Hämta data från Apache Spark
Apache Spark är en enhetlig analysmotor för storskalig databearbetning.
Kusto-anslutningsappen för Spark är ett öppen källkod projekt som kan köras på alla Spark-kluster. Den implementerar datakälla och datamottagare för att flytta data över Azure Data Explorer och Spark-kluster. Med hjälp av en Eventhouse och Apache Spark kan du skapa snabba och skalbara program som riktar sig till datadrivna scenarier. Till exempel maskininlärning (ML), Extract-Transform-Load (ETL) och Log Analytics. Med anslutningsappen blir Eventhouses ett giltigt datalager för vanliga Spark-käll- och mottagaråtgärder, till exempel skrivning, läsning och writeStream.
Du kan skriva till Eventhouse via köad inmatning eller strömmande inmatning. Läsning från Eventhouses stöder kolumnrensning och predikat-pushdown, vilket filtrerar data i Eventhouse, vilket minskar mängden överförda data.
Den här artikeln beskriver hur du installerar och konfigurerar Spark-anslutningsappen och flyttar data mellan ett Eventhouse- och Apache Spark-kluster.
Kommentar
Även om några av exemplen nedan refererar till ett Azure Databricks Spark-kluster, tar Spark-anslutningsappen inte direkta beroenden för Databricks eller någon annan Spark-distribution.
Förutsättningar
- En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto. Detta används för autentisering med hjälp av Microsoft Entra-ID.
- En KQL-databas i Microsoft Fabric. Kopiera URI:n för den här databasen med hjälp av anvisningarna i Access an existing KQL database (Åtkomst till en befintlig KQL-databas).
- Ett Spark-kluster
- Installera anslutningsbiblioteket:
- Fördefinierade bibliotek för Spark 2.4+Scala 2.11 eller Spark 3+scala 2.12
- Maven-lagringsplats
- Maven 3.x installerat
Dricks
Spark 2.3.x-versioner stöds också, men kan kräva vissa ändringar i pom.xml beroenden.
Så här skapar du Spark-anslutningsappen
Från och med version 2.3.0 introducerar vi nya artefakt-ID:n som ersätter spark-kusto-connector: kusto-spark_3.0_2.12 med inriktning på Spark 3.x och Scala 2.12.
Kommentar
Versioner före 2.5.1 fungerar inte längre för inmatning till en befintlig tabell. Uppdatera till en senare version. Steget är valfritt. Om du använder fördefinierade bibliotek, till exempel Maven, kan du läsa Konfiguration av Spark-kluster.
Byggkrav
Se den här källan för att skapa Spark Connector.
För Scala-/Java-program som använder Maven-projektdefinitioner länkar du ditt program med den senaste artefakten. Hitta den senaste artefakten på Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Om du inte använder fördefinierade bibliotek måste du installera biblioteken som anges i beroenden , inklusive följande Kusto Java SDK-bibliotek . Om du vill hitta rätt version att installera kan du titta i den relevanta versionens pom:
Så här skapar du jar och kör alla tester:
mvn clean package -DskipTestsOm du vill skapa jar-filen kör du alla tester och installerar jar-filen på din lokala Maven-lagringsplats:
mvn clean install -DskipTests
Mer information finns i Användning av anslutningsappar.
Konfiguration av Spark-kluster
Kommentar
Vi rekommenderar att du använder den senaste versionen av Kusto Spark-anslutningsappen när du utför följande steg.
Konfigurera följande Spark-klusterinställningar baserat på Azure Databricks-klustret Spark 3.0.1 och Scala 2.12:
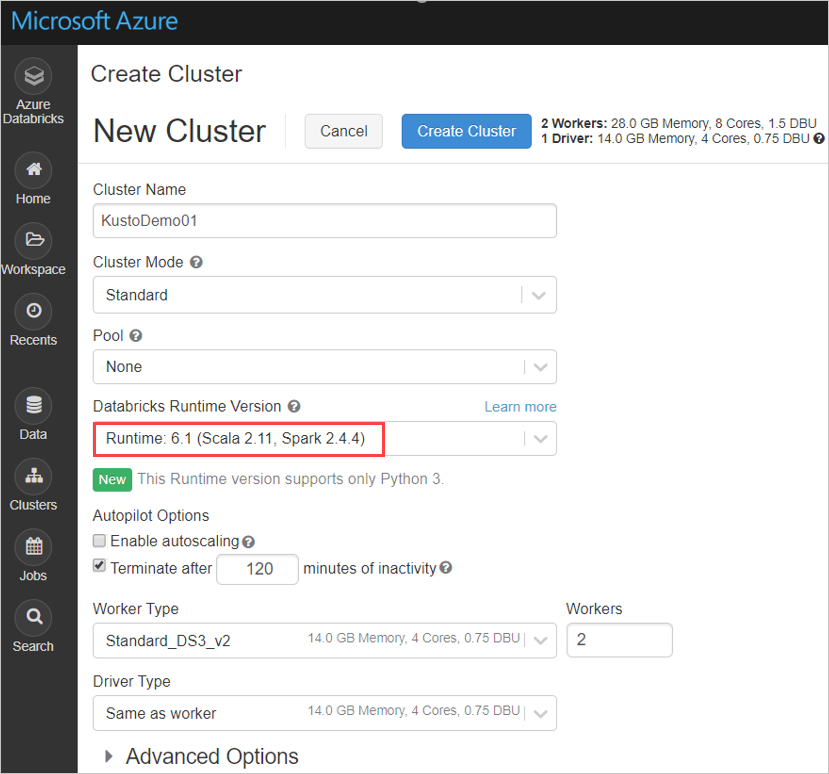
Installera det senaste spark-kusto-connector-biblioteket från Maven:
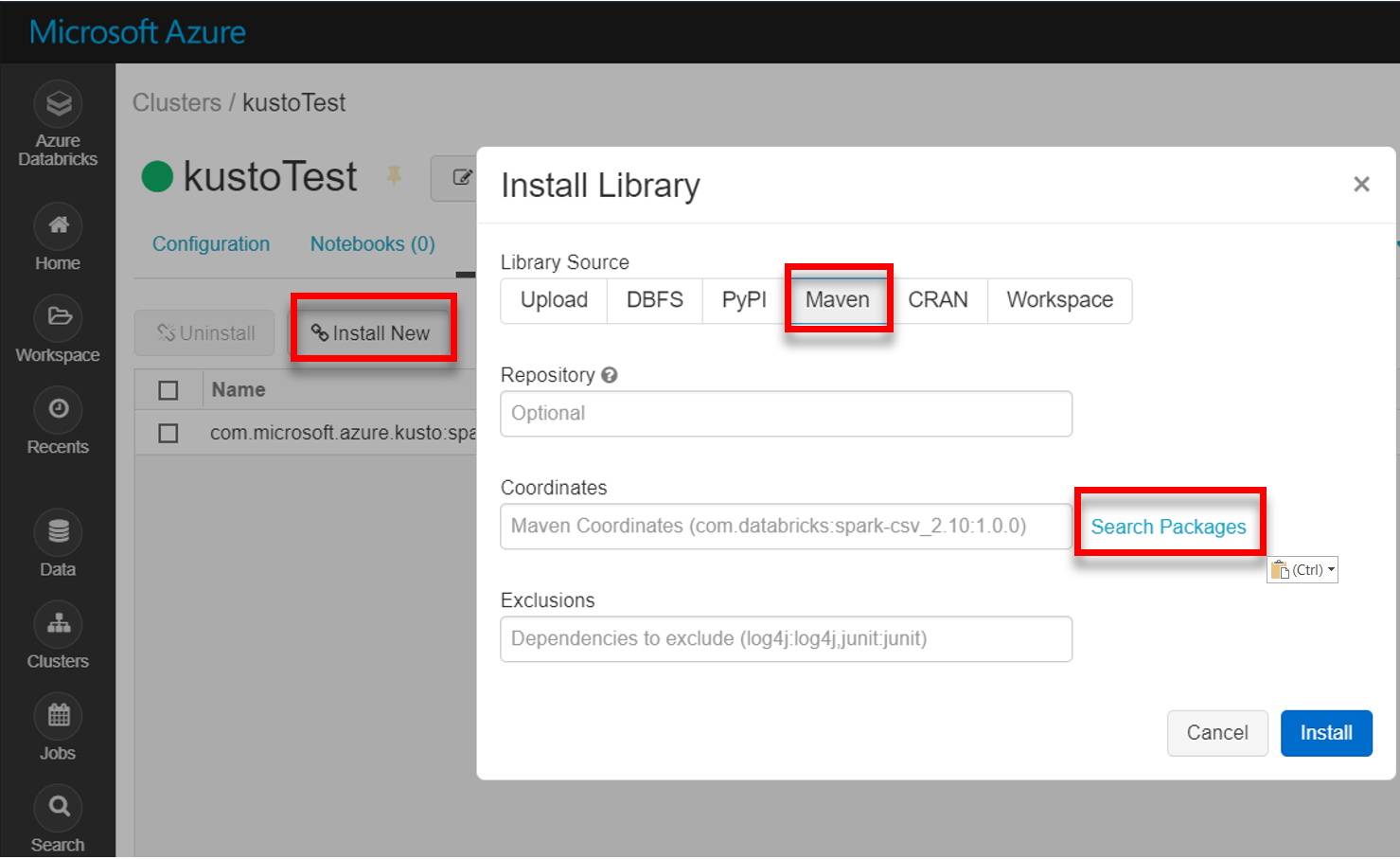
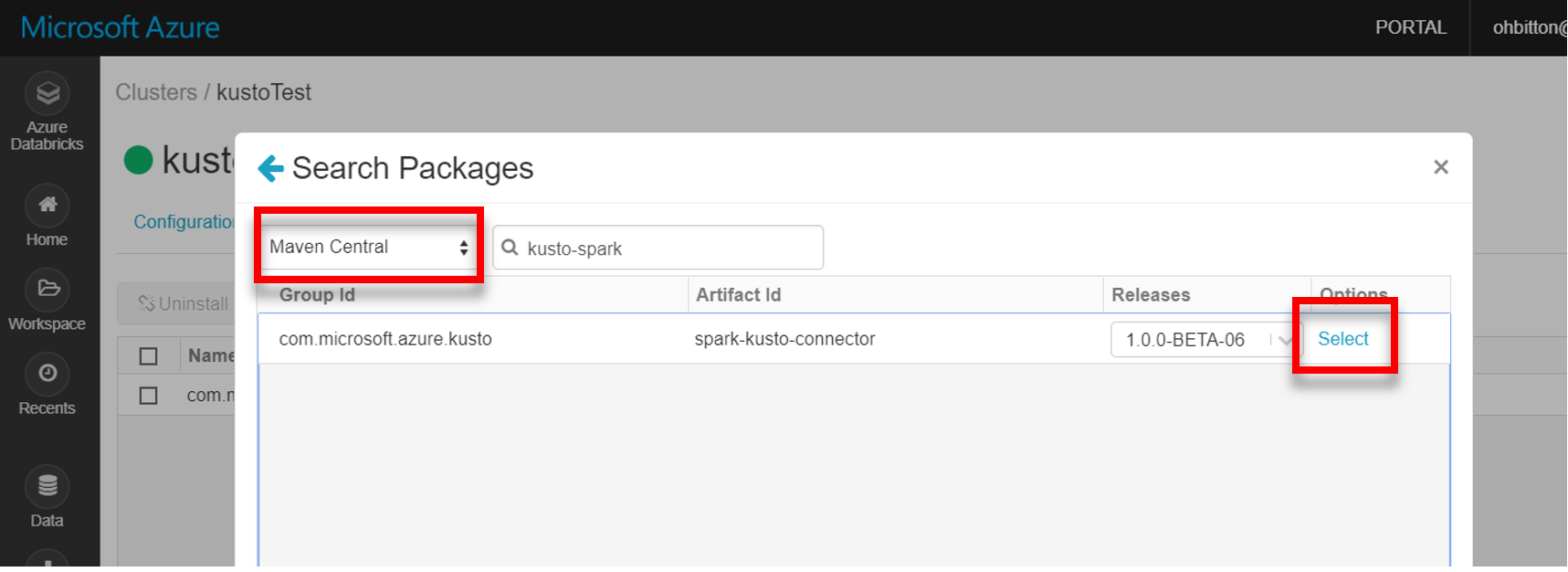
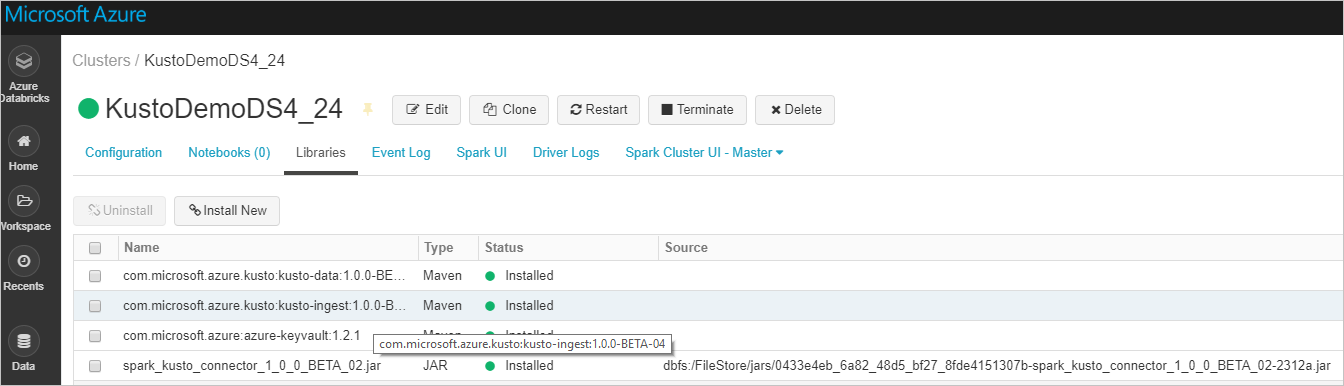
Kontrollera att alla nödvändiga bibliotek är installerade:
Kontrollera att andra beroenden har installerats för installation med hjälp av en JAR-fil:
Autentisering
Med Kusto Spark-anslutningsappen kan du autentisera med Microsoft Entra-ID med någon av följande metoder:
- Ett Microsoft Entra-program
- En Microsoft Entra-åtkomsttoken
- Enhetsautentisering (för icke-produktionsscenarier)
- Ett Azure Key Vault Om du vill komma åt Key Vault-resursen installerar du azure-keyvault-paketet och anger autentiseringsuppgifter för programmet.
