Ta med din egen Azure Data Lake Storage Gen2
Power Automate Process Mining ger dig möjlighet att lagra och läsa händelseloggdata direkt från Azure Data Lake Storage Gen2. Denna funktion förenklar extrahering, transformation, last (ETL) hantering genom att ansluta direkt till ditt lagringskonto.
Den här funktionen stöder för närvarande inmatning av följande:
-
CSV
- En CSV-filen.
- Mapp med flera CSV-filer som har samma struktur. Alla filer matas in.
-
Parquet
- En parquet-fil.
- Mapp med flera parquet-filer som har samma struktur. Alla filer matas in.
-
Delta-parquet
- Mapp som innehåller en delta-parquet.
Förutsättningar
Data Lake Storage-kontot måste vara Gen2. Du kan kolla upp detta från Azure-portalen. Azure Data Lake Gen1-lagringskonton stöds inte.
Data Lake Storage account måste ha hierarkisk namnrymd aktiverad.
Rollen Ägare måste tillskrivas användaren som utför den initiala konfigurationen av behållare för miljön för följande användare i samma miljö. Dessa användare ansluter till samma behållare och måste ha följande tilldelningar:
- Rollen Storage Blob Data-läsare eller Storage Blob Data-deltagare tilldelad
- Azure Resource Manager rollen Läsare tilldelas som minst.
Resursdelning (CORS) regel till ditt lagringskonto bör upprättas för att dela med Power Automate Process Mining.
Tillåtna ursprung måste anges till
https://make.powerautomate.comochhttps://make.powerapps.com.Tillåtna metoder måste innehålla:
get,options,put,post.Tillåtna rubriker bör vara så flexibla som möjligt. Vi rekommenderar att du definierar dem som
*.Visade rubriker bör vara så flexibla som möjligt. Vi rekommenderar att du definierar dem som
*.Maximal ålder ska vara så flexibel som möjligt. Vi rekommenderar att du använder
86400.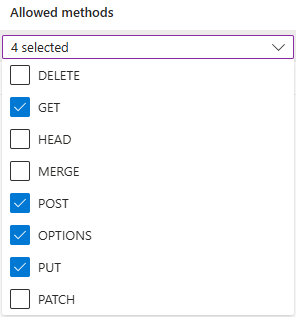
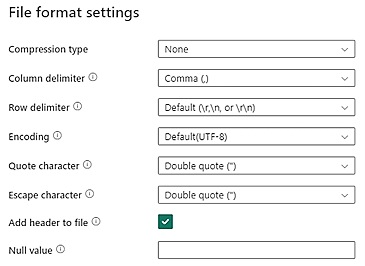
CSV-data i din Data Lake Storage bör uppfylla följande CSV-filformatskrav:
- Komprimeringstyp: Ingen
- Kolumnavgränsare: Komma (,)
- Radavgränsare: Standard och kodning. Till exempel, Standard (\r,\n eller \r\n)
Alla data måste vara i loggformat för den slutliga händelsen och uppfylla kraven som anges i datakraven. Data ska vara klara att mappas till schemat för processutvinning. Ingen dataomvandling är tillgänglig efter inmatning.
Storleken (bredden) på rubrikraden är för närvarande begränsad till 1 MB.
Viktigt!
Kontrollera att den tidstämpel som representeras i CSV-filen följer standardformatet ISO 8601 (till exempel YYYY-MM-DD HH:MM:SS.sss eller YYYY-MM-DDTHH:MM:SS.sss).
Ansluta till Azure Data Lake Storage
I navigeringsfönstret till vänster, välj Process Mining>Starta här.
I fältet Processnamn anger du namn på din process.
Under rubriken Datakälla, välj Importera data>Azure Data Lake>Fortsätt.

På skärmen Anslutningsinställningar, välj din Prenumerations-ID, Resursgrupp, Lagringskonto och Behållare från listrutorna.
Välj filen eller mappen som innehåller händelseloggdata.
Du kan antingen välja en enskild fil eller en mapp med flera filer. Alla filer måste ha samma rubriker och format.
Välj Nästa.
På skärmen Mappa data mappar du dina data till det schema som krävs.
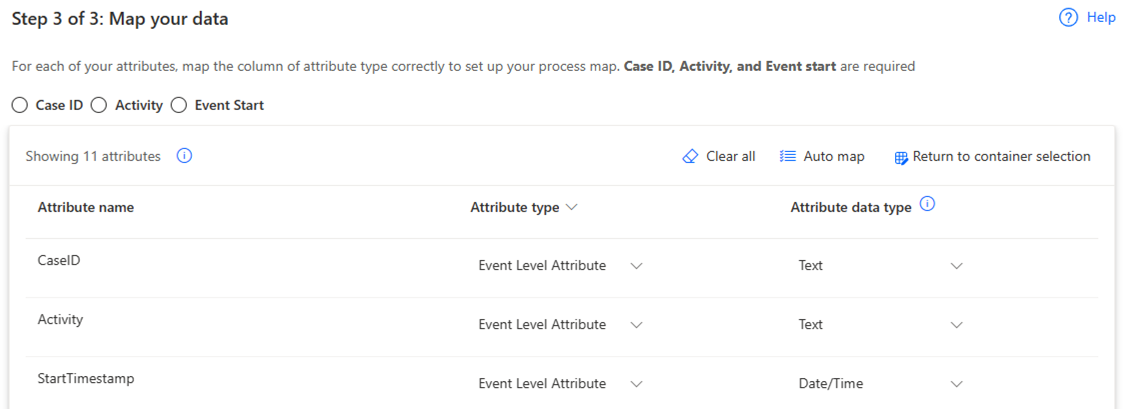
Slutför anslutningen genom att välja Spara och analysera.
Definiera inställningar för inkrementell datauppdatering
Du kan uppdatera en process som hämtas från Azure Data Lake enligt ett schema, antingen via en fullständig eller inkrementell uppdatering. Även om det inte finns några lagringsprinciper kan du mata in data stegvis med ett av följande sätt:
Om du valde en enskild fil i föregående avsnitt, lägg till mer data till den valda filen.
Om du valde en mapp i föregående avsnitt lägger du till inkrementella filer till den valda mappen.
Viktigt!
När du lägger till inkrementella filer till en vald mapp eller undermapp, se till att du anger ökade ordningen genom att namnge filer med datum som t.ex. YYYMMDD.csv eller YYYYMMDDHHMMSS.csv.
För att uppdatera en process:
Gå til sidan Detaljer i processen.
Välj uppdateringsinställningar.
På skärmen Schemalägg uppdatering, slutför följande steg:
- Aktivera växlingsknappen Håll data uppdaterade.
- I listrutan Uppdatera data varje väljer du frekvensen för uppdateringen.
- I fältet Starta den väljer du datum och tid för uppdateringen.
- Aktivera växlingsknappen Inkrementell uppdatering.