dcountif() (sammansättningsfunktion)
Gäller för: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Beräknar antalet distinkta värden för för rader där predikat utvärderas till true.
Null-värden ignoreras och tar inte hänsyn till beräkningen.
Not
Den här funktionen används tillsammans med operatorn summarize.
Syntax
dcountif
(
uttr, predikat, [,noggrannhet])
Läs mer om syntaxkonventioner.
Parametrar
| Namn | Typ | Krävs | Beskrivning |
|---|---|---|---|
| uttr | string |
✔️ | Uttrycket som används för aggregeringsberäkningen. |
| predikat | string |
✔️ | Uttrycket som används för att filtrera rader. |
| noggrannhet | int |
Kontrollen mellan hastighet och noggrannhet. Om det är ospecificerat är standardvärdet 1. Mer information om värden som stöds finns i Noggrannhet för uppskattning. |
Returnerar
Returnerar en uppskattning av antalet distinkta värden för uttr för rader där predikat utvärderas till true.
Dricks
dcountif() kan returnera ett fel i fall där alla eller ingen av raderna skickar Predicate-uttrycket.
Exempel
Det här exemplet visar hur många typer av dödliga stormhändelser som inträffat i varje tillstånd.
StormEvents
| summarize DifferentFatalEvents=dcountif(EventType,(DeathsDirect + DeathsIndirect)>0) by State
| where DifferentFatalEvents > 0
| order by DifferentFatalEvents
Resultattabellen som visas innehåller endast de första 10 raderna.
| Stat | DifferentFatalEvents |
|---|---|
| KALIFORNIEN | 12 |
| TEXAS | 12 |
| OKLAHOMA | 10 |
| ILLINOIS | 9 |
| KANSAS | 9 |
| NEW YORK | 9 |
| NEW JERSEY | 7 |
| WASHINGTON | 7 |
| MICHIGAN | 7 |
| MISSOURI | 7 |
| ... | ... |
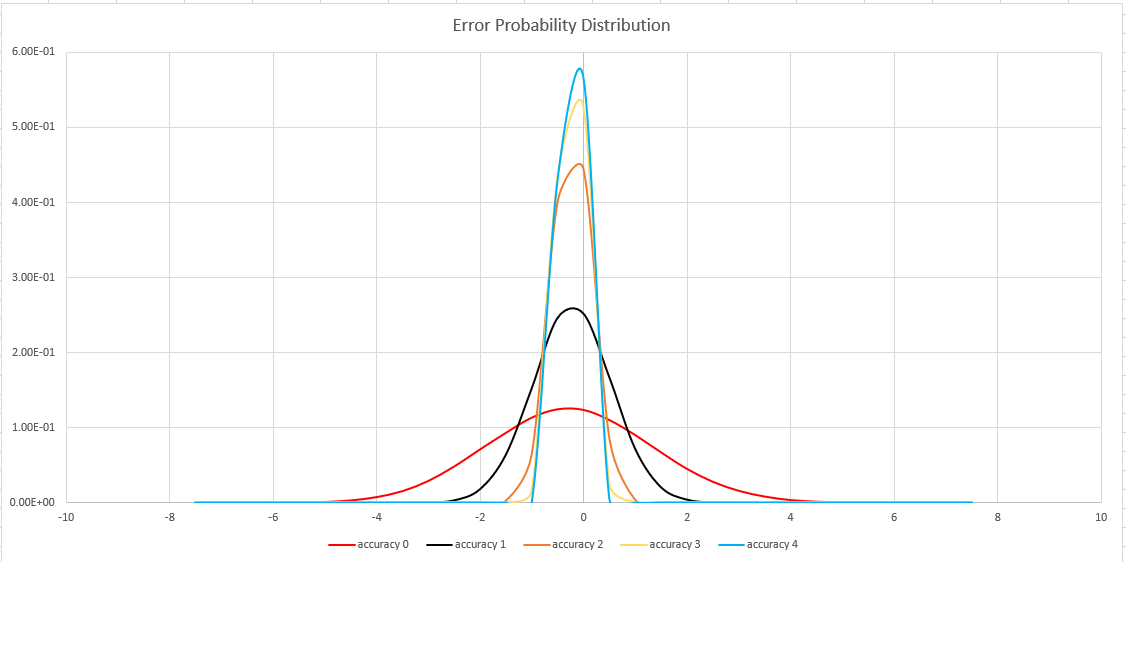
Uppskattningsnoggrannhet
Den här funktionen använder en variant av algoritmen HyperLogLog (HLL), som gör en stokastisk uppskattning av uppsättningens kardinalitet. Algoritmen ger en "knopp" som kan användas för att balansera noggrannhet och körningstid per minnesstorlek:
| Noggrannhet | Fel (%) | Antal poster |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Not
Kolumnen "antal poster" är antalet 1 byte-räknare i HLL-implementeringen.
Algoritmen innehåller vissa bestämmelser för att göra ett perfekt antal (noll fel), om den inställda kardinaliteten är tillräckligt liten:
- När noggrannhetsnivån är
1returneras 1 000 värden - När noggrannhetsnivån är
2returneras 8 000 värden
Felgränsen är probabilistisk, inte en teoretisk bindning. Värdet är standardavvikelsen för felfördelningen (sigma) och 99,7% av uppskattningarna har ett relativt fel på under 3 x sigma.
Följande bild visar sannolikhetsfördelningsfunktionen för det relativa uppskattningsfelet, i procent, för alla noggrannhetsinställningar som stöds: