Förbered offentliga datauppsättningar i SDOH-datauppsättningar – omvandlingar (förhandsversion)
[Denna artikel är en förhandsversion av dokumentationen och kan komma att ändras.]
SDOH offentliga datauppsättningar innehåller aggregerade data om sociala bestämningsfaktorer för hälsa (SDOH) som publicerats av myndigheter och andra officiella källor, t.ex. universitet. Dessa datauppsättningar konsoliderar olika SDOH-parametrar på geografiska nivåer, till exempel delstat, län eller postnummer. Med SDOH-datauppsättningar – Omvandlingar (förhandsversion) kan du mata in, lagra och analysera CSV-format (kommaavgränsade värden) eller XLSX-format (Excel Open XML-kalkylblad) och normalisera dem till en anpassad datamodell.
Förhandsversionen innehåller följande åtta exempel på SDOH-datauppsättningar från olika SDOH-domäner som hjälper dig att köra datapipelines och utforska dataomvandlingar genom sjölagren brons, silver och guld:
USDA Food Environment Atlas: Inkluderar faktorer som närhet till butik/restaurang, matpriser, näringshjälpsprogram och samhällsegenskaper. Dessa faktorer påverkar val av livsmedel, kostens kvalitet och i slutändan hälsoresultat.
USDA Rural Atlas: Erbjuder statistik om socioekonomiska faktorer som människor, jobb, länsklassificeringar, inkomst och veteraner.
AHRQ SDOH Data: Ger information om fem viktiga SDOH-domäner:
- Social kontext, t.ex. ålder, ras/etnicitet, veteranstatus.
- Ekonomiskt sammanhang, t.ex. inkomst, arbetslöshet.
- Utbildning
- Fysisk infrastruktur, t.ex. bostäder, brottslighet, transporter.
- Hälso- och sjukvårdssammanhang, till exempel sjukförsäkring.
Index för platsöverkomlighet: Uppskattar hushållens boende- och transportkostnader på grannskapsnivå.
Miljörättviseindex: Sammanställer data från flera källor för att rangordna de kumulativa effekterna av miljöorättvisor på hälsan för varje folkräkningsområde.
Utbildningsnivå enligt ACS: Ger utbildningsinsikter för geografiska områden, härledda från en stor, pågående demografisk undersökning.
Australian SEIFA: Kombinerar australiska folkräkningsdata som inkomst, utbildning, sysselsättning och bostäder för att sammanfatta ett områdes socioekonomiska egenskaper.
U.K. Indices of Deprivation: Ett allmänt använt socioekonomiskt mått i Storbritannien för att mäta fattigdom i små områden, som täcker olika dimensioner.
Där:
- USDA: Förenta staternas jordbruksdepartement
- AHRQ: Myndigheten för hälso- och sjukvårdsforskning och kvalitet
- ACS: Amerikansk samhällsundersökning
- SEIFA: Socioekonomiska index för områden
Viktigt
Dessa datauppsättningar är inte bara exempel utan fullständiga, verkliga datauppsättningar som publicerats av respektive organisation. De ger en korrekt representation av SDOH-profilerna för sina geografiska områden. Var försiktig när du ändrar dem, eftersom de är officiella publikationer från federala myndigheter.
Mappstruktur
Landningszonen för SDOH-datauppsättningar – Omvandlingar (förhandsversion) består av tre mappar: Mata in, Process och Misslyckad. Mer information om dessa mappar finns i Struktur för enhetliga mappar.
Förbereda SDOH-datauppsättningarna före inmatning
Innan du matar in offentliga SDOH-datauppsättningar bör du se till att de är redo för lyckad inmatning. Följande avsnitt beskriver två scenarier:
- Använd din egen datauppsättning
- Använd exempeldatauppsättning
Använd din egen datauppsättning
Offentliga SDOH-datauppsättningar varierar avsevärt mellan olika publiceringsorganisationer i format, volym och struktur. De saknar en etablerad standard för att samla in och utbyta den insamlade informationen. Därför är det viktigt att förena dem till en gemensam form innan du representerar dem i en datamodell.
