = 1; // Add any missing columns, remove extra columns, set table type
EnforceSchema.IgnoreExtraColumns = 2; // Add missing columns, do not remove extra columns
EnforceSchema.IgnoreMissingColumns = 3; // Do not add or remove columns
SchemaTransformTable = (table as table, schema as table, optional enforceSchema as number) as table =>
let
// Default to EnforceSchema.Strict
_enforceSchema = if (enforceSchema <> null) then enforceSchema else EnforceSchema.Strict,
// Applies type transforms to a given table
EnforceTypes = (table as table, schema as table) as table =>
let
map = (t) => if Type.Is(t, type list) or Type.Is(t, type record) or t = type any then null else t,
mapped = Table.TransformColumns(schema, {"Type", map}),
omitted = Table.SelectRows(mapped, each [Type] <> null),
existingColumns = Table.ColumnNames(table),
removeMissing = Table.SelectRows(omitted, each List.Contains(existingColumns, [Name])),
primativeTransforms = Table.ToRows(removeMissing),
changedPrimatives = Table.TransformColumnTypes(table, primativeTransforms)
in
changedPrimatives,
// Returns the table type for a given schema
SchemaToTableType = (schema as table) as type =>
let
toList = List.Transform(schema[Type], (t) => [Type=t, Optional=false]),
toRecord = Record.FromList(toList, schema[Name]),
toType = Type.ForRecord(toRecord, false)
in
type table (toType),
// Determine if we have extra/missing columns.
// The enforceSchema parameter determines what we do about them.
schemaNames = schema[Name],
foundNames = Table.ColumnNames(table),
addNames = List.RemoveItems(schemaNames, foundNames),
extraNames = List.RemoveItems(foundNames, schemaNames),
tmp = Text.NewGuid(),
added = Table.AddColumn(table, tmp, each []),
expanded = Table.ExpandRecordColumn(added, tmp, addNames),
result = if List.IsEmpty(addNames) then table else expanded,
fullList =
if (_enforceSchema = EnforceSchema.Strict) then
schemaNames
else if (_enforceSchema = EnforceSchema.IgnoreMissingColumns) then
foundNames
else
schemaNames & extraNames,
// Select the final list of columns.
// These will be ordered according to the schema table.
reordered = Table.SelectColumns(result, fullList, MissingField.Ignore),
enforcedTypes = EnforceTypes(reordered, schema),
withType = if (_enforceSchema = EnforceSchema.Strict) then Value.ReplaceType(enforcedTypes, SchemaToTableType(schema)) else enforcedTypes
in
withType;
Uppdatera TripPin-anslutningsappen
Nu ska du göra följande ändringar i anslutningsappen för att använda den nya koden för schemaframtvingande.
- Definiera en huvudschematabell (
SchemaTable) som innehåller alla schemadefinitioner. TripPin.FeedUppdatera ,GetPageochGetAllPagesByNextLinkför att acceptera enschemaparameter.- Framtvinga schemat i
GetPage. - Uppdatera navigeringstabellkoden för att omsluta varje tabell med ett anrop till en ny funktion (
GetEntity)– detta ger dig större flexibilitet att ändra tabelldefinitionerna i framtiden.
Huvudschematabell
Nu ska du konsolidera dina schemadefinitioner till en enda tabell och lägga till en hjälpfunktion (GetSchemaForEntity) som gör att du kan slå upp definitionen baserat på ett entitetsnamn (till exempel GetSchemaForEntity("Airlines")).
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})},
{"Airports", #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})},
{"People", #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})}
});
GetSchemaForEntity = (entity as text) as table => try SchemaTable{[Entity=entity]}[SchemaTable] otherwise error "Couldn't find entity: '" & entity &"'";
Lägga till schemastöd till datafunktioner
Nu ska du lägga till en valfri schema parameter i TripPin.Feedfunktionerna , GetPageoch GetAllPagesByNextLink .
På så sätt kan du skicka schemat (när du vill) till växlingsfunktionerna, där det tillämpas på de resultat som du får tillbaka från tjänsten.
TripPin.Feed = (url as text, optional schema as table) as table => ...
GetPage = (url as text, optional schema as table) as table => ...
GetAllPagesByNextLink = (url as text, optional schema as table) as table => ...
Du kommer också att uppdatera alla anrop till dessa funktioner för att se till att du skickar schemat korrekt.
Framtvinga schemat
Den faktiska schematillämpningen utförs i din GetPage funktion.
GetPage = (url as text, optional schema as table) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value]),
// enforce the schema
withSchema = if (schema <> null) then SchemaTransformTable(data, schema) else data
in
withSchema meta [NextLink = nextLink];
Kommentar
Den här GetPage implementeringen använder Table.FromRecords för att konvertera listan över poster i JSON-svaret till en tabell.
En viktig nackdel med att använda Table.FromRecords är att det förutsätter att alla poster i listan har samma uppsättning fält.
Detta fungerar för TripPin-tjänsten eftersom OData-posterna är guarenteed för att innehålla samma fält, men detta kanske inte är fallet för alla REST-API:er.
En mer robust implementering skulle använda en kombination av Table.FromList och Table.ExpandRecordColumn.
Senare självstudier ändrar implementeringen för att hämta kolumnlistan från schematabellen, vilket säkerställer att inga kolumner går förlorade eller saknas under JSON-till M-översättningen.
Lägga till funktionen GetEntity
Funktionen GetEntity omsluter anropet till TripPin.Feed.
Den söker efter en schemadefinition baserat på entitetens namn och skapar den fullständiga url:en för begäran.
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schemaTable = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schemaTable)
in
result;
Sedan uppdaterar du funktionen TripPinNavTable så att den anropar GetEntity, i stället för att göra alla anrop infogade.
Den största fördelen med detta är att du kan fortsätta att ändra din entitetsbyggnadskod utan att behöva röra navtabelllogik.
TripPinNavTable = (url as text) as table =>
let
entitiesAsTable = Table.FromList(RootEntities, Splitter.SplitByNothing()),
rename = Table.RenameColumns(entitiesAsTable, {{"Column1", "Name"}}),
// Add Data as a calculated column
withData = Table.AddColumn(rename, "Data", each GetEntity(url, [Name]), type table),
// Add ItemKind and ItemName as fixed text values
withItemKind = Table.AddColumn(withData, "ItemKind", each "Table", type text),
withItemName = Table.AddColumn(withItemKind, "ItemName", each "Table", type text),
// Indicate that the node should not be expandable
withIsLeaf = Table.AddColumn(withItemName, "IsLeaf", each true, type logical),
// Generate the nav table
navTable = Table.ToNavigationTable(withIsLeaf, {"Name"}, "Name", "Data", "ItemKind", "ItemName", "IsLeaf")
in
navTable;
Färdigställa allt
När alla kodändringar har gjorts kompilerar och kör du testfrågan som anropar Table.Schema för tabellen Airlines igen.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
Nu ser du att din Airlines-tabell bara har de två kolumner som du har definierat i schemat:
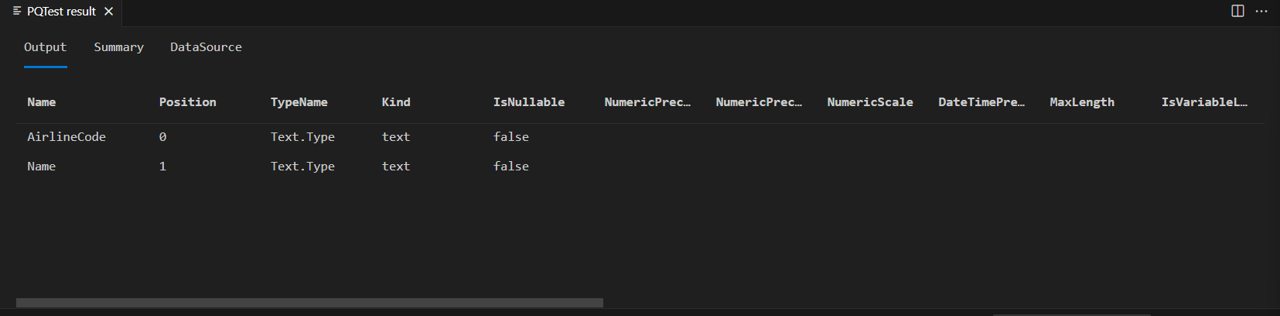
Om du kör samma kod mot tabellen Personer...
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data]
in
Table.Schema(data)
Du ser att den angivna typen som du använde (Int64.Type) också har angetts korrekt.
