Skapa ett sjöhus för Direct Lake
Den här artikeln beskriver hur du skapar ett sjöhus, skapar en Delta-tabell i lakehouse och sedan skapar en grundläggande semantisk modell för lakehouse i en Microsoft Fabric-arbetsyta.
Innan du börjar skapa ett lakehouse för Direct Lake bör du läsa Direct Lake-översikt.
Skapa ett sjöhus
På din Microsoft Fabric-arbetsyta väljer du Nya>Fler alternativoch väljer sedan panelen Lakehouse i Data Engineering.
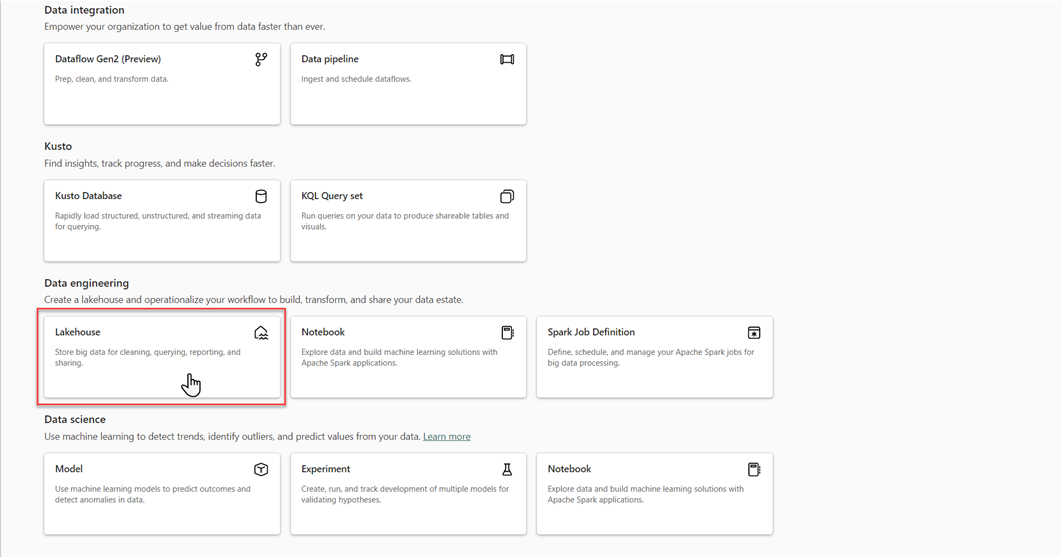
I dialogrutan New lakehouse anger du ett namn och väljer sedan Skapa. Namnet får bara innehålla alfanumeriska tecken och understreck.
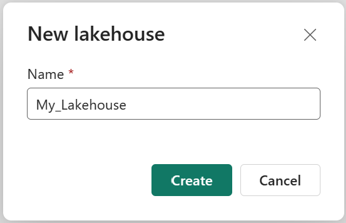
Kontrollera att det nya sjöhuset har skapats och öppnas.
Skapa en Delta-tabell i lakehouse
När du har skapat ett nytt lakehouse måste du sedan skapa minst en Delta-tabell så att Direct Lake kan komma åt vissa data. Direct Lake kan läsa parquet-formaterade filer, men för bästa prestanda är det bäst att komprimera data med hjälp av VORDER-komprimeringsmetoden. VORDER komprimerar data med power BI-motorns interna komprimeringsalgoritm. På så sätt kan motorn läsa in data i minnet så snabbt som möjligt.
Det finns flera alternativ för att läsa in data i ett lakehouse, inklusive datarörledningar och skript. Följande steg använder PySpark för att lägga till en Delta-tabell i ett lakehouse baserat på en Azure Open Dataset:
I det nyskapade lakehouse väljer du Öppna notebook-och väljer sedan Ny notebook-.
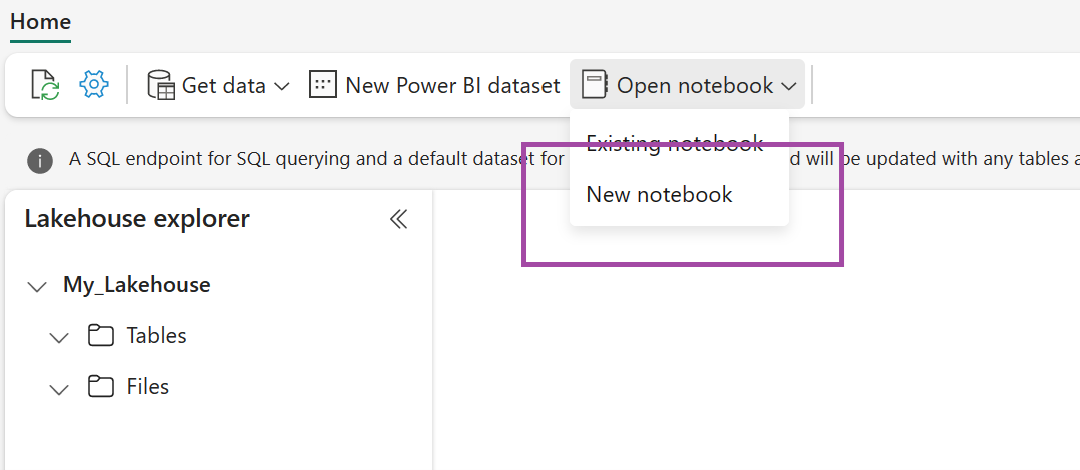
Kopiera och klistra in följande kodfragment i den första kodcellen för att ge SPARK åtkomst till den öppna modellen och tryck sedan på Skift + Retur för att köra koden.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Kontrollera att koden framgångsrikt genererar en fjärrblobsökväg.
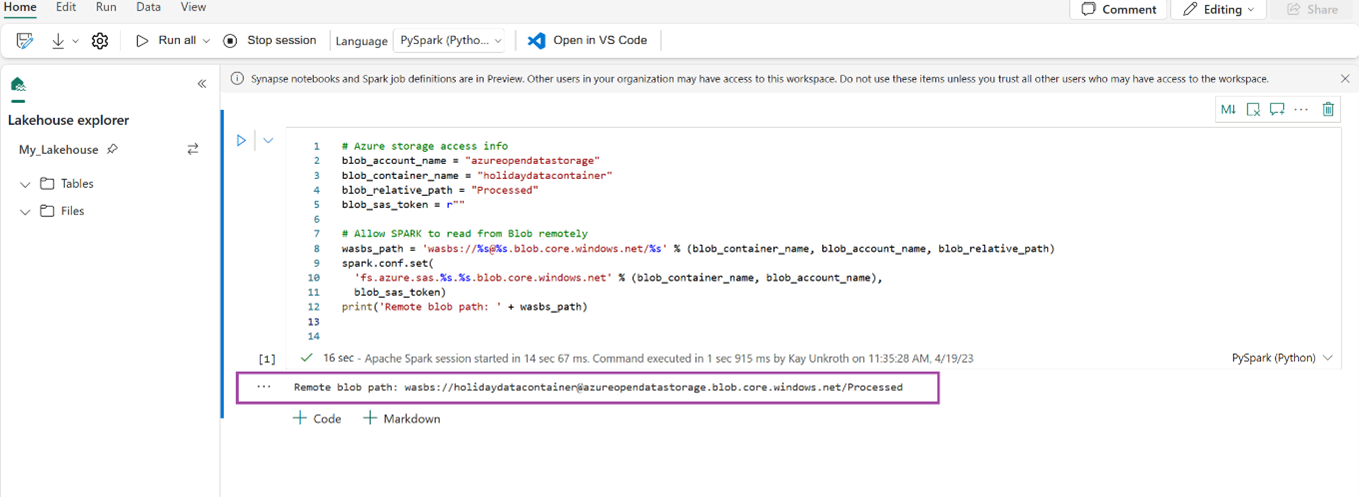
Kopiera och klistra in följande kod i nästa cell, och tryck sedan på Skift + Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Kontrollera att koden har matat ut DataFrame-schemat.
