Multivariat avvikelseidentifiering
Allmän information om multivariatavvikelseidentifiering i realtidsinformation finns i Multivariate anomaly detection in Microsoft Fabric – overview (Multivariate anomaly detection in Microsoft Fabric – overview). I den här handledningen använder du exempeldata för att träna en multivariat avvikelseidentifieringsmodell med hjälp av Spark-motorn i en Python-anteckningsbok. Sedan förutsäger du avvikelser genom att tillämpa den tränade modellen på nya data med hjälp av Eventhouse-motorn. De första stegen konfigurerar dina miljöer och följande steg tränar modellen och förutsäger avvikelser.
Förutsättningar
- En arbetsyta med en Microsoft Fabric-aktiverad kapacitet
- Rollen administratör, deltagare eller medlemi arbetsytan. Den här behörighetsnivån krävs för att skapa objekt som en miljö.
- Ett eventhouse på din arbetsyta med en databas.
- Ladda ned exempeldata från GitHub-lagringsplatsen
- Ladda ned anteckningsboken från GitHub-lagringsplatsen
Del 1 – Aktivera OneLake-tillgänglighet
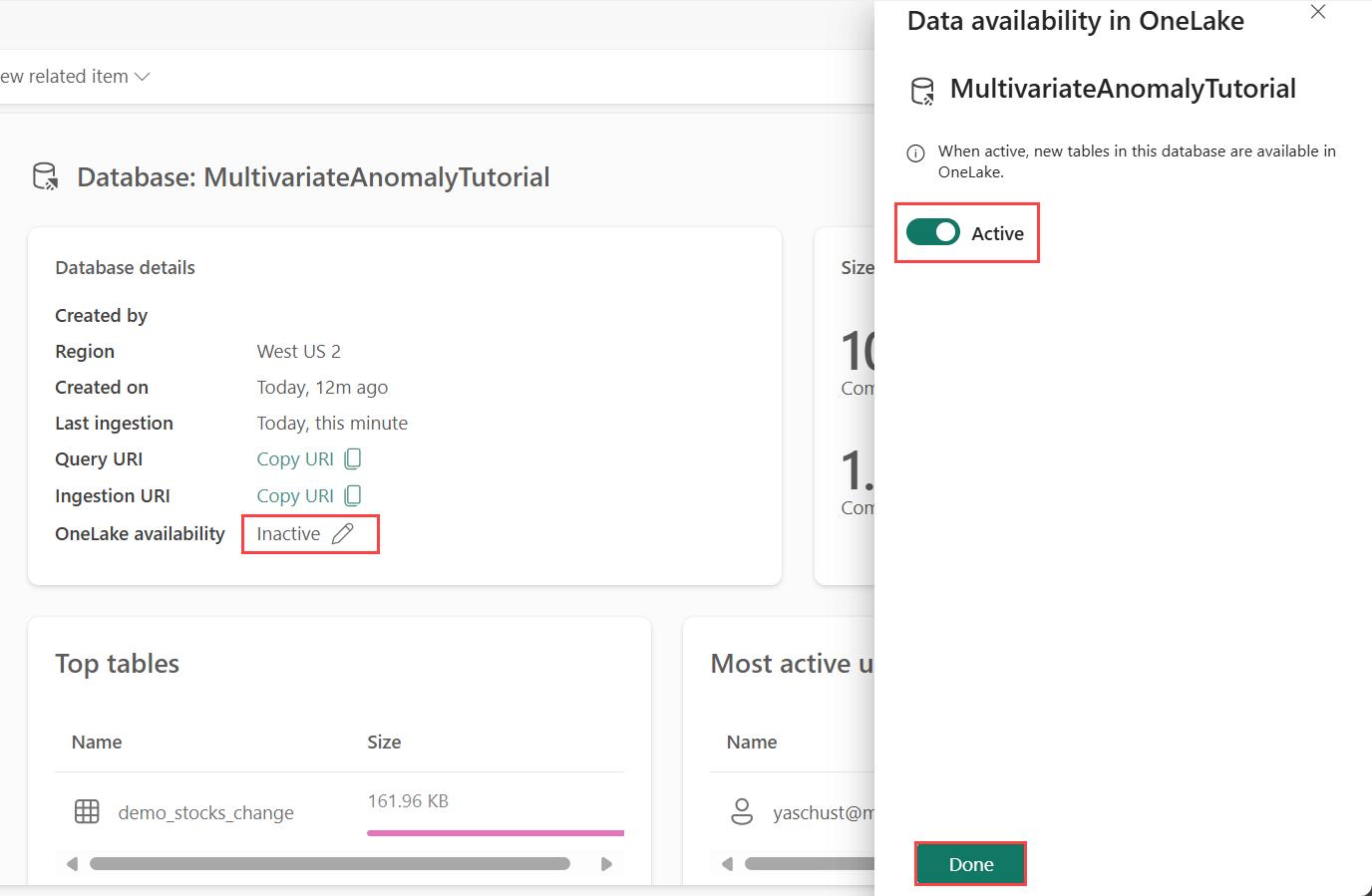
OneLake-tillgänglighet måste vara aktiverat innan du hämtar data i Eventhouse. Det här steget är viktigt eftersom det gör att de data du matar in blir tillgängliga i OneLake. I ett senare steg får du åtkomst till samma data från din Spark Notebook för att träna modellen.
Från arbetsytan väljer du det Eventhouse som du skapade i förutsättningarna. Välj den databas där du vill lagra dina data.
I fönstret Databasinformation växlar du knappen för OneLake-tillgänglighet till På.
Del 2 – Aktivera KQL Python-plugin-program
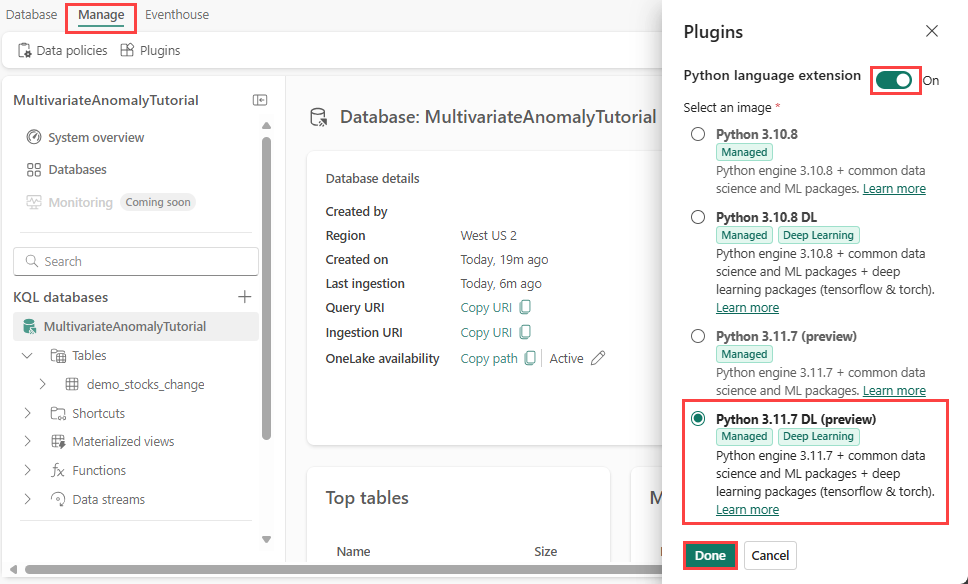
I det här steget aktiverar du python-plugin-programmet i Eventhouse. Det här steget krävs för att köra Python-koden predict anomalies i KQL-frågeuppsättningen. Det är viktigt att välja rätt bild som innehåller tidsserie-anomali-detektor paket.
På skärmen Eventhouse väljer du Eventhouse>Plugins i menyfliksområdet.
I fönstret Plugin-program växlar du Python-språktillägget tillPå.
Välj Python 3.11.7 DL (förhandsversion).
Välj Klar.

Del 3 – Skapa en Spark-miljö
I det här steget skapar du en Spark-miljö för att köra Python-notebook-filen som tränar modellen för multivariatavvikelseidentifiering med Spark-motorn. Mer information om hur du skapar miljöer finns i Skapa och hantera miljöer.
På arbetsytan väljer du + Nytt objekt och sedan Miljö.
Ange namnet MVAD_ENV för miljön och välj sedan Skapa.
I miljöfliken Start väljer du Runtime>1.2 (Spark 3.4, Delta 2.4).
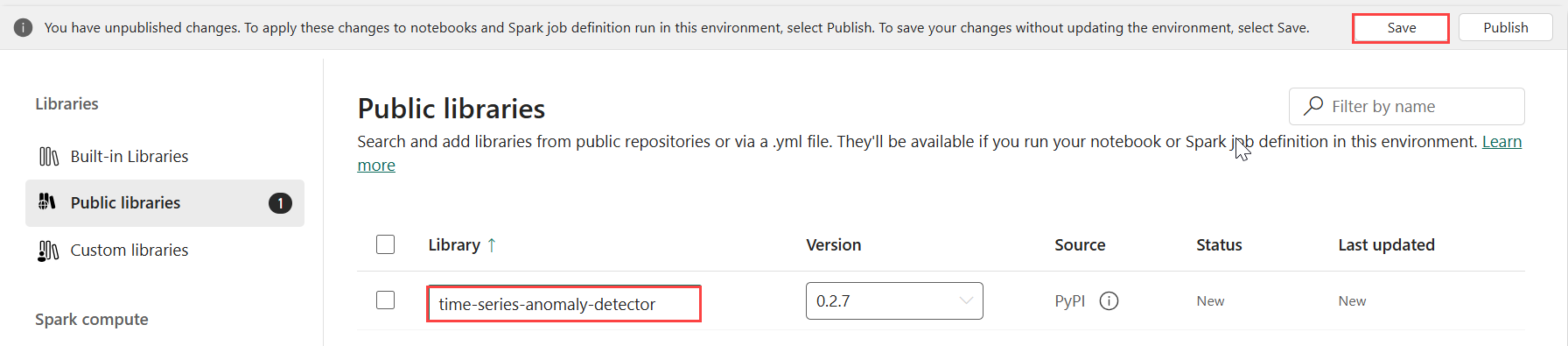
Under Bibliotek väljer du Offentliga bibliotek.