Om du vill mata in och omvandla en offentlig SDOH-datauppsättning lägger du till följande tre viktiga informationsdelar i dem:
Layout: På grund av avsaknaden av en standarduppsättning koder för att avbilda SDOH-data är det svårt att förstå innebörden av varje fält. Lös problemet genom att skapa en dataordlista för datauppsättningen genom att lägga till ett nytt blad med namnet Layout (om datauppsättningen är i XLSX-format) eller skapa en ny CSV-fil (om datauppsättningen är i CSV-format) med kolumnerna som visas i följande exempel:
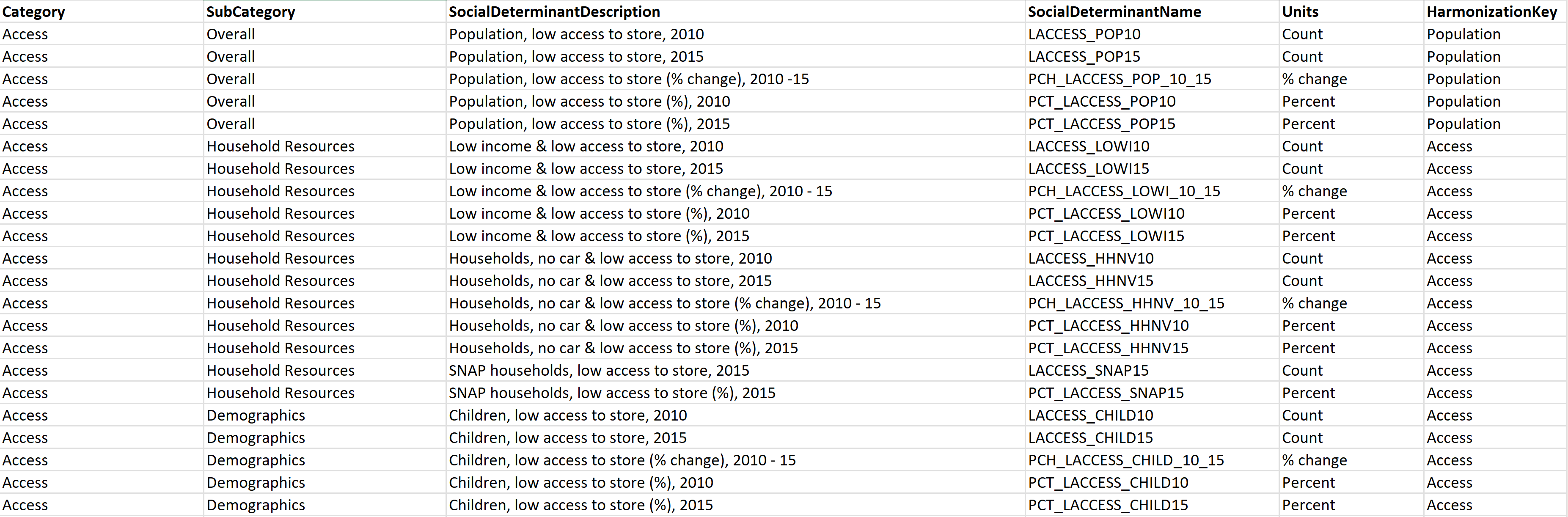
DataSetMetadata: Eftersom SDOH-datauppsättningar kommer från olika utgivare är det viktigt att registrera viktig information om datauppsättningen. Lägg till ett nytt blad med namnet DataSetMetadata (om datauppsättningen är i XLSX-format) eller skapa en ny CSV-fil (om datauppsättningen är i CSV-format) med kolumnerna som visas i följande exempel:

LocationConfiguration: Olika geografiska områden definierar och organiserar platsdata på olika sätt. För att hjälpa SDOH-pipelines att förstå datauppsättningens geografiska struktur lägger du till ett nytt blad med namnet LocationConfiguration (om datauppsättningen är i XLSX-format) eller skapar en ny CSV-fil (om datauppsättningen är i CSV-format) med kolumnerna som visas i följande exempel:
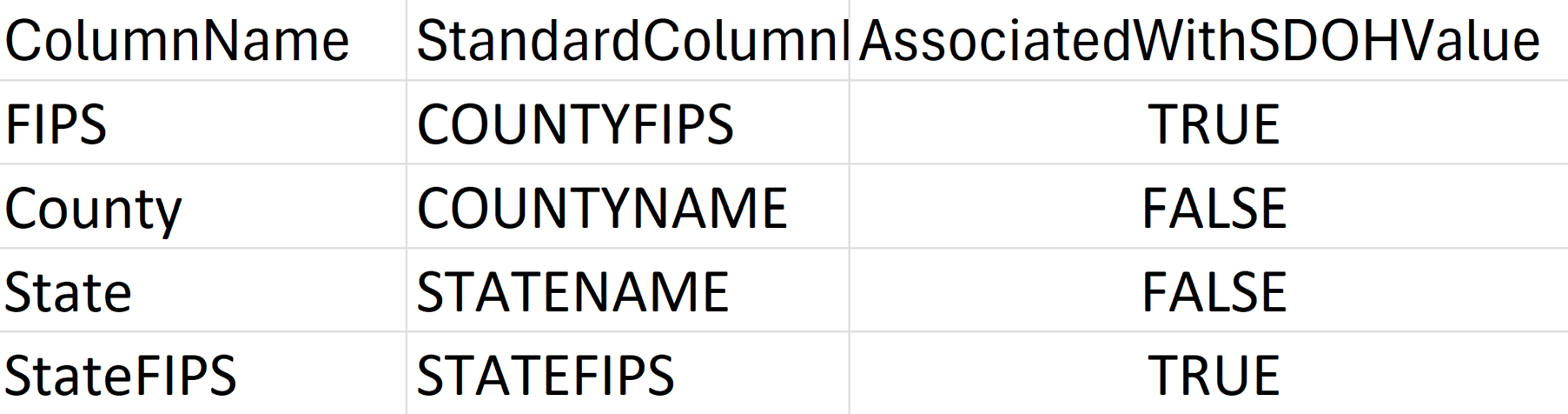



Också:
- Du kan referera till strukturen för SDOH-exempeldatauppsättningarna för att fylla i nödvändig information, till exempel social determinantkategori, metadata och harmoniseringsnyckel.
- Om du föredrar att inte importera vissa fält från den ursprungliga datauppsättningen kan du antingen ta bort dem från databladet eller lämna deras information tom i layoutbladet. I båda fallen ingår de inte i silverdatamodellen.
- Datauppsättningar med samma namn, publiceringsdatum och utgivare behandlas som dubbletter.
Använd exempeldatauppsättning
SDOH-exempeldatauppsättningarna som tillhandahålls med vårddatalösningar är förifyllda med all nödvändig information och är tillgängliga i din OneLake. Du kan extrahera dem lokalt.
Ladda upp datauppsättningar till Fabric-arbetsytan
När datauppsättningarna är klara väljer du något av följande två alternativ för att ladda upp dem. Du kan bara använda alternativ 2 om du använder exempeldatauppsättningen som medföljer SDOH-datauppsättningar – Omvandlingar (förhandsversion).
