Använda AI Insights i Power BI Desktop
I Power BI kan du använda AI Insights för att få åtkomst till en samling förtränade maskininlärningsmodeller som förbättrar dina dataförberedelser. Du kan komma åt AI Insights i Power Query-redigeraren. Du hittar dess associerade funktioner via flikarna Home och Lägg till kolumn i Power Query-redigeraren.
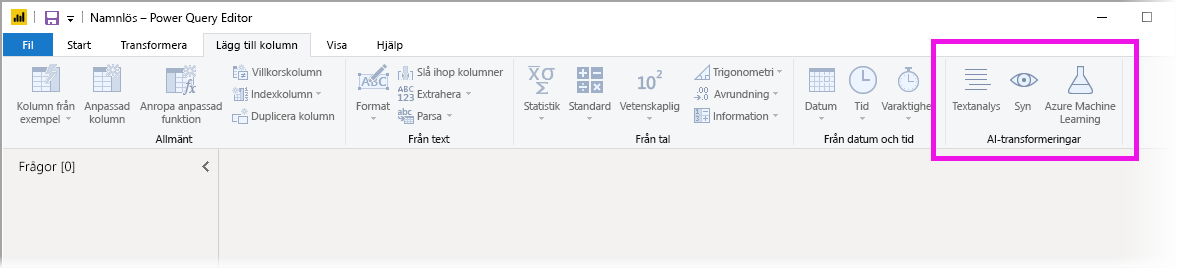
I den här artikeln beskrivs funktionerna för textanalys och visionsfunktioner, båda från Azure Cognitive Services. I den här artikeln finns också ett avsnitt som beskriver de anpassade funktioner som är tillgängliga i Power BI från Azure Machine Learning.
Använda textanalys och vision
Med Textanalys och vision i Power BI kan du använda olika algoritmer från Azure Cognitive Services för att utöka dina data i Power Query.
Följande tjänster stöds för närvarande:
Omvandlingarna körs i Power BI-tjänsten och kräver ingen Azure Cognitive Services-prenumeration.
Viktig
Användning av textanalys- eller visionsfunktionerna kräver Power BI Premium.
Aktivera textanalys och vision på Premium-kapaciteter
Cognitive Services stöds för Premium-kapacitetsnoder EM2, A2 eller P1 och andra noder med fler resurser. En separat AI-arbetsbelastning på kapaciteten används för att köra Cognitive Services. Innan du använder Cognitive Services i Power BI måste du aktivera AI-arbetsbelastningen i kapacitetsinställningar i administratörsportalen. Du kan aktivera AI-arbetsbelastningen i avsnittet arbetsbelastningar och definiera den maximala mängd minne som du vill att arbetsbelastningen ska förbruka. Den rekommenderade minnesgränsen är 20%. Om du överskrider den här gränsen blir frågan långsammare.
Tillgängliga funktioner
I det här avsnittet beskrivs tillgängliga funktioner i Cognitive Services i Power BI.
Identifiera språk
Funktionen Detect language utvärderar textindata och returnerar språknamnet och ISO-identifieraren för varje fält. Den här funktionen är användbar för datakolumner som samlar in godtycklig text, där språket är okänt. Funktionen förväntar sig data i textformat som indata.
Textanalys identifierar upp till 120 språk. För mer information, se språk som stöds.
Extrahera nyckelfraser
Funktionen för extrahering av nyckelfraser utvärderar ostrukturerad text och returnerar en lista med nyckelfraser för varje textfält. Funktionen kräver ett textfält som inmatning och accepterar en valfri inmatning för en ISO-kod för språk.
Extrahering av nyckelfraser fungerar bäst när du ger den större textbitar att arbeta med, mittemot attitydanalys. Attitydanalys presterar bättre på mindre textblock. För att få bästa resultat från båda verksamheterna bör du överväga att omstrukturera indata i enlighet med detta.
Poängsentiment
Funktionen Score sentiment utvärderar textindata och returnerar en attitydpoäng för varje dokument, från 0 (negativ) till 1 (positiv). Score sentiment accepterar också en valfri indata för en ISO-kod för språk. Den här funktionen är användbar för att identifiera positiva och negativa sentiment i sociala medier, kundrecensioner och diskussionsforum.
Textanalys använder en algoritm för maskininlärningsklassificering för att generera en attitydpoäng mellan 0 och 1. Poäng närmare 1 indikerar positiv attityd. Poäng närmare 0 indikerar negativ attityd. Modellen är förtränad med en omfattande texttext med attitydassociationer. För närvarande går det inte att tillhandahålla egna träningsdata. Modellen använder en kombination av tekniker under textanalys, inklusive textbearbetning, del av talanalys, ordplacering och ordassociationer. Mer information om algoritmen finns i Introducing Text Analytics.
Attitydanalys utförs på hela indatafältet, i stället för att extrahera sentiment för en viss entitet i texten. I praktiken finns det en tendens att bedömningsnoggrannheten förbättras när dokument innehåller en eller två meningar snarare än ett stort textblock. Under en utvärderingsfas för objektivitet avgör modellen om ett indatafält som helhet är objektivt eller innehåller attityd. Ett indatafält som mestadels är objektivt går inte vidare till attitydidentifieringsfrasen, vilket resulterar i 0,50 poäng, utan ytterligare bearbetning. För indatafält som fortsätter i pipelinen genererar nästa fas en poäng som är större eller mindre än 0,50, beroende på graden av attityd som identifieras i indatafältet.
Attitydanalys stöder för närvarande engelska, tyska, spanska och franska. Andra språk finns i förhandsversion. För mer information, se språk som stöds.
Tagga bilder
Funktionen Tag Images returnerar taggar baserat på mer än 2 000 igenkännliga objekt, levande varelser, landskap och åtgärder. När taggar är tvetydiga eller inte allmänt kända ger resultatet tips för att klargöra taggens innebörd i samband med en känd kontext. Taggar är inte ordnade som taxonomi och det finns inga arvshierarkier. En samling innehållstaggar utgör grunden för en bild beskrivning som visas på ett lättläst språk och formateras i fullständiga meningar.
När du har laddat upp en bild eller angett en bild-URL matar algoritmerna ut taggar baserat på objekt, levande varelser och åtgärder som identifieras i bilden. Taggning är inte begränsat till huvudämnet, till exempel en person i förgrunden, men inkluderar även inställningen (inomhus eller utomhus), möbler, verktyg, växter, djur, tillbehör, prylar och så vidare.
Den här funktionen kräver en bild-URL eller ett base-64-fält som indata. För närvarande stöder bildtaggning engelska, spanska, japanska, portugisiska och förenklad kinesiska. För mer information, se språk som stöds.
Anropa textanalys- eller visionsfunktioner i Power Query
Om du vill utöka dina data med textanalys- eller visionsfunktioner öppnar du Power Query-redigeraren. I det här exemplet går vi igenom hur man bedömer känslan i en text. Du kan använda samma steg för att extrahera nyckelfraser, identifiera språk och tagga bilder.
Välj knappen Textanalys i menyfliksområdet Start eller Lägg till kolumn. Logga sedan in när du ser uppmaningen.
