Använd en fördefinierad modell för att extrahera information från enkla dokument i Microsoft Syntex
Den enkla modellen för dokumentbearbetning erbjuder en flexibel, förtränad lösning för att extrahera information från grundläggande strukturerade dokument, inklusive information som:
Nyckel/värde-par – Tänk på dessa som etiketter och deras motsvarande information, till exempel "Namn: Adele Vance".
Markeringsmarkeringar – det här är kryssrutor eller andra märken som anger val eller val i ett dokument.
Namngivna entiteter – det här är specifika objekt som namn på personer, platser eller organisationer som nämns i texten i ett dokument.
Streckkoder – det här är maskinläsbara representationer av data som kan användas för spårning eller identifiering i ett dokument.
Till skillnad från andra fördefinierade modeller med fasta scheman kan den här modellen identifiera nycklar som andra kan missa, vilket ger ett värdefullt alternativ till anpassad modelletikett och träning. Den här modellen stöder även streckkoder och språkidentifiering.
Typer av dokument
Enkel dokumentbearbetning fungerar bäst med de typer av dokument som innehåller strukturerad information, till exempel:
Forms – Dessa har ofta tydliga fält och etiketter, vilket gör det enklare att extrahera nyckel/värde-par.
Fakturor – innehåller vanligtvis konsekventa layouter med tabeller och nyckel/värde-par.
Kvitton – på liknande sätt som fakturor har de strukturerade data som enkelt kan extraheras.
Contracts – innehåller väldefinierade avsnitt och satser som kan parsas effektivt.
Bankutdrag – Inkludera tabeller och strukturerade data som är idealiska för extrahering.
Dessa dokument drar nytta av funktionerna för optisk teckenigenkänning (OCR) och djupinlärningsprocesser som används för att extrahera nyckel/värde-par, urvalsmarkeringar, tabeller och namngivna entiteter.
Obs!
För närvarande är den här modellen tillgänglig för .pdf och bildfiltyper och på fler än 100 språk. Fler filtyper som stöds kommer att läggas till i framtida versioner.
Följ dessa steg om du vill använda en enkel modell för dokumentbearbetning:
- Steg 1: Skapa modellen
- Steg 2: Ladda upp en exempelfil som ska analyseras
- Steg 3: Välj extraktorer för din modell
- Steg 4: Tillämpa modellen
Steg 1: Skapa modellen
Följ anvisningarna i Skapa en modell i Syntex för att skapa en enkel modell för dokumentbearbetning. Fortsätt sedan med följande steg för att slutföra din modell.
Steg 2: Ladda upp en exempelfil som ska analyseras
På sidan Modeller går du till avsnittet Lägg till en fil som ska analyseras och väljer Lägg till en fil.
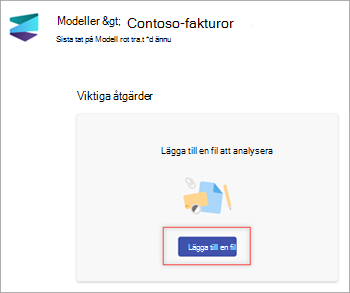
På sidan Filer för att analysera modellen väljer du Lägg till för att hitta den fil som du vill använda.
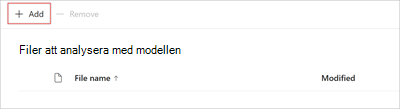
På sidan Lägg till en fil från bibliotekssidan för träningsfiler väljer du filen och väljer sedan Lägg till.
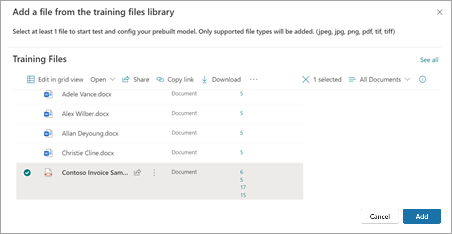
På sidan Filer för att analysera modellen väljer du Nästa.
Steg 3: Välj extraktorer för din modell
På sidan information om extraktor visas dokumentområdet till höger på sidan och panelen Extraherare till vänster. Panelen Extraherare visar listan över extraktorer som har identifierats i dokumentet.