Microsoft Entra-programautentisering
Microsoft Entra-programautentisering är den enklaste och vanligaste autentiseringsmetoden och rekommenderas för Kusto Spark-anslutningsappen.
Logga in på din Azure-prenumeration via Azure CLI. Autentisera sedan i webbläsaren.
az loginVälj den prenumeration som ska vara värd för huvudkontot. Det här steget behövs när du har flera prenumerationer.
az account set --subscription YOUR_SUBSCRIPTION_GUIDSkapa tjänstens huvudnamn. I det här exemplet kallas
my-service-principaltjänstens huvudnamn .az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Från de returnerade JSON-data kopierar du
appId,passwordochtenantför framtida användning.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Du har skapat ditt Microsoft Entra-program och tjänstens huvudnamn.
Spark-anslutningsappen använder följande Entra-appegenskaper för autentisering:
| Egenskaper | Alternativsträng | beskrivning |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra-programidentifierare (klient). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra-autentiseringsutfärdaren. Microsoft Entra Directory-ID (klientorganisation). Valfritt – standardvärdet är microsoft.com. Mer information finns i Microsoft Entra-utfärdare. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra-programnyckel för klienten. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Om du redan har en accessToken som har skapats med åtkomst till Kusto kan den även användas som skickas till anslutningsappen för autentisering. |
Kommentar
Äldre API-versioner (mindre än 2.0.0) har följande namngivning: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Kusto-privilegier
Bevilja följande behörigheter på kusto-sidan baserat på den Spark-åtgärd som du vill utföra.
| Spark-åtgärd | Privilegier |
|---|---|
| Läsa – enkelt läge | Läsare |
| Läs – Framtvinga distribuerat läge | Läsare |
| Skriv – Köat läge med createTableIfNotExist-tabellskapningsalternativ | Administratör |
| Skriv – Köat läge med alternativet För att skapa failIfNotExist-tabell | Ingestor |
| Write – TransactionalMode | Administratör |
Mer information om huvudroller finns i rollbaserad åtkomstkontroll. Information om hur du hanterar säkerhetsroller finns i Hantering av säkerhetsroller.
Spark-mottagare: skriva till Kusto
Konfigurera mottagarparametrar:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Skriv Spark DataFrame till Kusto-kluster som batch:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Eller använd den förenklade syntaxen:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Skriva strömmande data:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark-källa: läsa från Kusto
När du läser små mängder data definierar du datafrågan:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Valfritt: Om du anger den tillfälliga bloblagringen (och inte Kusto) skapas blobarna under anroparens ansvar. Detta omfattar etablering av lagring, roterande åtkomstnycklar och borttagning av tillfälliga artefakter. Modulen KustoBlobStorageUtils innehåller hjälpfunktioner för att ta bort blobar baserat på antingen konto- och containerkoordinater och kontoautentiseringsuppgifter, eller en fullständig SAS-URL med skriv-, läs- och listbehörigheter. När motsvarande RDD inte längre behövs lagrar varje transaktion tillfälliga blobartefakter i en separat katalog. Den här katalogen samlas in som en del av informationsloggar för lästransaktion som rapporteras på Spark-drivrutinsnoden.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")I exemplet ovan används inte Key Vault med anslutningsgränssnittet. en enklare metod för att använda Databricks-hemligheter används.
Läs från Kusto.
Om du anger den tillfälliga bloblagringen läser du från Kusto på följande sätt:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Om Kusto tillhandahåller den tillfälliga bloblagringen läser du från Kusto på följande sätt:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)