Utföra OCR på flerspråkiga dokument
Med hjälp av teckenidentifiering (OCR) kan du söka efter och extrahera text från bilder eller skärmen.
De flesta scenarier kräver att du hanterar text på ett visst språk, men det finns fall där källorna är flerspråkiga.
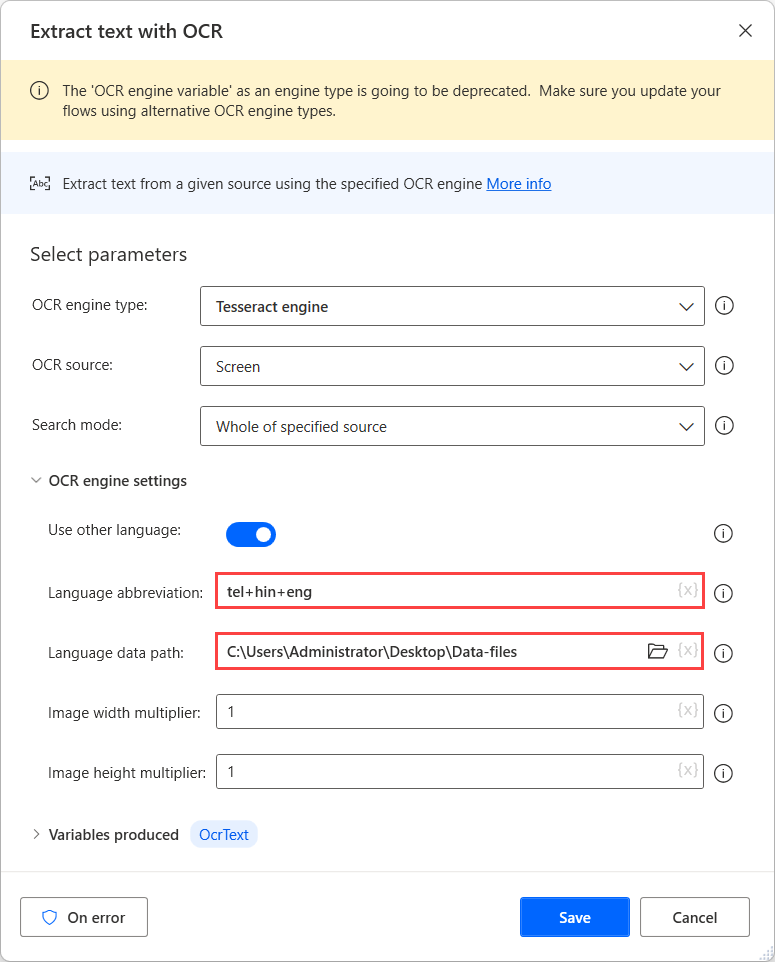
Om du vill utföra OCR på dessa källor använder du en Tesseract-motorn i respektive OCR-åtgärd och aktiverar alternativet Använd andra språk i motorns inställningar.
När alternativet Använd andra språk är aktiverat visas ytterligare två inställningar för åtgärden: fälten Språkförkortning och Sökväg till språkdata.
Fältet Språkförkortning anger för motorn vilket språk som ska sökas under OCR. Fältet Sökväg till språkdata innehåller språkdatafilerna (.traineddata) som används för att utbilda OCR-motorn.
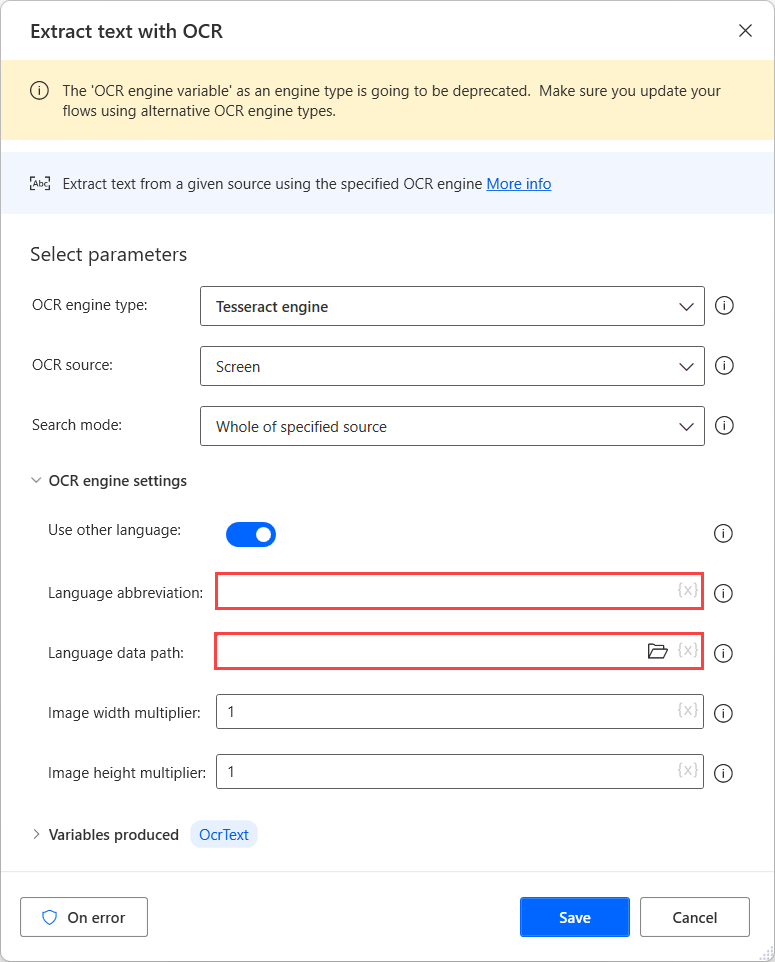
När du har hämtat datafilerna för de språk som behövs flyttar du dem till en gemensam mapp så att de blir tillgängliga under samma väg.
Markera sedan den skapade mappen i fältet Sökväg till språkdata och fyll i motsvarande språkkoder i fältet Språkförkortning. Om du vill separera språkkoderna använder du plustecknet (+).
Kommentar
Du hittar alla tillgängliga språkkoder i källan till språkdatafilerna. I följande exempel representerar de använda koderna telugu, hindi och engelska.