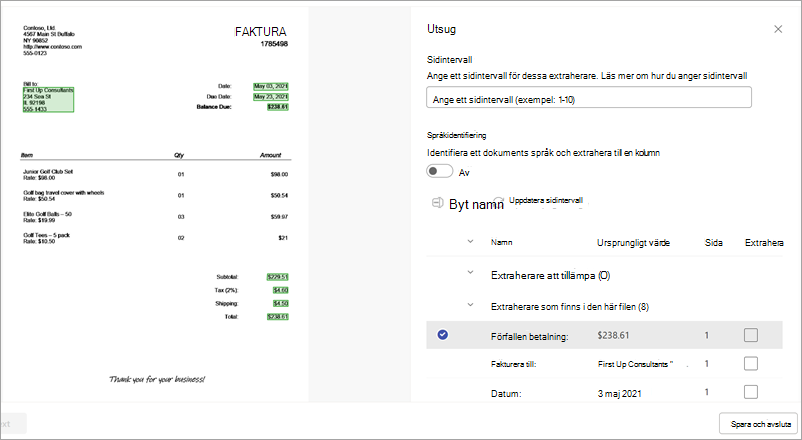
Entitetsfälten som är markerade i grönt i dokumentområdet är de objekt som identifierades av modellen när den analyserade filen. När du väljer en entitet att extrahera ändras det markerade fältet till blått. Om du senare bestämmer dig för att inte inkludera entiteten ändras det markerade fältet till grått. Markeringar gör det lättare att se det aktuella tillståndet för de extraktorer som du väljer.
Tips
Om du vill zooma in eller ut för att läsa entitetsfälten använder du musens rullningshjul eller zoomkontrollerna längst ned i dokumentområdet.
Välj en extraktorentitet
Du kan välja en extraktor antingen från dokumentområdet eller från panelen Extraktorer , beroende på vad du föredrar.
- Om du vill välja en extraktor från dokumentområdet väljer du entitetsfältet.
- Om du vill välja en extraktor från panelen Extraktorer markerar du motsvarande kryssruta till höger om entitetsnamnet i kolumnen Extrahera .
När du väljer en extraktor visas rutan Välj extraktor? i dokumentområdet. Rutan visar nyckelnamnet (namnet som genererades för extraktorn), det identifierade värdet (värdet för fältet i dokumentet), kolumntypen och alternativet att välja entiteten som extraktor.
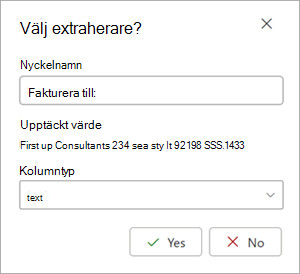
Nyckelnamnet används som kolumnnamn när modellen tillämpas på ett SharePoint-bibliotek. Du kan ändra nyckelnamnet så att det blir mer beskrivande om du vill. Kolumntypen visar hur informationen visas i ett bibliotek. Du kan ändra kolumntypen så att den visar hur du vill att informationen ska visas. När modellen tillämpas på ett bibliotek kan du använda kolumnformatering för att ange hur du vill att den ska se ut i dokumentet.
Fortsätt att välja andra extraktorer som du vill använda. Du kan också lägga till andra filer som ska analyseras för den här modellkonfigurationen.
Byta namn på en extraktor
Det finns tre sätt att byta namn på en extraktor:
I dokumentområdet på sidan med extraktorinformation väljer du entitetsfältet. I rutan Välj extraktor? i fältet Nyckelnamn anger du ett nytt namn för extraktorn.
På panelen Extraherare på sidan med extraheringsinformation väljer du den extraktor som du vill byta namn på och väljer sedan Byt namn.
På modellens startsida går du till avsnittet Extraherare , väljer den extraktor som du vill byta namn på och väljer sedan Byt namn.
Ange ett sidintervall för bearbetning
För den här modellen kan du ange att bearbeta ett intervall med sidor för en fil i stället för hela filen. I avsnittet Sidintervall på panelen Extraherare väljer du den sida som du vill bearbeta. Som standard är inställningen Sidintervall tom. Om inget sidintervall anges bearbetas hela dokumentet. Mer information finns i Ange ett sidintervall för att extrahera information från specifika sidor.
Identifiera språket i ett dokument
För den här modellen kan du identifiera språket i ett dokument och extrahera det till en kolumn. I avsnittet Språkidentifiering på panelen Extraktorer kan du aktivera språkidentifiering. Den visar ISO-koden för det identifierade språket.

Du kan också aktivera eller inaktivera språkidentifiering från panelen Modellinställningar för modellen.
Steg 4: Tillämpa modellen
Om du vill spara ändringar och återgå till modellens startsida går du till panelen Extraherareoch väljer Spara och avsluta.
Om du är redo att tillämpa modellen på ett bibliotek väljer du Nästa i dokumentområdet. På panelen Lägg till i bibliotek väljer du det bibliotek som du vill lägga till modellen i och väljer sedan Lägg till.