Transformera data med Apache Spark och fråga med SQL
I den här guiden kommer du att:
Ladda upp data till OneLake med OneLake-utforskaren.
Använd en Fabric-anteckningsbok för att läsa data på OneLake och skriva tillbaka som en Delta-tabell.
Analysera och transformera data med Spark med hjälp av en Fabric-notebook-fil.
Fråga en kopia av data på OneLake med SQL.
Förutsättningar
Innan du börjar måste du:
Ladda ned och installera OneLake-utforskaren.
Skapa en arbetsyta med ett Lakehouse-objekt.
Ladda ned datauppsättningen WideWorldImportersDW. Du kan använda Azure Storage Explorer för att ansluta till
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityoch ladda ned uppsättningen csv-filer. Eller så kan du använda dina egna csv-data och uppdatera informationen efter behov.
Kommentar
Skapa, läs in eller skapa alltid en genväg till Delta-Parquet-data direkt under avsnittet Tabeller i lakehouse. Kapsla inte dina tabeller i undermappar under avsnittet Tabeller eftersom lakehouse inte känner igen den som en tabell och kommer att märka den som Oidentifierad.
Ladda upp, läsa, analysera och fråga efter data
I OneLake-utforskaren
/Filesnavigerar du till ditt lakehouse och under katalogen skapar du en underkatalog med namnetdimension_city.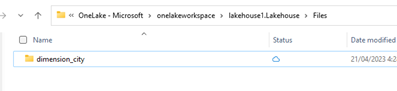
Kopiera dina csv-exempelfiler till OneLake-katalogen
/Files/dimension_citymed onelake-utforskaren.
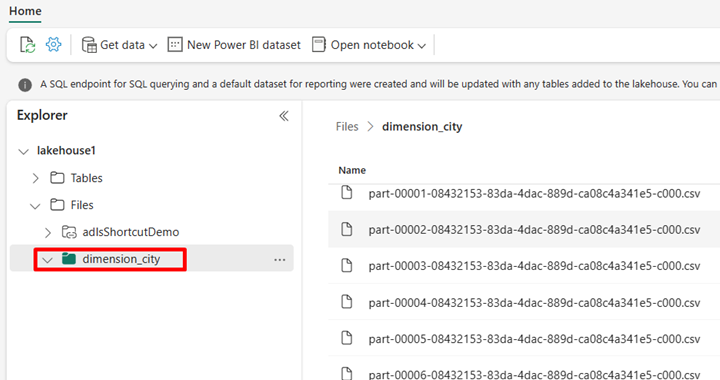
Gå till ditt lakehouse i Power BI-tjänst och visa dina filer.
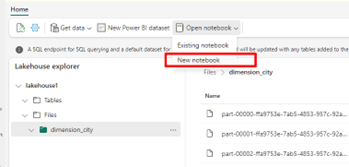
Välj Öppna anteckningsbok och sedan Ny anteckningsbok för att skapa en notebook-fil.
Konvertera CSV-filerna till Delta-format med hjälp av anteckningsboken Infrastruktur. Följande kodfragment läser data från den användarskapade katalogen
/Files/dimension_cityoch konverterar dem till en Delta-tabelldim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Om du vill se den nya tabellen uppdaterar du vyn för
/Tableskatalogen.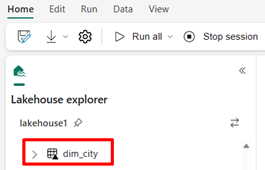
Fråga tabellen med SparkSQL i samma Fabric-notebook-fil.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Ändra Delta-tabellen genom att lägga till en ny kolumn med namnet newColumn med datatyps heltal. Ange värdet 9 för alla poster för den nyligen tillagda kolumnen.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;Du kan också komma åt alla Delta-tabeller på OneLake via en SQL-analysslutpunkt. En SQL-analysslutpunkt refererar till samma fysiska kopia av Delta-tabellen på OneLake och erbjuder T-SQL-upplevelsen. Välj SQL-analysslutpunkten för lakehouse1 och välj sedan Ny SQL-fråga för att köra frågor mot tabellen med hjälp av T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