- Alternativ 1: Ladda upp datauppsättningarna manuellt.
- Alternativ 2: Använd ett skript för att ladda upp datauppsättningarna.
Ladda upp datauppsättningarna manuellt
I din miljö för vårddatalösningar, välj sjöhuset healthcare#_msft_bronze.
Öppna mappen Mata in. Mer information finns i Mappbeskrivningar
Välj ellipsen (...) bredvid mappnamnet och välj Ladda upp mapp.
Ladda upp datauppsättningarna från ditt lokala system. Använd OneLake-utforskaren för att hitta datauppsättningarna i följande sökväg:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset.Uppdatera mappen Mata in. Nu bör du se datauppsättningsfilerna i SDOH-undermappen.
Använd ett skript för att ladda upp datauppsättningarna
Viktigt
Använd bara det här alternativet om du använder den angivna exempeldatauppsättningen.
Gå till dina vårddatalösningar i Fabric-arbetsytan.
Välj + Ny artikel.
I fönstret Nytt objekt söker du efter och väljer Notebook.
Kopiera följande kodavsnitt till notebook:
workspace_name = '<workspace_name>' # workspace name one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint solution_name = "<solution_name>" # solution name bronze_lakehouse_name = "<bronze_lakehouse_name>" # bronze lakehouse name def copy_source_files_and_folders(source_path, destination_path): source_contents = mssparkutils.fs.ls(source_path) # list the source directory contents # list the destination directory contents try: if mssparkutils.fs.exists(destination_path): destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} else: print(f"Destination path {destination_path} does not exist.") destination_files = {} except Exception as e: print(f" Error: {str(e)}") destination_files = {} # copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" # recursively copy the contents of the directory if item.isDir: copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_name}@{one_lake_endpoint}/{solution_name}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/XLSX" # copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)Kör notebook. De SDOH exempeldatauppsättningarna flyttas nu till den angivna platsen i mappen Inmatning.
SDOH-datauppsättningarna är nu klara för inmatning.