Hämta data från realtidshubben (förhandsversion)
I den här artikeln får du lära dig hur du hämtar händelser från realtidshubben till antingen en ny eller befintlig tabell.
Viktigt!
Den här funktionen är i förhandsversion.
Kommentar
För närvarande stöder realtidshubben endast eventstreams som källa. Realtidshubben är för närvarande i förhandsversion.
Förutsättningar
- En arbetsyta med en Microsoft Fabric-aktiverad kapacitet
- En KQL-databas med redigeringsbehörigheter
- En händelseström med en datakälla
Källa
För att hämta data från realtidshubben måste du välja en realtidsström från realtidsdatahubben som datakälla. Du kan välja Realtidshubb på följande sätt:
I det nedre menyfliksområdet i din KQL-databas kan du antingen:
I listrutan Hämta data går du sedan till Kontinuerlig och väljer Realtidshubb (förhandsversion).
Välj Hämta data och välj sedan en ström från avsnittet Realtidshubben i fönstret Hämta data .
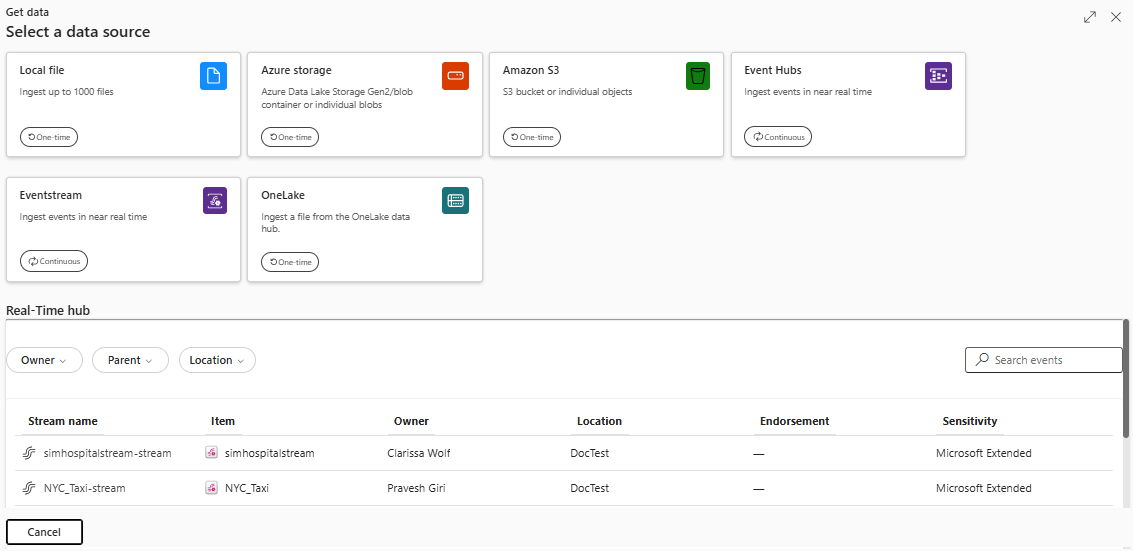
Välj en dataström från realtidshubbens dataströmlista.