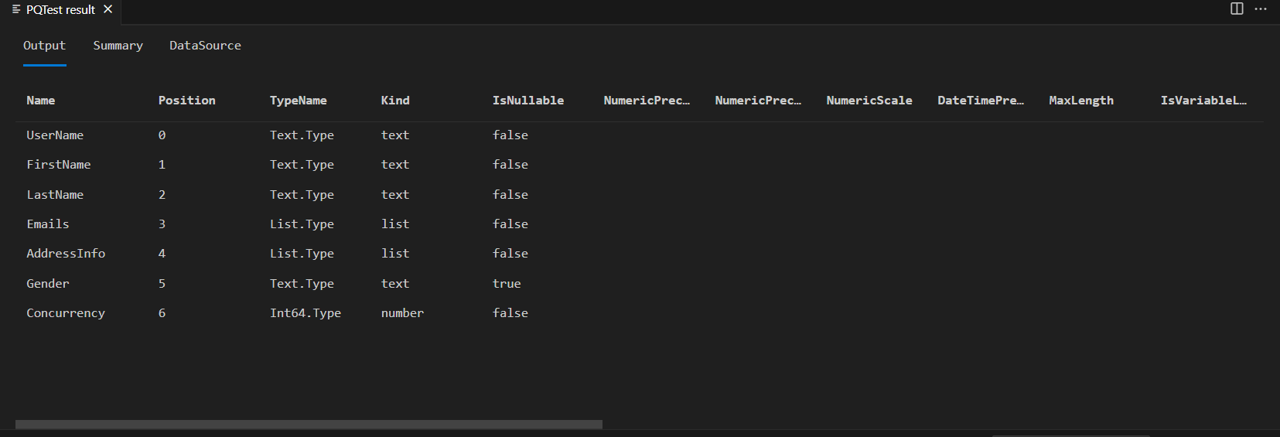
En viktig sak att notera är att den här implementeringen av SchemaTransformTable inte ändrar typerna av list och record kolumnerna, men kolumnerna Emails och AddressInfo skrivs fortfarande som list. Det beror på att Json.Document JSON-matriser mappas korrekt till M-listor och JSON-objekt till M-poster. Om du skulle expandera listan eller postkolumnen i Power Query skulle du se att alla expanderade kolumner kommer att vara av typen valfri. Framtida självstudier förbättrar implementeringen för att rekursivt ange typinformation för kapslade komplexa typer.
Slutsats
I den här självstudien angavs en exempelimplementering för att framtvinga ett schema på JSON-data som returneras från en REST-tjänst. Även om det här exemplet använder ett enkelt hårdkodat schematabellformat kan metoden utökas genom att dynamiskt skapa en schematabelldefinition från en annan källa, till exempel en JSON-schemafil eller metadatatjänst/slutpunkt som exponeras av datakällan.
Förutom att ändra kolumntyper (och värden) anger koden också rätt typinformation i själva tabellen. Om du anger den här typen av information får du fördelar med prestanda vid körning i Power Query, eftersom användarupplevelsen alltid försöker härleda typinformation för att visa rätt användargränssnittsköer för slutanvändaren, och slutsatsdragningsanropen kan utlösa andra anrop till underliggande data-API:er.
Om du visar tabellen Personer med TripPin-anslutningsappen från föregående lektion ser du att alla kolumner har en "skriv alla"-ikon (även de kolumner som innehåller listor):
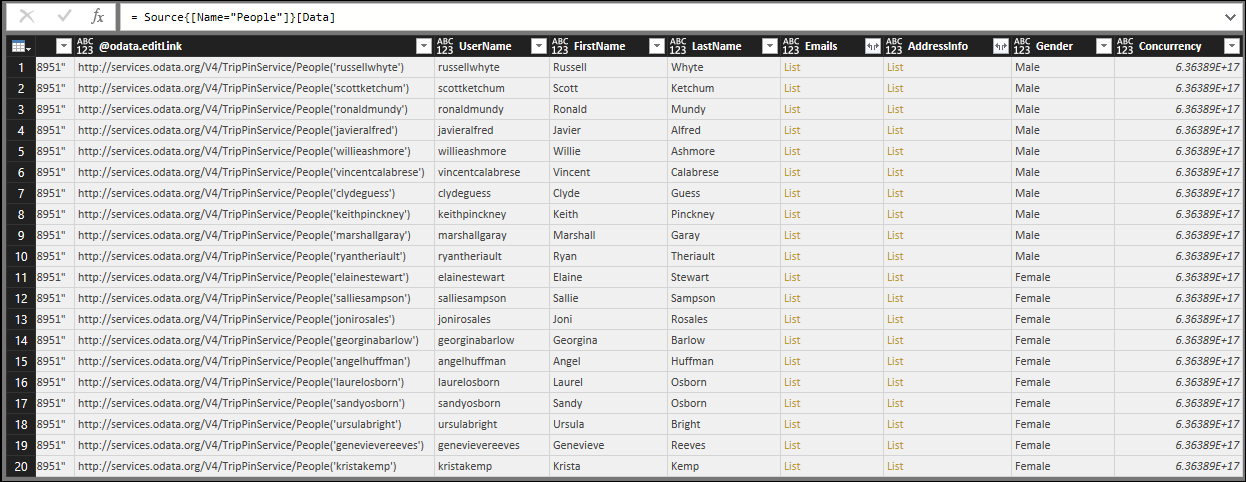
När du kör samma fråga med TripPin-anslutningsappen från den här lektionen ser du nu att typinformationen visas korrekt.