hll() (sammansättningsfunktion)
Gäller för: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Funktionen hll() är ett sätt att uppskatta antalet unika värden i en uppsättning värden. Det gör det genom att beräkna mellanliggande resultat för aggregering inom sammanfatta operatorn för en grupp med data med hjälp av funktionen dcount.
Läs mer om underliggande algoritmen (HyperLogLog) och uppskattningsnoggrannheten.
Not
Den här funktionen används tillsammans med operatorn summarize.
Syntax
hll
(
uttr [,noggrannhet])
Läs mer om syntaxkonventioner.
Parametrar
| Namn | Typ | Krävs | Beskrivning |
|---|---|---|---|
| uttr | string |
✔️ | Uttrycket som används för aggregeringsberäkningen. |
| noggrannhet | int |
Värdet som styr balansen mellan hastighet och noggrannhet. Om det är ospecificerat är standardvärdet 1. För värden som stöds, se Uppskattningsnoggrannhet. |
Returnerar
Returnerar mellanliggande resultat av distinkt antal uttr i gruppen.
Not
- Resultatet av hll(), hll_if() och hll_merge() kan lagras och hämtas senare. Du kanske till exempel vill skapa en daglig unik användarsammanfattning som sedan kan användas för att beräkna veckoantal. Den exakta binära representationen av dessa resultat kan dock ändras med tiden. Det finns ingen garanti för att dessa funktioner ger identiska resultat för identiska indata, och därför rekommenderar vi inte att du förlitar oss på dem.
- Använd funktionen hll_merge för att sammanfoga resultatet av flera
hll()funktioner. - Använd funktionen dcount_hll för att beräkna antalet distinkta värden från utdata från funktionerna
hll()ellerhll_merge.
Exempel
I följande exempel används funktionen hll() för att uppskatta antalet unika värden för kolumnen DamageProperty inom varje 10-minuters tidsintervall för kolumnen StartTime.
StormEvents
| summarize hll(DamageProperty) by bin(StartTime,10m)
utdata
Resultattabellen som visas innehåller endast de första 10 raderna.
| StartTime | hll_DamageProperty |
|---|---|
| 2007-01-01T00:20:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T01:00:00Z | [[1024,14],["7755241107725382121","-5665157283053373866","3803688792395291579","-1003235211361077779"],[]] |
| 2007-01-01T02:00:00Z | [[1024,14],["-1003235211361077779","-5665157283053373866","7755241107725382121"],[]] |
| 2007-01-01T02:20:00Z | [[1024,14],["7755241107725382121"],[]] |
| 2007-01-01T03:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T03:40:00Z | [[1024,14],["-5665157283053373866"],[]] |
| 2007-01-01T04:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T05:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T06:30:00Z | [[1024,14],["1589522558235929902"],[]] |
Uppskattningsnoggrannhet
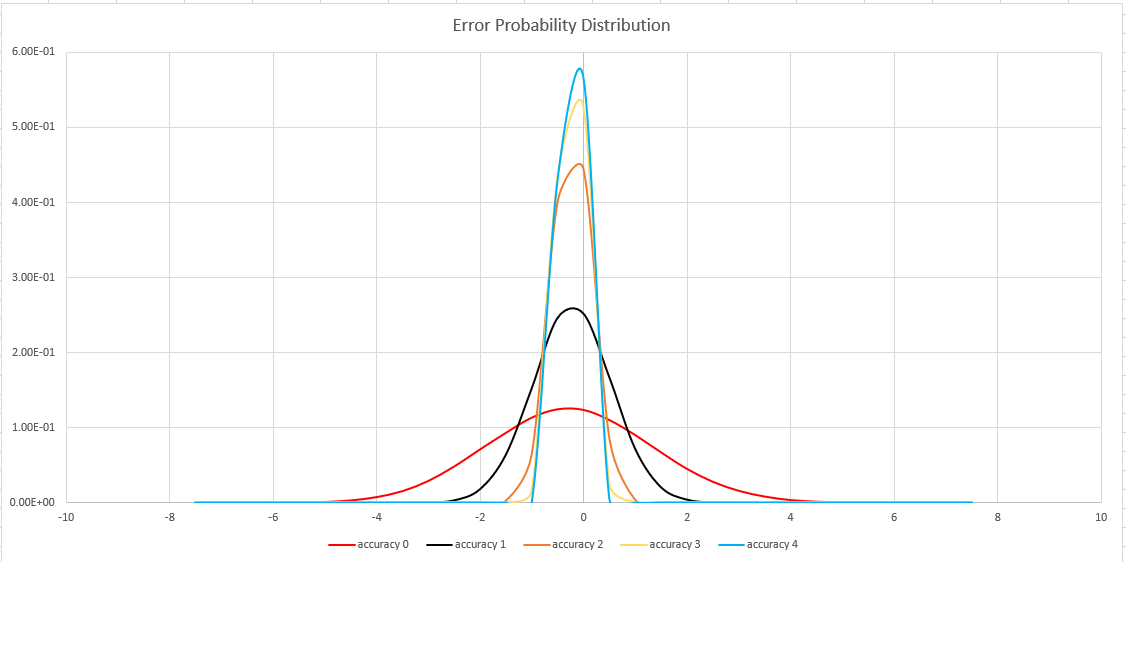
Den här funktionen använder en variant av algoritmen HyperLogLog (HLL), som gör en stokastisk uppskattning av uppsättningens kardinalitet. Algoritmen ger en "knopp" som kan användas för att balansera noggrannhet och körningstid per minnesstorlek:
| Noggrannhet | Fel (%) | Antal poster |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Not
Kolumnen "antal poster" är antalet 1 byte-räknare i HLL-implementeringen.
Algoritmen innehåller vissa bestämmelser för att göra ett perfekt antal (noll fel), om den inställda kardinaliteten är tillräckligt liten:
- När noggrannhetsnivån är
1returneras 1 000 värden - När noggrannhetsnivån är
2returneras 8 000 värden
Felgränsen är probabilistisk, inte en teoretisk bindning. Värdet är standardavvikelsen för felfördelningen (sigma) och 99,7% av uppskattningarna har ett relativt fel på under 3 x sigma.
Följande bild visar sannolikhetsfördelningsfunktionen för det relativa uppskattningsfelet, i procent, för alla noggrannhetsinställningar som stöds: