Utveckla lösningar med dataflöden
Power BI-dataflöden är en företagsfokuserad dataförberedelselösning som möjliggör ett ekosystem med data som är redo för förbrukning, återanvändning och integrering. Den här artikeln innehåller några vanliga scenarier, länkar till artiklar och annan information som hjälper dig att förstå och använda dataflöden till sin fulla potential.
Få åtkomst till Premium-funktioner i dataflöden
Power BI-dataflöden i Premium-kapaciteter ger många viktiga funktioner som hjälper dig att uppnå större skalning och prestanda för dina dataflöden, till exempel:
- Avancerad beräkning, vilket påskyndar ETL-prestanda och ger DirectQuery-funktioner.
- Inkrementell uppdatering som gör att du kan läsa in data som har ändrats från en källa.
- Länkade entiteter som du kan använda för att referera till andra dataflöden.
- Beräknade entiteter som du kan använda för att skapa komposterbara byggstenar med dataflöden som innehåller mer affärslogik.
Därför rekommenderar vi att du använder dataflöden i en Premium-kapacitet när det är möjligt. Dataflöden som används i en Power BI Pro licens kan användas för enkla, småskaliga användningsfall.
Lösning
Det går att få åtkomst till dessa Premium-funktioner i dataflöden på två sätt:
- Ange en Premium-kapacitet till en viss arbetsyta och ta med din egen Pro-licens för att skapa dataflöden här.
- Ta med din egen PPU-licens (Premium per användare), som kräver att andra medlemmar i arbetsytan också har en PPU-licens.
Du kan inte använda PPU-dataflöden (eller annat innehåll) utanför PPU-miljön (till exempel i Premium eller andra SKU:er eller licenser).
För Premium-kapaciteter behöver dina användare av dataflöden i Power BI Desktop inte explicita licenser för att använda och publicera till Power BI. Men för att publicera till en arbetsyta eller dela en resulterande semantisk modell behöver du minst en Pro-licens.
För PPU måste alla som skapar eller använder PPU-innehåll ha en PPU-licens. Det här kravet varierar från resten av Power BI eftersom du uttryckligen behöver licensiera alla med PPU. Du kan inte blanda kostnadsfria, Pro- eller ens Premium-kapaciteter med PPU-innehåll om du inte migrerar arbetsytan till en Premium-kapacitet.
Att välja en modell beror vanligtvis på organisationens storlek och mål, men följande riktlinjer gäller.
| Teamtyp | Premium per kapacitet | Premium per användare |
|---|---|---|
| >5 000 användare | ✔ | |
| <5 000 användare | ✔ |
För små team kan PPU överbrygga klyftan mellan Kostnadsfri, Pro och Premium per kapacitet. Om du har större behov är det bästa sättet att använda en Premium-kapacitet med användare som har Pro-licenser.
Skapa användardataflöden med säkerhet tillämpad
Anta att du behöver skapa dataflöden för förbrukning men har säkerhetskrav:
I det här scenariot har du förmodligen två typer av arbetsytor:
Serverdelsarbetsytor där du utvecklar dataflöden och skapar affärslogik.
Användararbetsytor där du vill exponera vissa dataflöden eller tabeller för en viss grupp användare för förbrukning:
- Användararbetsytan innehåller länkade tabeller som pekar på dataflödena i serverdelsarbetsytan.
- Användare har visningsåtkomst till konsumentarbetsytan och ingen åtkomst till serverdelsarbetsytan.
- När en användare använder Power BI Desktop för att komma åt ett dataflöde på användararbetsytan kan de se dataflödet. Men eftersom dataflödet visas tomt i Navigatören visas inte de länkade tabellerna.
Förstå länkade tabeller
Länkade tabeller är bara en pekare till de ursprungliga dataflödestabellerna, och de ärver källans behörighet. Om Power BI tillät den länkade tabellen att använda målbehörigheten kan alla användare kringgå källbehörigheten genom att skapa en länkad tabell i målet som pekar på källan.