Välj Lägg till från PyPI.
I sökrutan anger du time-series-anomaly-detector. Versionen fylls automatiskt i med den senaste versionen. Den här handledningen skapades med version 0.3.2.
Välj Spara.
Välj fliken Start i miljön.
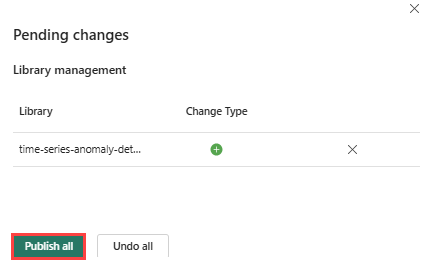
Välj ikonen Publicera i menyfliksområdet.

Markera Publicera alla. Det här steget kan ta flera minuter att slutföra.


Del 4 – Hämta data till Eventhouse
Hovra över den KQL-databas där du vill lagra dina data. Välj menyn Mer [...]>Hämta data>Lokal fil.
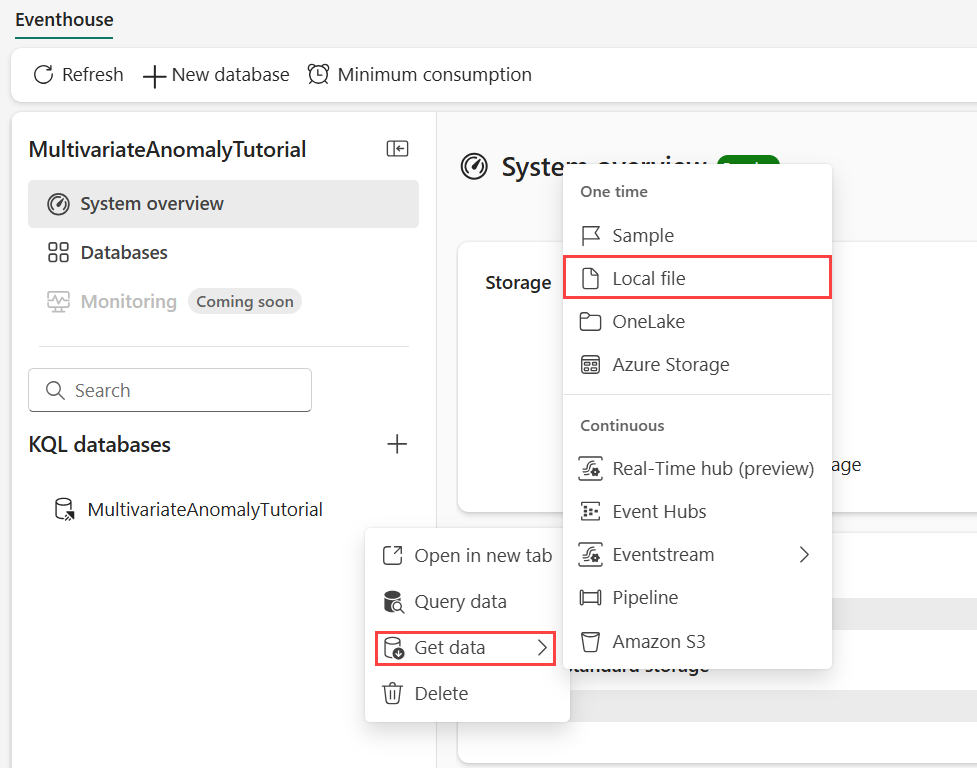
Välj + Ny tabell och ange demo_stocks_change som tabellnamn.
I dialogrutan ladda upp data väljer du Bläddra efter filer och laddar upp exempeldatafilen som laddades ned i förutsättningar
Välj Nästa.
I avsnittet Inspektera data växlar du Första raden är kolumnrubrik till På.
Välj Slutför.
När data laddas upp väljer du Stäng.