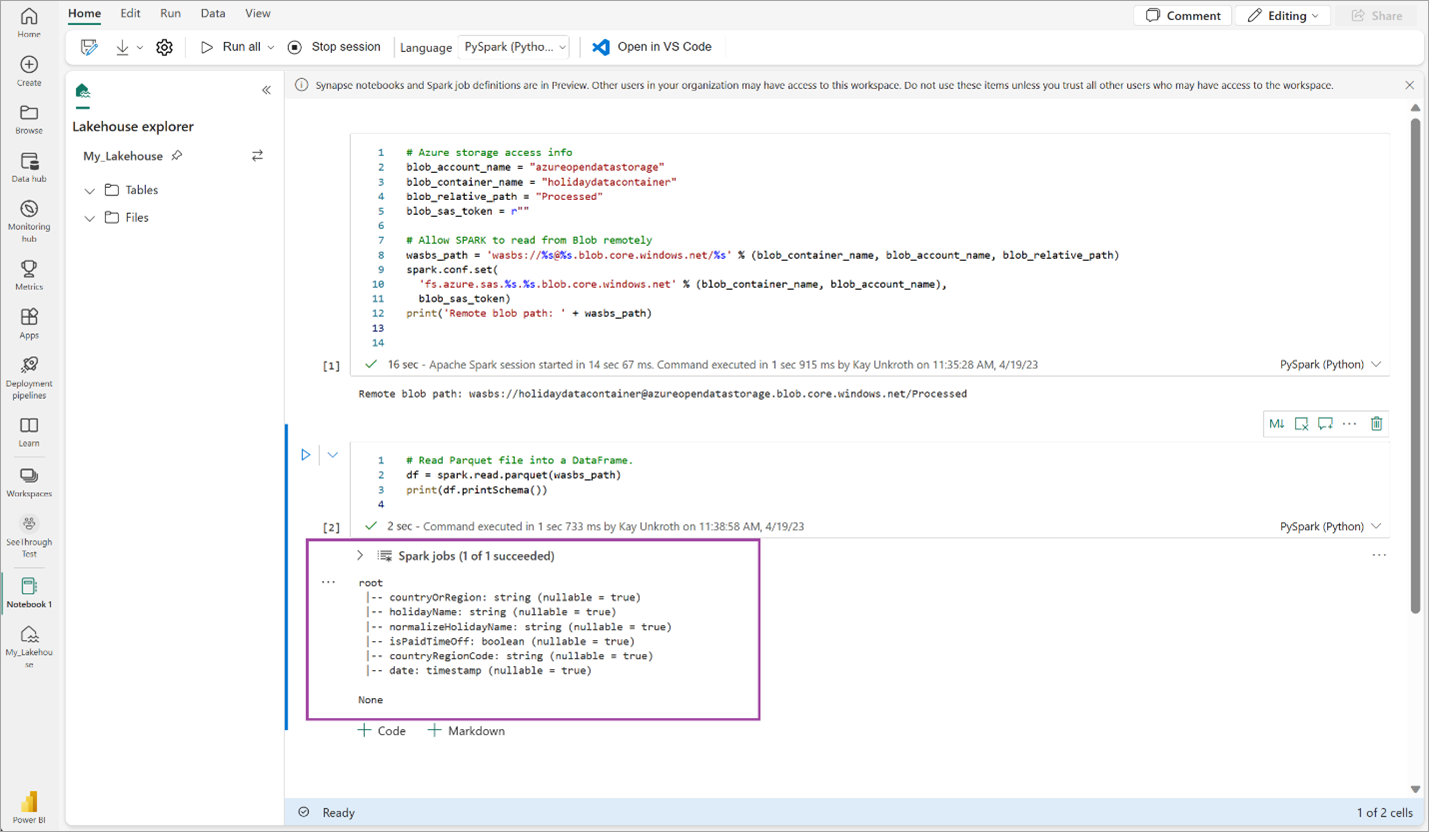
Kopiera och klistra in följande rader i nästa cell och tryck sedan på Skift + Retur. Den första instruktionen aktiverar VORDER-komprimeringsmetoden, och nästa instruktion sparar DataFrame som en Delta-tabell i lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Kontrollera att alla SPARK-jobb har slutförts. Expandera LISTAN MED SPARK-jobb om du vill visa mer information.
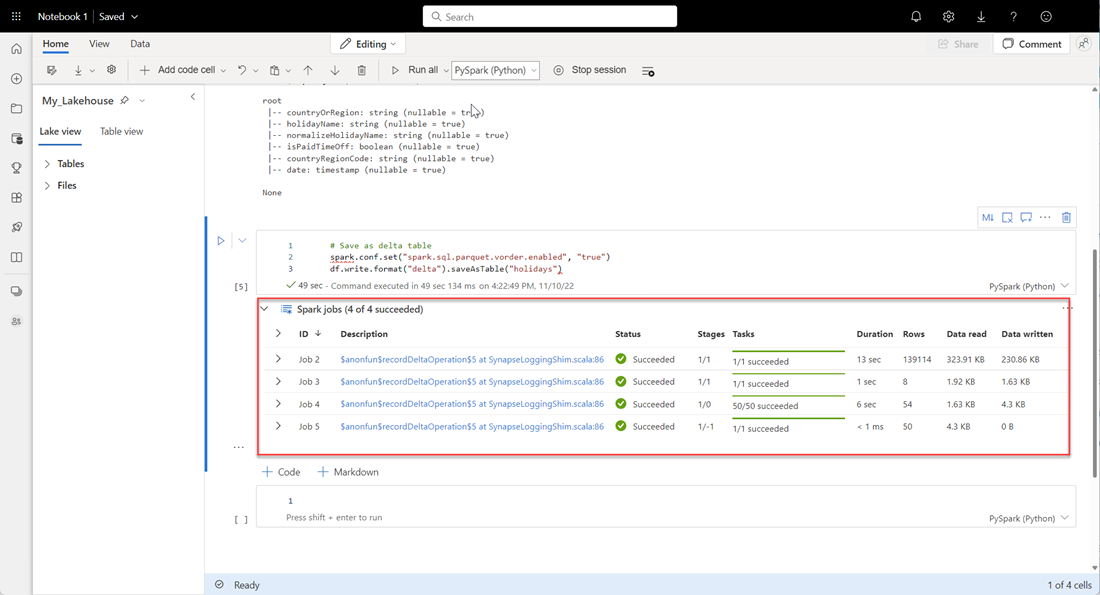
För att kontrollera att en tabell har skapats, välj ellipsen (…) i det övre vänstra området bredvid Tabeller, välj sedan Uppdatera, och expandera sedan Tabeller-noden.
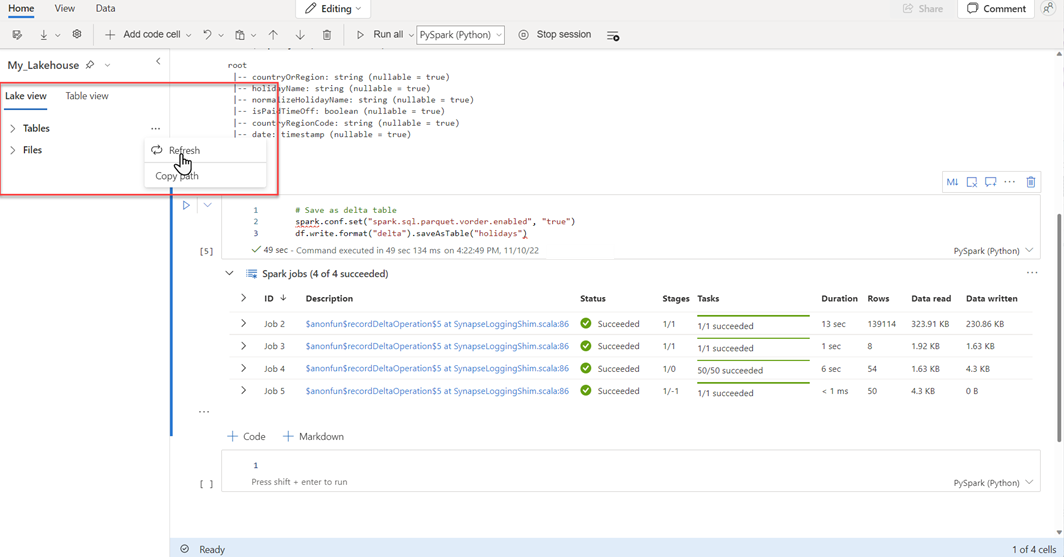
Använd antingen samma metod som ovan eller andra metoder som stöds och lägg till fler Delta-tabeller för de data som du vill analysera.
Skapa en grundläggande Direct Lake-modell för ditt lakehouse
I lakehouse väljer du Ny semantisk modelloch väljer sedan tabeller som ska inkluderas i dialogrutan.
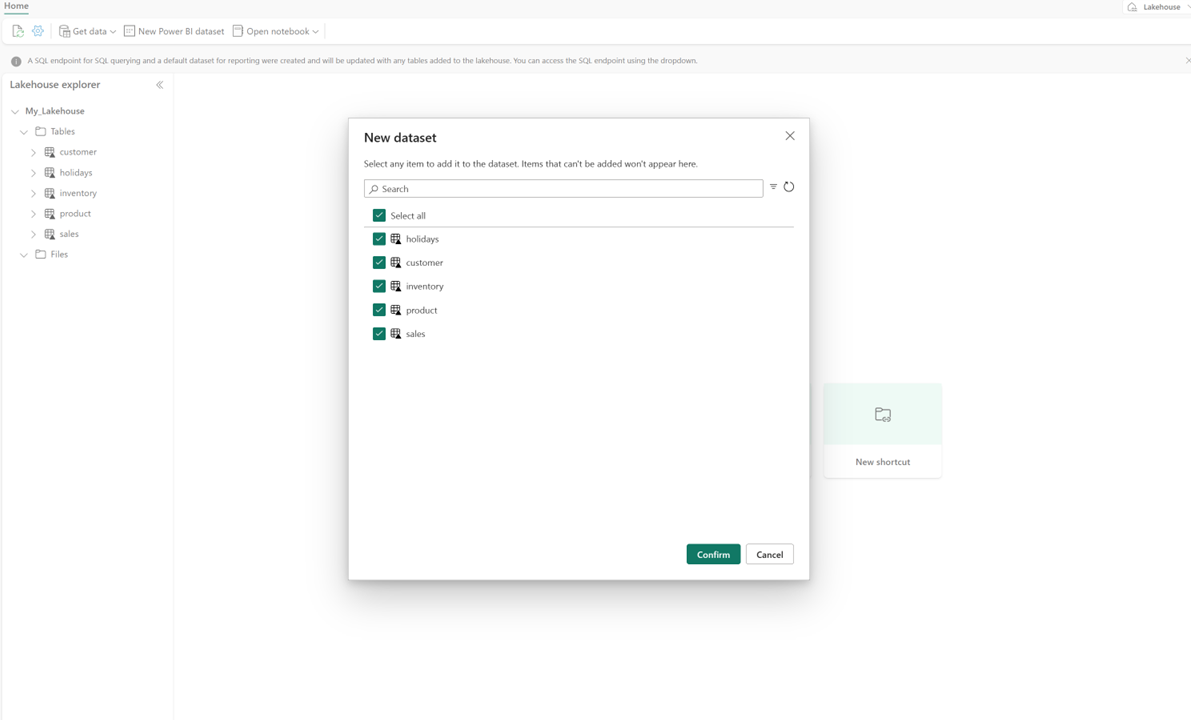
Välj Bekräfta för att generera Direct Lake-modellen. Modellen sparas automatiskt i arbetsytan baserat på namnet på ditt lakehouse, och därefter öppnas modellen.
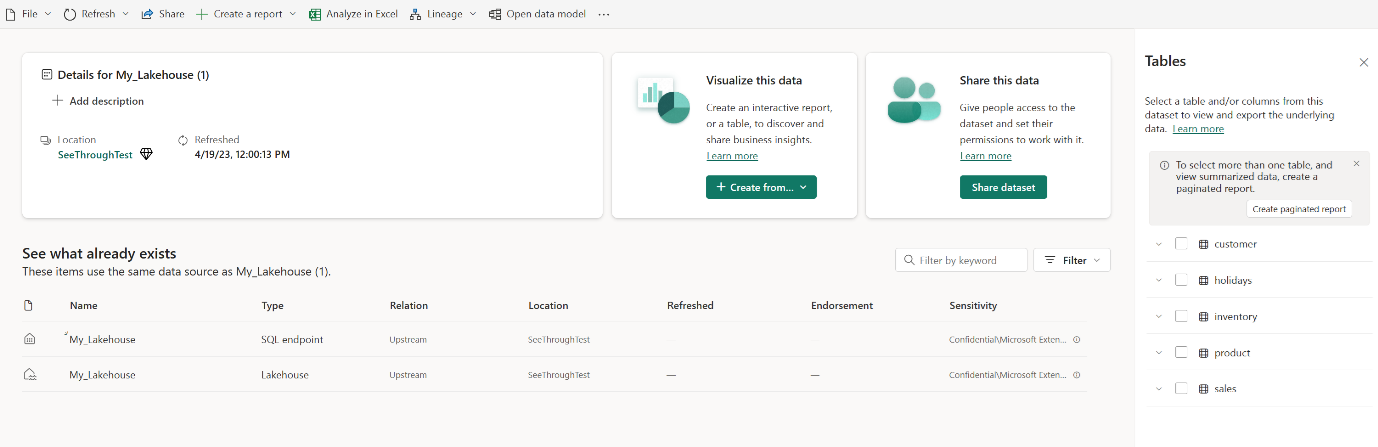
Välj Öppna datamodell för att öppna webbmodelleringsmiljön där du kan lägga till tabellrelationer och DAX-mått.
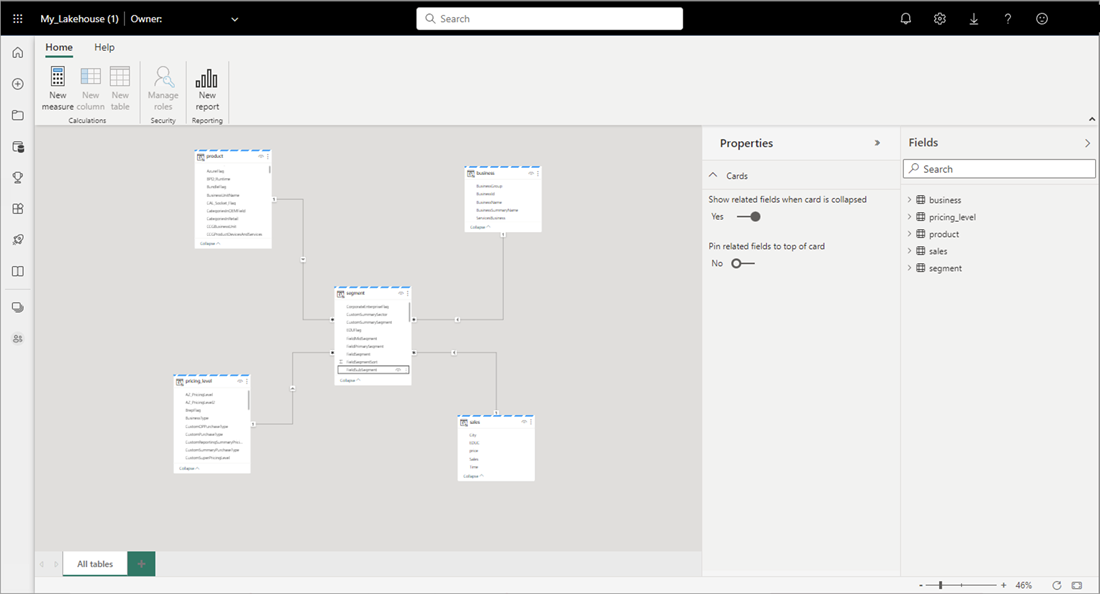
När du är klar med att lägga till relationer och DAX-mått kan du skapa rapporter, skapa en sammansatt modell och köra frågor mot modellen via XMLA-slutpunkter på ungefär samma sätt som andra modeller.