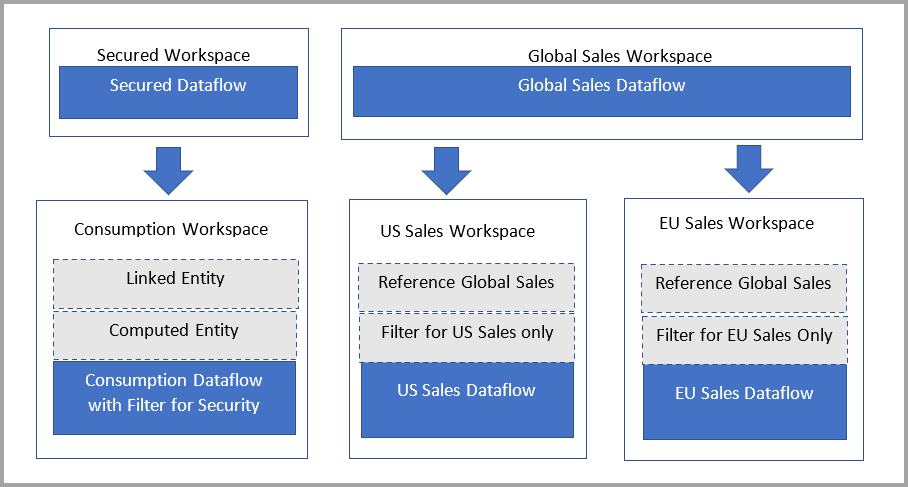
Lösning: Använda beräknade tabeller
Om du har åtkomst till Power BI Premium kan du skapa en beräknad tabell i målet som refererar till den länkade tabellen, som har en kopia av data från den länkade tabellen. Du kan ta bort kolumner via projektioner och ta bort rader via filter. Användaren med behörighet på målarbetsytan kan komma åt data via den här tabellen.
Ursprung för privilegierade personer visar också den refererade arbetsytan och gör det möjligt för användare att länka tillbaka för att fullt ut förstå det överordnade dataflödet. För de användare som inte är privilegierade respekteras fortfarande sekretessen. Endast namnet på arbetsytan visas.
Följande diagram illustrerar den här konfigurationen. Till vänster finns arkitekturmönstret. Till höger finns ett exempel som visar att försäljningsdata delas upp och skyddas efter region.
Minska uppdateringstiderna för dataflöden
Anta att du har ett stort dataflöde, men du vill skapa semantiska modeller från det dataflödet och minska den tid som krävs för att uppdatera det. Uppdateringar tar vanligtvis lång tid att slutföra från datakällan till dataflöden till den semantiska modellen. Långa uppdateringar är svåra att hantera eller underhålla.
Lösning: Använd tabeller med Aktivera inläsning explicit konfigurerad för refererade tabeller och inaktivera inte inläsning
Power BI stöder enkel orkestrering för dataflöden, enligt definitionen i förstå och optimera uppdatering av dataflöden. Om du vill dra nytta av orkestreringen måste du uttryckligen ha alla underordnade dataflöden konfigurerade för att aktivera inläsning.
Det är vanligtvis bara lämpligt att inaktivera belastningen när kostnaden för att läsa in fler frågor avbryter fördelen med den entitet som du utvecklar.
Om du inaktiverar inläsning innebär det att Power BI inte utvärderar den aktuella frågan, när den används som ingredienser, det vill säga refereras i andra dataflöden, innebär det också att Power BI inte behandlar den som en befintlig tabell där vi kan ge en pekare till och utföra viknings- och frågeoptimeringar. I den meningen är det bara en koppling eller sammanslagning av två datakällfrågor att utföra transformeringar som en koppling eller sammanslagning. Sådana åtgärder kan ha en negativ effekt på prestanda, eftersom Power BI helt måste läsa in redan beräknad logik igen och sedan tillämpa mer logik.
För att förenkla frågebearbetningen av ditt dataflöde och säkerställa att motoroptimeringar sker aktiverar du belastningen och ser till att beräkningsmotorn i Power BI Premium-dataflöden har angetts till standardinställningen, som är Optimerad.
Om du aktiverar inläsning kan du också behålla den fullständiga vyn över ursprung eftersom Power BI betraktar ett icke-aktiverat inläsningsdataflöde som ett nytt objekt. Om ursprung är viktigt för dig ska du inte inaktivera inläsning för entiteter eller dataflöden som är anslutna till andra dataflöden.
Minska uppdateringstiderna för semantiska modeller
Anta att du har ett stort dataflöde, men du vill skapa semantiska modeller av det och minska orkestreringen. Uppdateringar tar lång tid att slutföra från datakällan till dataflöden till semantiska modeller, vilket ger ökad svarstid.