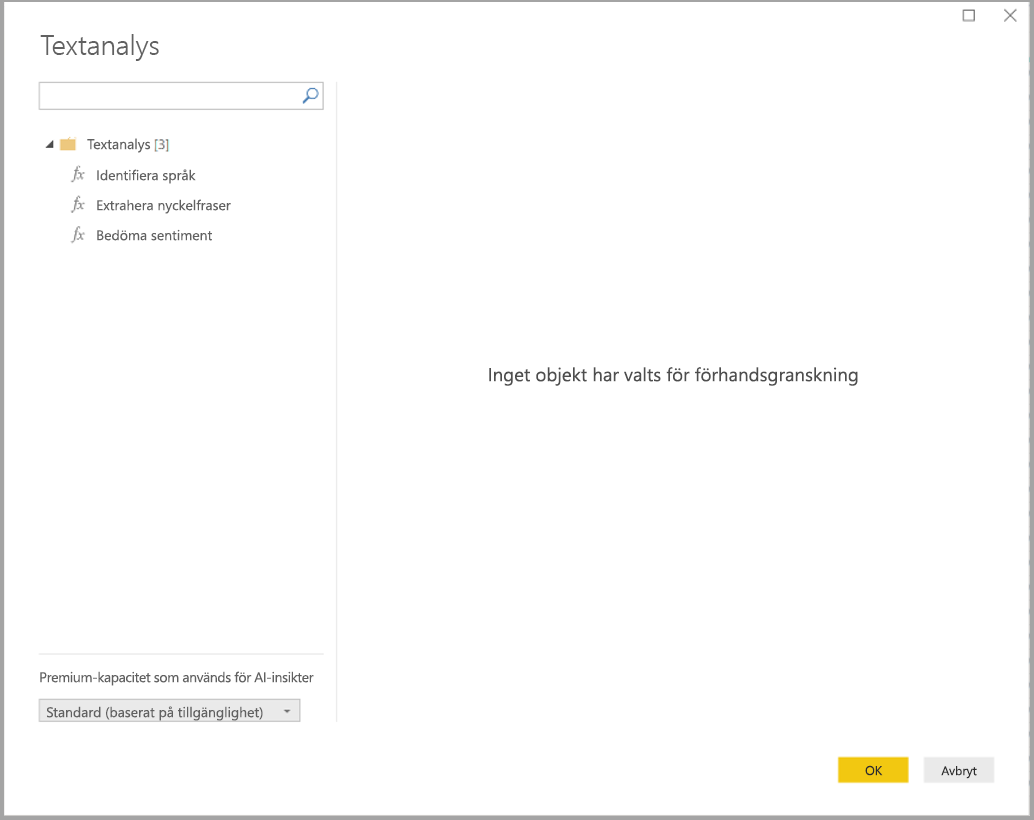
När du har loggat in väljer du den funktion som du vill använda och den datakolumn som du vill transformera i popup-fönstret.
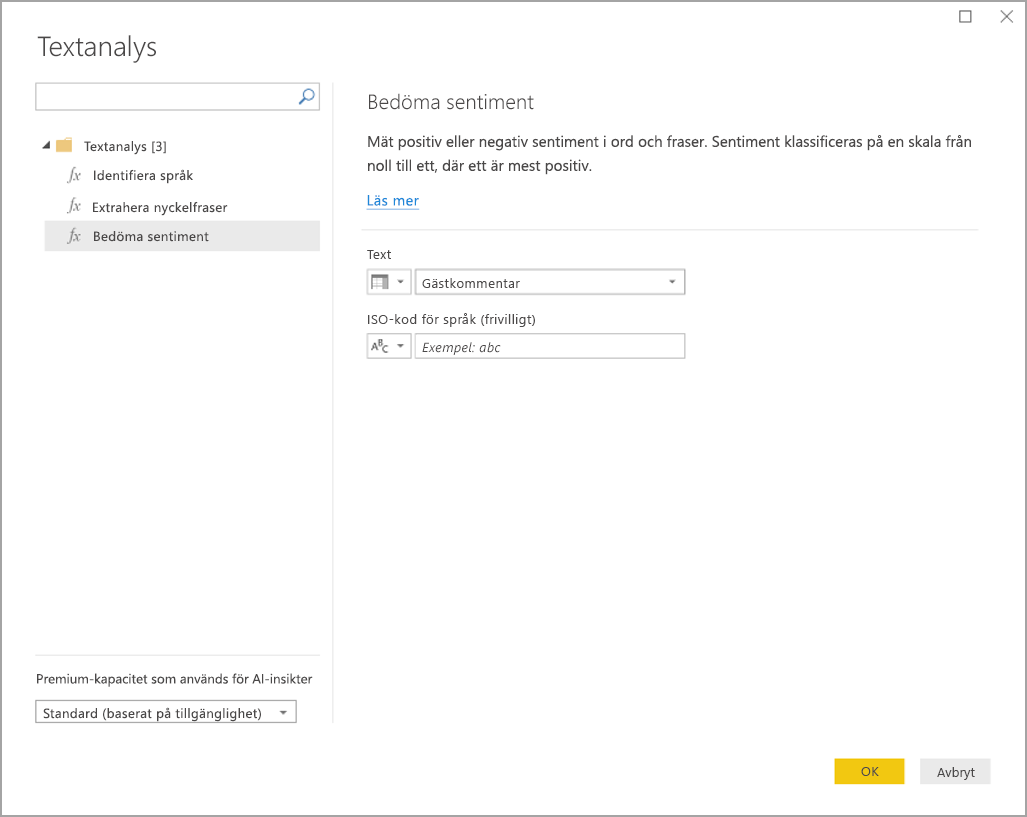
Power BI väljer en Premium-kapacitet för att köra funktionen på och skicka tillbaka resultaten till Power BI Desktop. Den valda kapaciteten används endast för textanalys- och visionsfunktionen under program och uppdateringar i Power BI Desktop. När Power BI publicerar rapporten körs uppdateringar på Premium-kapaciteten för arbetsytan som rapporten publiceras till. Du kan ändra kapaciteten som används för alla Cognitive Services i listrutan i det nedre vänstra hörnet i popup-fönstret.
ISO-kod för språk är en valfri indata för att ange språket för texten. Du kan använda en kolumn som indata eller ett statiskt fält. I det här exemplet anges språket som engelska (en) för hela kolumnen. Om du lämnar det här fältet tomt identifierar Power BI automatiskt språket innan du tillämpar funktionen. Välj sedan Använd.
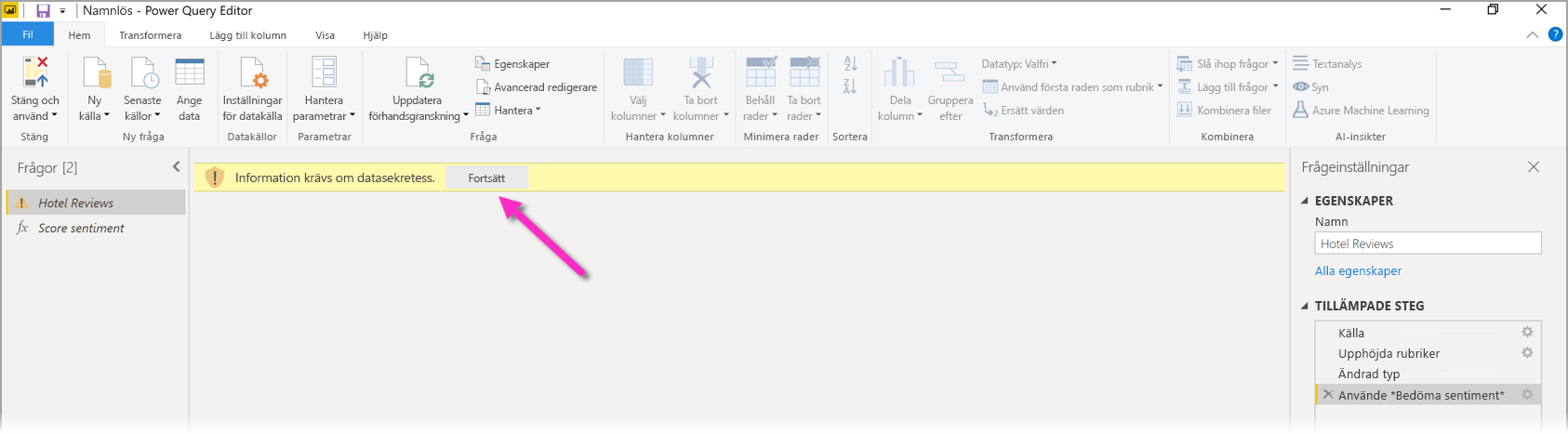
Första gången du använder AI Insights på en ny datakälla uppmanar Power BI Desktop dig att ange sekretessnivån för dina data.
Notera
Uppdateringar av semantikmodellen i Power BI fungerar bara för datakällor där sekretessnivån är inställd på offentlig eller organisatorisk.
När du har anropat funktionen läggs resultatet till som en ny kolumn i tabellen. Omvandlingen läggs också till som ett tillämpat steg i frågan.
När det gäller bildtaggning och extrahering av nyckelfraser kan resultatet returnera flera värden. Varje enskilt resultat returneras på en dubblett av den ursprungliga raden.
Publicera en rapport med textanalys- eller visionsfunktioner
När du redigerar i Power Query och utför uppdateringar i Power BI Desktop använder textanalys och vision den Premium-kapacitet som valdes i Power Query-redigeraren. När Textanalys eller Vision har publicerat rapporten använder de Premium-kapaciteten för arbetsytan som den publicerades i.
Rapporter med tillämpade textanalys- och visionsfunktioner bör publiceras till en arbetsyta som finns på en Premium-kapacitet, annars misslyckas uppdateringen av semantikmodellen.
Hantera påverkan på en Premium-kapacitet
I följande avsnitt beskrivs hur du kan hantera effekten av textanalys och vision på kapaciteten.
Välj en kapacitet
Rapportförfattare kan välja den Premium-kapacitet som AI Insights ska köras på. Som standard väljer Power BI den första kapacitet som skapats som användaren har åtkomst till.
Övervaka med appen Kapacitetsmått
Premium-kapacitetsägare kan övervaka effekten av textanalys- och visionsfunktioner på en kapacitet med appen Microsoft Fabric Capacity Metrics. Appen innehåller detaljerade mått på hälsotillståndet för AI-arbetsbelastningarna i din kapacitet. Det översta diagrammet visar minnesförbrukningen för AI-arbetsbelastningar. Premium-kapacitetsadministratörer kan ange minnesgränsen för AI-arbetsbelastningen per kapacitet. När minnesanvändningen når minnesgränsen kan du överväga att öka minnesgränsen eller flytta vissa arbetsytor till en annan kapacitet.
Jämför Power Query och Power Query Online
De textanalys- och visionsfunktioner som används i Power Query och Power Query Online är desamma. Det finns bara några skillnader mellan upplevelserna:
- Power Query har separata knappar för textanalys, vision och Azure Machine Learning. I Power Query Online kombineras dessa funktioner på en meny.
- I Power Query kan rapportförfattaren välja den Premium-kapacitet som används för att köra funktionerna. Det här valet krävs inte i Power Query Online eftersom ett dataflöde redan finns på en viss kapacitet.
Överväganden och begränsningar i textanalys
Det finns några överväganden och begränsningar att tänka på när du använder textanalys.
- Inkrementell uppdatering stöds men kan orsaka prestandaproblem när du använder frågor med AI-insikter.
- Direct Query stöds inte.
Använda Azure Machine Learning
Många organisationer använder Machine Learning modeller för bättre insikter och förutsägelser om sin verksamhet. Möjligheten att visualisera och anropa insikter från dessa modeller kan bidra till att sprida dessa insikter till de företagsanvändare som behöver dem mest. Power BI gör det enkelt att införliva insikterna från modeller som finns i Azure Machine Learning med hjälp av enkla punkt- och klickgester.
För att använda den här funktionen kan en dataexpert bevilja åtkomst till Azure Machine Learning-modellen till BI-analytikern med hjälp av Azure-portalen. I början av varje session identifierar Power Query sedan alla Azure Machine Learning-modeller som användaren har åtkomst till och exponerar dem som dynamiska Power Query-funktioner. Användaren kan sedan anropa dessa funktioner genom att komma åt dem från menyfliksområdet i Power Query-redigeraren eller genom att anropa M-funktionen direkt. Power BI batchar också automatiskt åtkomstbegäranden när du anropar Azure Machine Learning-modellen för en uppsättning rader för att uppnå bättre prestanda.
Den här funktionen stöds i Power BI Desktop, Power BI-dataflöden och för Power Query Online i Power BI-tjänsten.
Mer information om dataflöden finns i dataförberedelser via självbetjäning i Power BI.
Mer information om Azure Machine Learning finns i följande artiklar:
- Översikt: Vad är Azure Machine Learning?
- Snabbstarter och självstudier för Azure Machine Learning: Dokumentation om Azure Machine Learning
Bevilja åtkomst till en Azure Machine Learning-modell
För att få åtkomst till en Azure Machine Learning-modell från Power BI måste användaren ha Läs åtkomst till Azure-prenumerationen. Dessutom måste de också ha Läs åtkomst till Machine Learning-arbetsytan.
Stegen i det här avsnittet beskriver hur du beviljar en Power BI-användare åtkomst till en modell som finns i Azure Machine Learning-tjänsten. Med den här åtkomsten kan de använda den här modellen som en Power Query-funktion. Mer information finns i Hantera åtkomst med hjälp av RBAC och Azure-portalen.
- Logga in på Azure-portalen.
- Gå till sidan Prenumerationer. Du hittar sidan Prenumerationer via listan Alla tjänster i den vänstra navigeringsmenyn i Azure-portalen.
- Välj din prenumeration.
- Välj Åtkomstkontroll (IAM)och tryck sedan på knappen Lägg till.
- Välj Läsare som roll. Välj den Power BI-användare som du vill bevilja åtkomst till Azure Machine Learning-modellen till.
- Välj Spara.
- Upprepa steg tre till sex för att ge användaren Läsare åtkomst till den specifika arbetsytan för maskininlärning som är värd för modellen.
Schemaidentifiering för Machine Learning-modeller
Dataexperter använder främst Python för att utveckla och till och med distribuera sina maskininlärningsmodeller för Machine Learning. Dataexperten måste uttryckligen generera schemafilen med python.
Den här schemafilen måste ingå i den distribuerade webbtjänsten för Machine Learning-modeller. Om du vill generera schemat för webbtjänsten automatiskt måste du ange ett exempel på indata/utdata i inmatningsskriptet för den distribuerade modellen. Mer information finns i underavsnittet om (valfritt) automatisk Swagger-schemagenerering i dokumentationen Distribuera modeller med Azure Machine Learning-tjänsten. Länken innehåller exempelinmatningsskriptet med instruktioner för schemagenereringen.
Mer specifikt refererar funktionerna @input_schema och @output_schema i postskriptet till indata- och utdataexempelformaten i variablerna input_sample och output_sample. Funktionerna använder dessa exempel för att generera en OpenAPI-specifikation (Swagger) för webbtjänsten under distributionen.
De här instruktionerna för schemagenerering, genom att uppdatera inmatningsskriptet, måste också tillämpas på modeller som skapats med hjälp av automatiserade maskininlärningsexperiment med Azure Machine Learning SDK.
Not
Modeller som skapats med hjälp av det visuella Azure Machine Learning-gränssnittet stöder för närvarande inte schemagenerering, men de kommer att göra det i efterföljande versioner.
Anropa en Azure Machine Learning-modell i Power Query
Du kan anropa valfri Azure Machine Learning-modell som du har beviljats åtkomst till direkt från Power Query-redigeraren. Om du vill komma åt Azure Machine Learning-modellerna väljer du knappen Azure Machine Learning i menyfliksområdet Home eller Lägg till kolumn i Power Query-redigeraren.

Alla Azure Machine Learning-modeller som du har åtkomst till visas här som Power Query-funktioner. Dessutom mappas indataparametrarna för Azure Machine Learning-modellen automatiskt som parametrar för motsvarande Power Query-funktion.
Om du vill anropa en Azure Machine Learning-modell kan du ange någon av den valda entitetens kolumner som indata från listrutan. Du kan också ange ett konstant värde som ska användas som indata genom att växla kolumnikonen till vänster om indatadialogrutan.
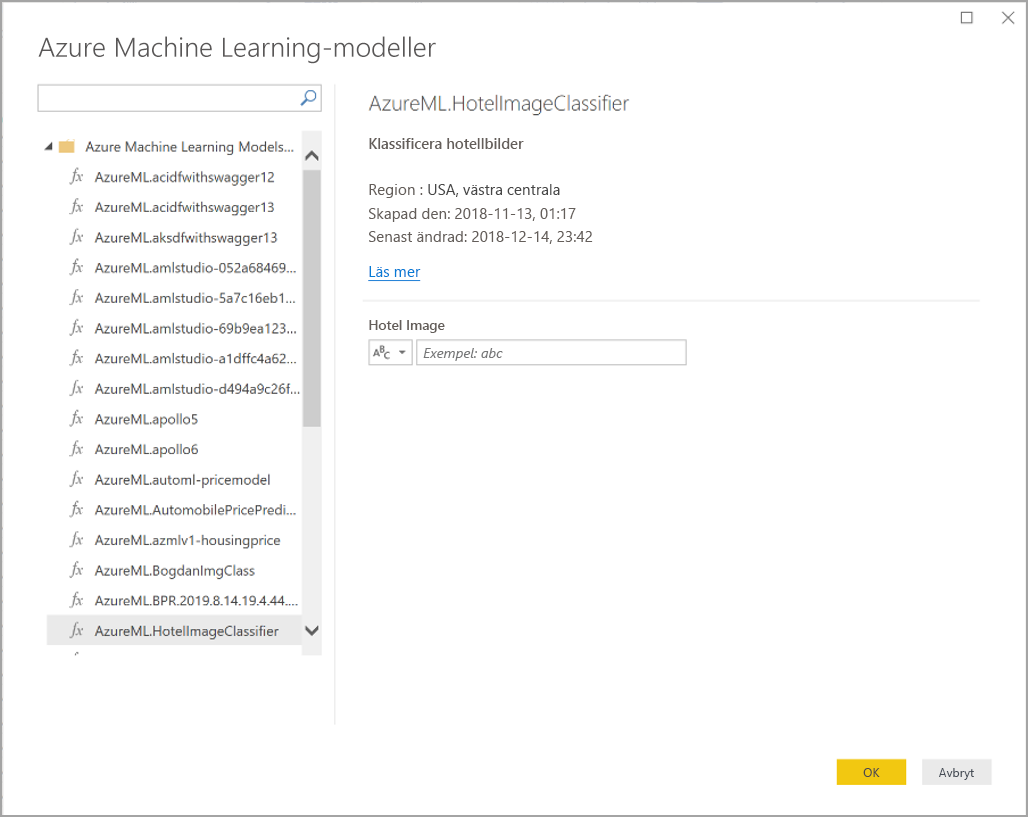
Välj OK för att visa förhandsversionen av Azure Machine Learning-modellens utdata som en ny kolumn i entitetstabellen. Modellanropet visas som ett tillämpat steg för sökfrågan.
Om modellen returnerar flera utdataparametrar grupperas de som en post i utdatakolumnen. Du kan expandera kolumnen för att skapa enskilda utdataparametrar i separata kolumner.
Överväganden och begränsningar i Azure Machine Learning
Följande överväganden och begränsningar gäller för Azure Machine Learning i Power BI Desktop.
- Modeller som skapats med hjälp av det visuella Azure Machine Learning-gränssnittet stöder för närvarande inte schemagenerering. Support förväntas i efterföljande versioner.
- Inkrementell uppdatering stöds men kan orsaka prestandaproblem när du använder frågor med AI-insikter.
- Direct Query stöds inte.
- Användare med en PPU-licens (Premium Per User) kan inte använda AI Insights från Power BI Desktop. du måste använda en icke-PPU Premium-licens med motsvarande Premium-kapacitet. Du kan fortfarande använda AI Insights med en PPU-licens för Power BI-tjänsten.
Relaterat innehåll
Den här artikeln gav en översikt över integreringen av Machine Learning i Power BI Desktop. Följande artiklar kan också vara intressanta och användbara.