Del 5 – Kopiera OneLake-sökväg till tabellen
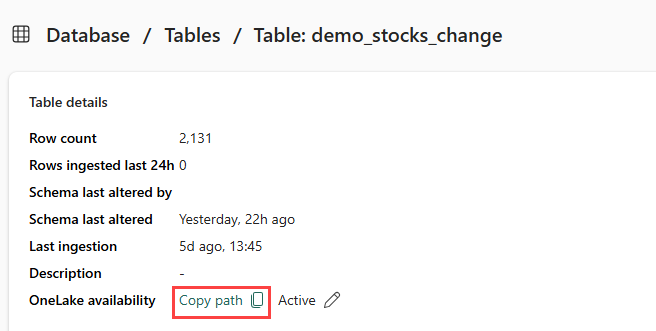
Kontrollera att du väljer tabellen demo_stocks_change . I fönstret Tabellinformation väljer du OneLake-mapp för att kopiera OneLake-sökvägen till Urklipp. Spara den kopierade texten i en textredigerare någonstans som ska användas i ett senare steg.
Del 6 – Förbereda anteckningsboken
Välj din arbetsyta.
Välj Importera, Notebook och sedan Från den här datorn.
Välj Ladda upp och välj den notebook-fil som du laddade ned i förutsättningarna.
När anteckningsboken har laddats upp kan du hitta och öppna anteckningsboken från arbetsytan.
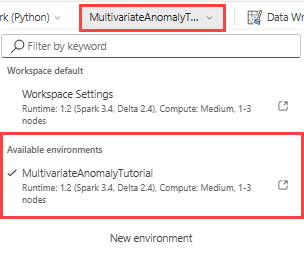
I det övre menyfliksområdet väljer du listrutan Arbetsyta som standard och väljer den miljö som du skapade i föregående steg.
Del 7 – Kör notebook-filen
Importera standardpaket.
import numpy as np import pandas as pdSpark behöver en ABFSS-URI för att ansluta säkert till OneLake-lagring, så nästa steg definierar den här funktionen för att konvertera OneLake-URI:n till ABFSS-URI:n.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriErsätt platshållaren OneLakeTableURI med din OneLake-URI kopierad från del 5 – Kopiera OneLake-sökvägen till tabellen för att läsa in demo_stocks_change tabell i en Pandas-dataram.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Kör följande celler för att förbereda dataramarna för träning och förutsägelse.
Kommentar
De faktiska förutsägelserna körs på data av Eventhouse i del 9– Predict-anomalies-in-the-kql-queryset. I ett produktionsscenario, om du strömmade data till händelsehuset, skulle förutsägelserna göras på nya strömmande data. I självstudien har datamängden delats upp efter datum i två avsnitt för träning och förutsägelse. Detta är för att simulera historiska data och nya strömmande data.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Kör cellerna för att träna modellen och spara den i fabric MLflow-modellregistret.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Kör följande cell för att extrahera den registrerade modellsökvägen som ska användas för prediktering med Kusto Python-sandbox-miljön.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Kopiera modell-URI:n från den sista cellens utdata för användning i ett senare steg.
Del 8 – Konfigurera din KQL-frågeuppsättning
Allmän information finns i Skapa en KQL-frågeuppsättning.
- Från arbetsytan väljer du +Nytt objekt>KQL Queryset.
- Ange namnet MultivariateAnomalyDetectionTutorialoch välj sedan Skapa.
- I fönstret OneLake-datahubben väljer du den KQL-databas där du lagrade data.
- Välj Anslut.
Del 9 – Förutsäga avvikelser i KQL-frågeuppsättningen
Kör följande ".create-or-alter-funktion"-fråga för att definiera den
predict_fabric_mvad_fl()lagrade funktionen:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Kör följande förutsägelsefråga och ersätt utdatamodellens URI med den URI som kopierades i slutet av steg 7.
Frågan identifierar multivarierade avvikelser på de fem lagren, baserat på den tränade modellen, och renderar resultatet som
anomalychart. De avvikande punkterna återges på det första beståndet (AAPL), även om de representerar avvikelser med flera avvikelser (med andra ord avvikelser i de gemensamma ändringarna av de fem lagren under det specifika datumet).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Det resulterande avvikelsediagrammet bör se ut som följande bild:

Rensa resurser
När du är klar med självstudien kan du ta bort resurserna, som du har skapat för att undvika andra kostnader. Följ dessa steg för att ta bort resurserna:
- Bläddra till arbetsytans startsida.
- Ta bort miljön som skapades i den här självstudien.
- Ta bort anteckningsboken som skapades i den här självstudien.
- Ta bort händelsehuset eller databasen som används i den här självstudien.
- Ta bort KQL-frågeuppsättningen som skapades i den här självstudien.