Lösning: Använda DirectQuery-dataflöden
DirectQuery kan användas när inställningen för en arbetsytas förbättrade beräkningsmotor (ECE) uttryckligen konfigureras till På. Den här inställningen är användbar när du har data som inte behöver läsas in direkt i en Power BI-modell. Om du konfigurerar ECE som På för första gången sker ändringarna som tillåter DirectQuery under nästa uppdatering. Du måste uppdatera den när du aktiverar den för att ändringarna ska ske omedelbart. Uppdateringar av den inledande dataflödesbelastningen kan vara långsammare eftersom Power BI skriver data till både lagring och en hanterad SQL-motor.
Sammanfattningsfullt kan du genom att använda DirectQuery med dataflöden göra följande förbättringar av dina Power BI- och dataflödesprocesser:
- Undvik separata uppdateringsscheman: DirectQuery ansluter direkt till ett dataflöde, vilket tar bort behovet av att skapa en importerad semantisk modell. Genom att använda DirectQuery med dina dataflöden behöver du därför inte längre separata uppdateringsscheman för dataflödet och den semantiska modellen för att säkerställa att dina data synkroniseras.
- Filtrering av data: DirectQuery är användbart för att arbeta med en filtrerad vy av data i ett dataflöde. Om du vill filtrera data och på så sätt arbeta med en mindre delmängd av data i dataflödet kan du använda DirectQuery (och ECE) för att filtrera dataflödesdata och arbeta med den filtrerade delmängd som du behöver.
Genom att använda DirectQuery handlas i allmänhet aktuella data i din semantiska modell med långsammare rapportprestanda jämfört med importläget. Tänk bara på den här metoden när:
- Ditt användningsfall kräver data med låg latens som kommer från ditt dataflöde.
- Dataflödesdata är stora.
- En import skulle vara för tidskrävande.
- Du är villig att byta cachelagrade prestanda mot aktuella data.
Lösning: Använd anslutningsappen för dataflöden för att aktivera frågedelegering och inkrementell uppdatering för import
Den enhetliga dataflödesanslutningsappen kan avsevärt minska utvärderingstiden för steg som utförs över beräknade entiteter, till exempel att utföra kopplingar, distinkta, filter och gruppera efter åtgärder. Det finns två specifika fördelar:
- Nedströmsanvändare som ansluter till dataflödesanslutningen i Power BI Desktop kan dra nytta av bättre prestanda i redigeringsscenarier eftersom den nya anslutningsappen stöder frågedelegering.
- Semantiska modelluppdateringsåtgärder kan också vikas till den förbättrade beräkningsmotorn, vilket innebär att även inkrementell uppdatering från en semantisk modell kan vikas till ett dataflöde. Den här funktionen förbättrar uppdateringsprestandan och kan minska svarstiden mellan uppdateringscyklerna.
Om du vill aktivera den här funktionen för alla Premium-dataflöden kontrollerar du att beräkningsmotorn uttryckligen är inställd på På. Använd sedan dataflödesanslutningsappen i Power BI Desktop. Du måste använda augusti 2021-versionen av Power BI Desktop eller senare för att dra nytta av den här funktionen.
Om du vill använda den här funktionen för befintliga lösningar måste du ha en Premium- eller Premium-prenumeration per användare. Du kan också behöva göra vissa ändringar i dataflödet enligt beskrivningen i Använda den förbättrade beräkningsmotorn. Du måste uppdatera befintliga Power Query-frågor för att använda den nya anslutningsappen genom att PowerBI.Dataflows ersätta i avsnittet Källa med PowerPlatform.Dataflows.
Komplex dataflödesredigering i Power Query
Anta att du har ett dataflöde som är miljontals rader med data, men du vill skapa komplex affärslogik och omvandlingar med det. Du vill följa metodtipsen för att arbeta med stora dataflöden. Du behöver också dataflödesförhandsgranskningarna för att kunna utföra dem snabbt. Men du har dussintals kolumner och miljontals rader med data.
Lösning: Använd schemavyn
Du kan använda schemavyn, som är utformad för att optimera flödet när du arbetar med åtgärder på schemanivå genom att placera din frågas kolumninformation i centrum. Schemavyn innehåller kontextuella interaktioner för att forma din datastruktur. Schemavyn ger också åtgärder med kortare svarstid eftersom det bara kräver att kolumnmetadata beräknas och inte fullständiga dataresultat.
Arbeta med större datakällor
Anta att du kör en fråga i källsystemet, men du vill inte ge direkt åtkomst till systemet eller demokratisera åtkomsten. Du planerar att placera det i ett dataflöde.
Lösning 1: Använd en vy för frågan eller optimera frågan
Genom att använda en optimerad datakälla och fråga är det bästa alternativet. Ofta fungerar datakällan bäst med frågor som är avsedda för den. Power Query avancerar frågedelegeringsfunktioner för att delegera dessa arbetsbelastningar. Power BI innehåller även stegvisa indikatorer i Power Query Online. Läs mer om typer av indikatorer i dokumentationen för stegvisa indikatorer.
Lösning 2: Använd intern fråga
Du kan också använda funktionen Value.NativeQuery() M. Du anger EnableFolding=true i den tredje parametern. Intern fråga dokumenteras på den här webbplatsen för Postgres-anslutningsappen. Det fungerar också för SQL Server-anslutningsappen.
Lösning 3: Dela upp dataflödet i dataflöden för inmatning och förbrukning för att dra nytta av ECE och länkade entiteter
Genom att dela upp ett dataflöde i separata dataflöden för inmatning och förbrukning kan du dra nytta av ECE och länkade entiteter. Du kan lära dig mer om det här mönstret och andra i dokumentationen om bästa praxis.
Se till att kunderna använder dataflöden när det är möjligt
Anta att du har många dataflöden som har gemensamma syften, till exempel anpassade dimensioner som kunder, datatabeller, produkter och geografiska områden. Dataflöden är redan tillgängliga i menyfliksområdet för Power BI. Helst vill du att kunderna främst ska använda de dataflöden som du har skapat.
Lösning: Använd bekräftelse för att certifiera och höja upp dataflöden
Mer information om hur godkännande fungerar finns i Endorsement: Promoting and certifying Power BI content (Stöd: Främja och certifiera Power BI-innehåll).
Programmering och automatisering i Power BI-dataflöden
Anta att du har affärskrav för att automatisera importer, exporter eller uppdateringar samt mer orkestrering och åtgärder utanför Power BI. Du har några alternativ för att aktivera detta, enligt beskrivningen i följande tabell.
| Typ | Mekanism |
|---|---|
| Använd PowerAutomate-mallarna. | Ingen kod |
| Använd automationsskript i PowerShell. | Automatiseringsskript |
| Skapa din egen affärslogik med hjälp av API:erna. | Rest-API |
Mer information om uppdatering finns i Förstå och optimera uppdatering av dataflöden.
Se till att du skyddar datatillgångar nedströms
Du kan använda känslighetsetiketter för att tillämpa en dataklassificering och eventuella regler som du har konfigurerat för underordnade objekt som ansluter till dina dataflöden. Mer information om känslighetsetiketter finns i känslighetsetiketter i Power BI. Mer information om arv finns i Avsnittet om nedströmsarv för känslighetsetiketter i Power BI.
Stöd för multi-geo
Många kunder har idag ett behov av att uppfylla kraven på datasuveränitet och hemvist. Du kan slutföra en manuell konfiguration av din dataflödesarbetsyta för att vara multi-geo.
Dataflöden stöder multi-geo när de använder funktionen bring-your-own-storage-account. Den här funktionen beskrivs i Konfigurera dataflödeslagring för användning av Azure Data Lake Gen 2. Arbetsytan måste vara tom innan den ansluts för den här funktionen. Med den här specifika konfigurationen kan du lagra dataflödesdata i specifika geografiska områden som du väljer.
Se till att du skyddar datatillgångar bakom ett virtuellt nätverk
Många kunder har idag ett behov av att skydda dina datatillgångar bakom en privat slutpunkt. Det gör du genom att använda virtuella nätverk och en gateway för att hålla dig kompatibel. I följande tabell beskrivs det aktuella stöd för virtuella nätverk och hur du använder dataflöden för att hålla dig kompatibel och skydda dina datatillgångar.
| Scenario | Status |
|---|---|
| Läsa datakällor för virtuella nätverk via en lokal gateway. | Stöds via en lokal gateway |
| Skriv data till ett känslighetsetikettkonto bakom ett virtuellt nätverk med hjälp av en lokal gateway. | Stöds inte ännu |
Relaterat innehåll
Följande artiklar innehåller mer information om dataflöden och Power BI: