Översikt över grundorsaksanalys
Grundorsaksanalysen (RCA) låter dig hitta dolda anslutningar i dina data. Den hjälper dig till exempel att förstå varför vissa ärenden tar längre tid att slutföra än andra, eller varför vissa ärenden fastnar i omarbetningar medan andra fungerar som de ska. I RCA visas de viktigaste skillnaderna mellan sådana ärenden.
Obligatoriska data
RCA kan använda alla attribut, mått och anpassade mått på ärendenivå för att hitta anslutningar mellan dem, samt ett mått som du själv väljer.
Det bästa exemplet är att ta med alla data du kan som attribut på ärendenivå, och låta RCA välja vilket attribut som faktiskt påverkar måttet och vilket som inte gör det.
Så här fungerar RCA
RCA-algoritmen beräknar en trädstruktur där varje nod delar datauppsättningen i två mindre delar. Detta baseras på en variabel där bäst korrelation hittas mellan variabeldelningen och målmåttet. Ur detta kan du se de dolda anslutningarna i dina data. Det är här som du får information om vilken kombination av attribut som påverkar ärendet, och på vilket sätt.
Så här delar RCA bäst
Först genererar vi hundratals till tusentals kombinationer av möjliga delningar. Därefter försöker vi dela dem i syfte att upptäcka hur väl det faktiskt delar datauppsättningen i två delar. Vi beräknar variansen för huvudmåttet i varje del av delningen, samt beräknar poängen för varje delning med följande beräkning:
poängdelning_x = variansvänster * antal ärendenvänster + varianshöger * antal ärendenhöger
Därefter sorteras alla delar efter den här poängen och de bästa delningarna tas från början, med den lägsta poängen. För det kategoriska huvudmåttet (strängen) beräknar vi Gini-orenheter istället för varians.
RCA-exempel
I det här exemplet vill vi se grundorsaken till ärendevaraktigheten. I dessa data har vi attributen leverantörsland, leverantörsort, material,totalbelopp och kostnadscenter på ärendenivå. Genomsnittslängden för ärendet är 46 timmar.
Genom att titta på varje värde för varje attribut separat kan vi se att högst inverkan på ärendets varaktighet är när leverantörsort är Graz, vilket i genomsnitt ökar varaktigheten för ärendet med ytterligare 15 timmar. Ur denna inledande analys kan vi se att de andra attributvärdena påverkar målmåttet betydligt mindre. När vi beräknar trädmodellen kan vi emellertid se att beräkningen ovan är missvisande (som i följande skärmbild).
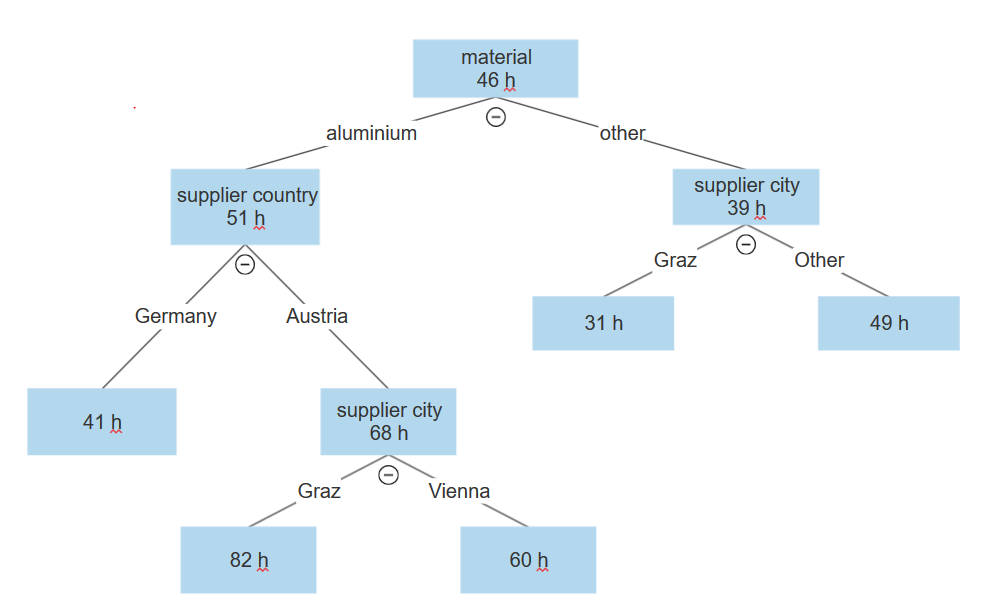
Trädstrukturen ser ut så här:
Den första delningen är data längs variabeln material. Datan med aluminium finns på ena sidan och allt övrigt material finns på den andra sidan.
Förgreningen aluminium delas upp ytterligare efter leverantörsland till Tyskland respektive Österrike.
Förgreningen Österrike fortsätter med en delning efter leverantörsort, med Graz å ena sidan och Wien å den andra.
I noden Graz var genomsnittsärendet 36 timmar jämfört med den totala genomsnittslängden på 46 timmar.
I samma träd kan vi se att om vi har ett annat material än aluminium så delas detta också med variabeln leverantörsort, dä Graz finns på ena sidan och Wien, München eller Frankfurt finns på den andra. Men här är värdena de motsatta. Graz har mycket bättre statistik än Wien eller någon annan tysk ort – genomsnittsärendet i Graz är 15 timmar snabbare än genomsnittet totalt för alla ärenden.
Av detta kan vi se att den inledande statistiken är missvisande, detta eftersom Graz presterar dåligt när materialet är aluminium – det presterar amellertid över genomsnittet när materialet är något annat än aluminium, och är raka motsatsen för andra städer.
Statistik rörande inflytande för ärendevaraktighet tar endast hänsyn till ett (1) värde och kan ibland vara missvisande. RCA tar hänsyn till kombinationer av dem för att ge dig bättre insikt i din process.