Konfigurera
Välj en måltabell. Om du vill mata in data i en ny tabell väljer du + Ny tabell och anger ett tabellnamn.
Kommentar
Tabellnamn kan innehålla upp till 1 024 tecken, inklusive blanksteg, alfanumeriskt, bindestreck och understreck. Specialtecken stöds inte.
Under Konfigurera datakällan fyller du i inställningarna med hjälp av informationen i följande tabell. Viss inställningsinformation fylls automatiskt från din händelseström.
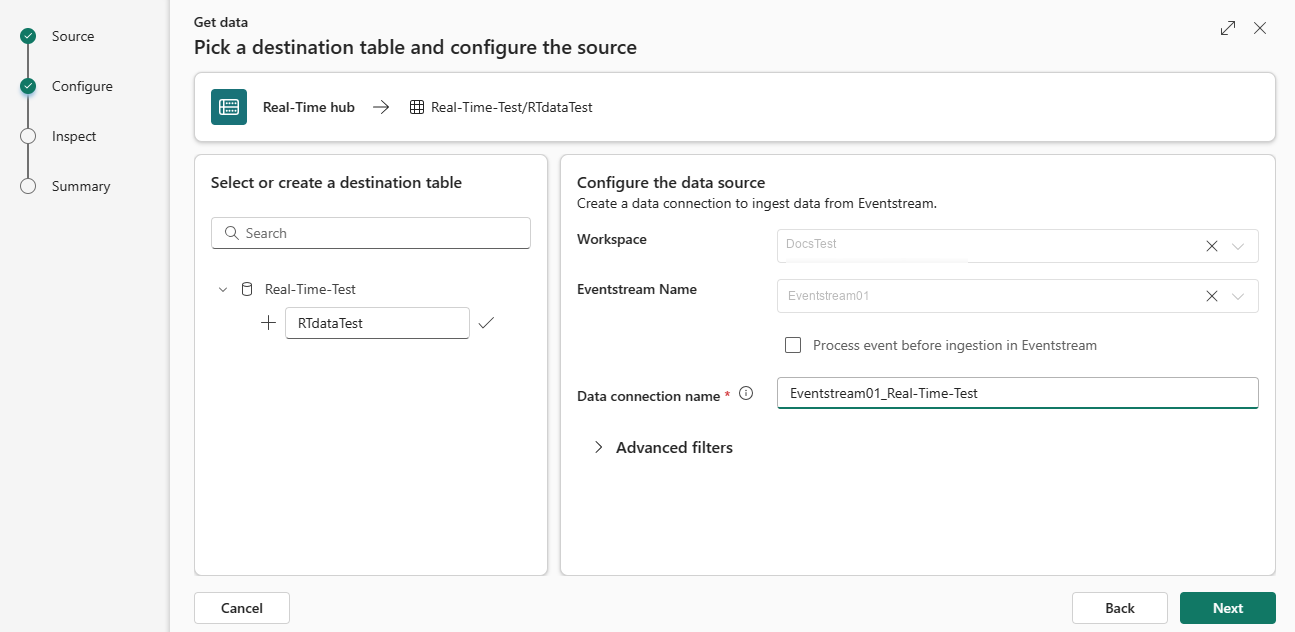
Inställning Beskrivning Arbetsyta Platsen för din eventstream-arbetsyta. Namnet på arbetsytan fylls i automatiskt. Eventstream-namn Namnet på din händelseström. Ditt eventstream-namn fylls i automatiskt. Namn på dataanslutning Namnet som används för att referera till och hantera din dataanslutning på din arbetsyta. Namnet på dataanslutningen fylls i automatiskt. Du kan också ange ett nytt namn. Namnet får bara innehålla alfanumeriska tecken, bindestreck och punkttecken och vara upp till 40 tecken långa. Bearbeta händelse före inmatning i Eventstream Med det här alternativet kan du konfigurera databehandling innan data matas in i måltabellen. Om du väljer det fortsätter du datainmatningsprocessen i Eventstream. Mer information finns i Bearbeta händelse före inmatning i Eventstream. Avancerade filter Komprimering Datakomprimering av händelserna, som kommer från hubben. Alternativen är Ingen (standard) eller Gzip-komprimering. Egenskaper för händelsesystem Om det finns flera poster per händelsemeddelande läggs systemegenskaperna till i den första. Mer information finns i Egenskaper för händelsesystem. Startdatum för händelsehämtning Dataanslutningen hämtar befintliga händelser som skapats sedan startdatumet för händelsehämtning. Den kan bara hämta händelser som behålls av hubben baserat på dess kvarhållningsperiod. Tidszonen är UTC. Om ingen tid anges är standardtiden den tid då dataanslutningen skapas. Välj Nästa

Bearbeta händelse före inmatning i Eventstream
Med alternativet Processhändelse före inmatning i Eventstream kan du bearbeta data innan de matas in i måltabellen. Med det här alternativet fortsätter processen för att hämta data sömlöst i Eventstream, där måltabellen och datakällans information fylls i automatiskt.
Så här bearbetar du händelse före inmatning i Eventstream:
På fliken Konfigurera väljer du Processhändelse före inmatning i Eventstream.
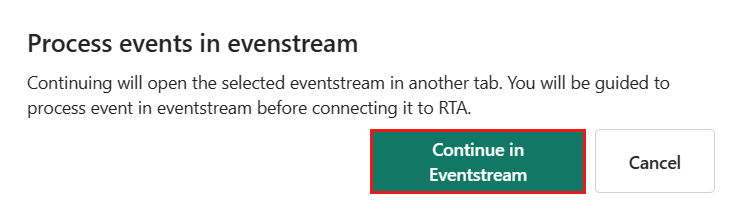
I dialogrutan Processhändelser i Eventstream väljer du Fortsätt i Eventstream.
Viktigt!
Om du väljer Fortsätt i Eventstream avslutas hämtar dataprocessen i Realtidsinformation och fortsätter i Eventstream med måltabellen och datakällans information automatiskt ifylld.
I Eventstream väljer du målnoden KQL Database och i fönstret KQL-databas kontrollerar du att Händelsebearbetning före inmatning har valts och att målinformationen är korrekt.
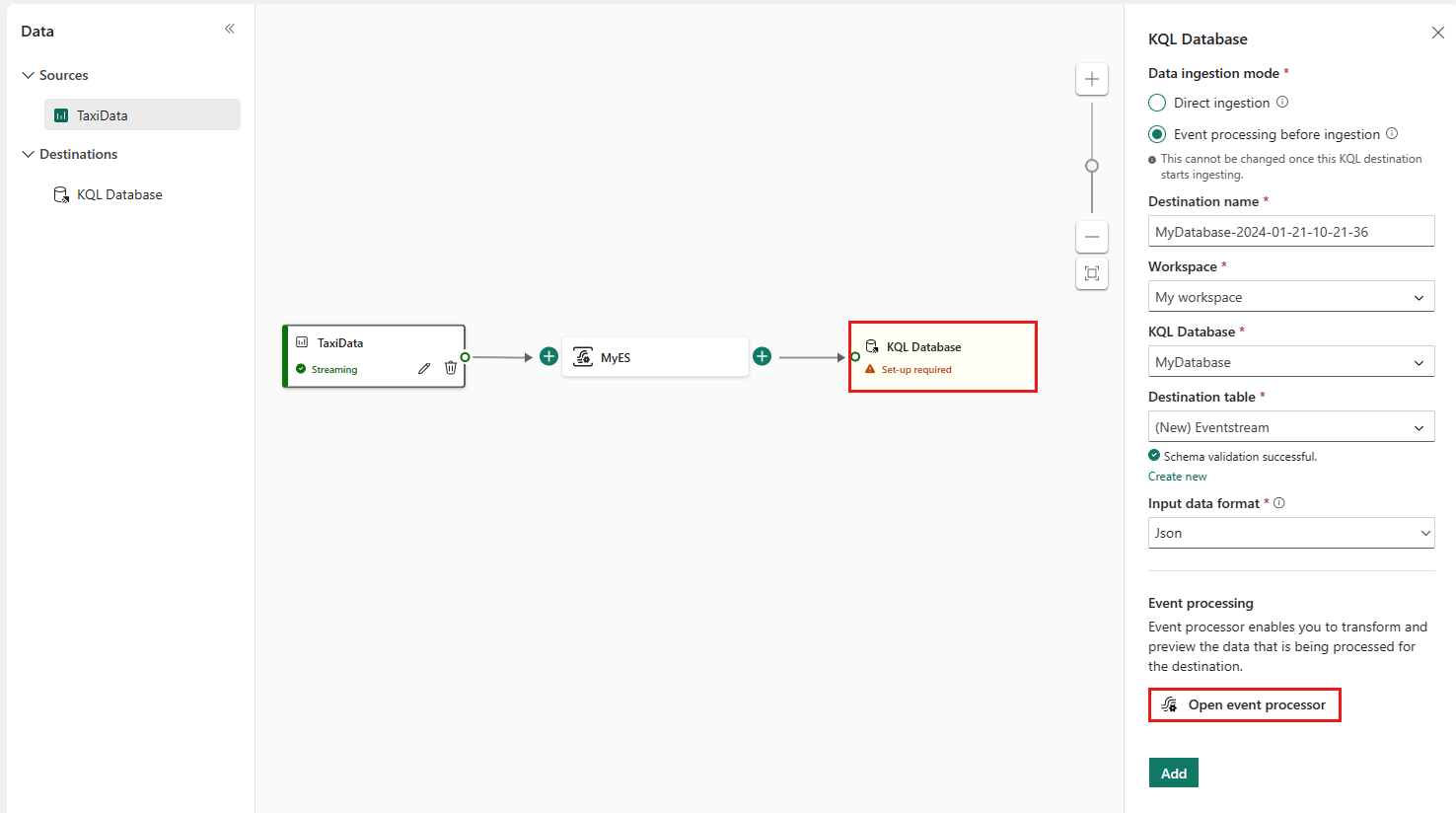
Välj Öppna händelseprocessor för att konfigurera databearbetningen och välj sedan Spara. Mer information finns i Bearbeta händelsedata med redigeraren för händelseprocessor.
I fönstret KQL-databas väljer du Lägg till för att slutföra konfigurationen av KQL Database-målnoden.
Kontrollera att data matas in i måltabellen.


Kommentar
Processhändelsen före inmatningen i Eventstream-processen är klar och de återstående stegen i den här artikeln krävs inte.
Undersöka
Fliken Inspektera öppnas med en förhandsgranskning av data.
Slutför inmatningsprocessen genom att välja Slutför.

Valfritt:
- Välj Kommandovisningsprogram för att visa och kopiera de automatiska kommandon som genereras från dina indata.
- Ändra det automatiskt härledda dataformatet genom att välja önskat format i listrutan. Data läss från hubben i form av EventData-objekt . Format som stöds är Avro, Apache Avro, CSV, JSON, ORC, Parquet, PSV, RAW, SCsv, SOHsv, TSV, TXT och TSVE.
- Redigera kolumner.
- Utforska Avancerade alternativ baserat på datatyp.
Redigera kolumner
Kommentar
- För tabellformat (CSV, TSV, PSV) kan du inte mappa en kolumn två gånger. Om du vill mappa till en befintlig kolumn tar du först bort den nya kolumnen.
- Du kan inte ändra en befintlig kolumntyp. Om du försöker mappa till en kolumn med ett annat format kan du få tomma kolumner.
Vilka ändringar du kan göra i en tabell beror på följande parametrar:
- Tabelltypen är ny eller befintlig
- Mappningstypen är ny eller befintlig
| Tabelltyp | Mappningstyp | Tillgängliga justeringar |
|---|---|---|
| Ny tabell | Ny mappning | Byt namn på kolumn, ändra datatyp, ändra datakälla, mappningstransformering, lägga till kolumn, ta bort kolumn |
| Befintlig tabell | Ny mappning | Lägg till kolumn (där du sedan kan ändra datatyp, byta namn på och uppdatera) |
| Befintlig tabell | Befintlig mappning | inget |

Mappa transformeringar
Vissa dataformatmappningar (Parquet, JSON och Avro) stöder enkla inmatningstidstransformeringar. Om du vill använda mappningstransformeringar skapar eller uppdaterar du en kolumn i fönstret Redigera kolumner .
Mappningstransformeringar kan utföras på en kolumn av typen sträng eller datetime, där källan har datatypen int eller long. Mappningstransformeringar som stöds är:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
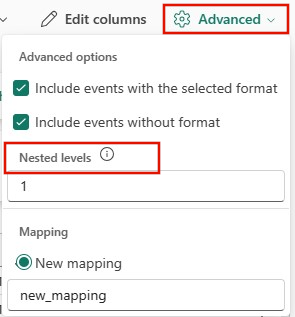
Avancerade alternativ baserat på datatyp
Tabell (CSV, TSV, PSV):
Tabelldata innehåller inte nödvändigtvis de kolumnnamn som används för att mappa källdata till befintliga kolumner. Om du vill använda den första raden som kolumnnamn aktiverar du Första raden är kolumnrubrik.

JSON:
Välj Avancerade> mellan 1 och 100 för att fastställa kolumndelningen för JSON-data.
Sammanfattning
I fönstret Dataförberedelse markeras alla tre stegen med gröna bockmarkeringar när datainmatningen har slutförts. Du kan välja ett kort för att fråga, släppa inmatade data eller se en instrumentpanel för inmatningssammanfattningen. Välj Stäng för att stänga fönstret.

Relaterat innehåll
- Information om hur du hanterar databasen finns i Hantera data
- Information om hur du skapar, lagrar och exporterar frågor finns i Fråga efter data i en KQL-frågeuppsättning
- Information om hur du hämtar data från en ny händelseström finns i Hämta data från en ny händelseström