Mata in exempeldata och skapa objekt och data
Gäller för:✅SQL-databas i Microsoft Fabric
Du kan mata in data i SQL-databasen i Fabric med transact-SQL-instruktioner (T-SQL) och du kan även importera data till databasen med hjälp av andra Microsoft Fabric-komponenter, till exempel funktionen Dataflow Gen2 eller datapipelines. För utveckling kan du ansluta med alla verktyg som stöder TDS-protokollet (Tabular Data Stream), till exempel Visual Studio Code eller SQL Server Management Studio.
Om du vill börja med det här avsnittet kan du använda SalesLT-exempeldata som tillhandahålls som utgångspunkt.
Förutsättningar
- Slutför alla föregående steg i den här självstudien.
Öppna frågeredigeraren i Infrastrukturportalen
Öppna SQL-databasen i Fabric-databasen som du skapade i det senaste självstudiesteget. Du hittar den i navigeringsfältet i Fabric-portalen eller genom att hitta den i din arbetsyta för den här självstudien.
Välj knappen Exempeldata. Det tar en stund att fylla i din självstudiedatabas med SalesLT-exempeldata .

Kontrollera området Meddelanden för att se till att importen är klar innan du fortsätter.
Meddelanden visar när importen av exempeldata är klar. SQL-databasen i Fabric innehåller
SalesLTnu schemat och associerade tabeller.

Använda SQL-databasen i SQL-redigeraren
Den webbaserade SQL-redigeraren för SQL Database i Fabric tillhandahåller ett grundläggande objektutforskare och frågekörningsgränssnitt. En ny SQL-databas i Fabric öppnas automatiskt i SQL-redigeraren och en befintlig databas kan öppnas i SQL-redigeraren genom att öppna den i Infrastruktur-portalen.
Det finns flera objekt i verktygsfältet i webbredigeraren, inklusive uppdatering, inställningar, en frågeåtgärd och möjligheten att hämta prestandainformation. Du använder de här funktionerna i den här självstudien.
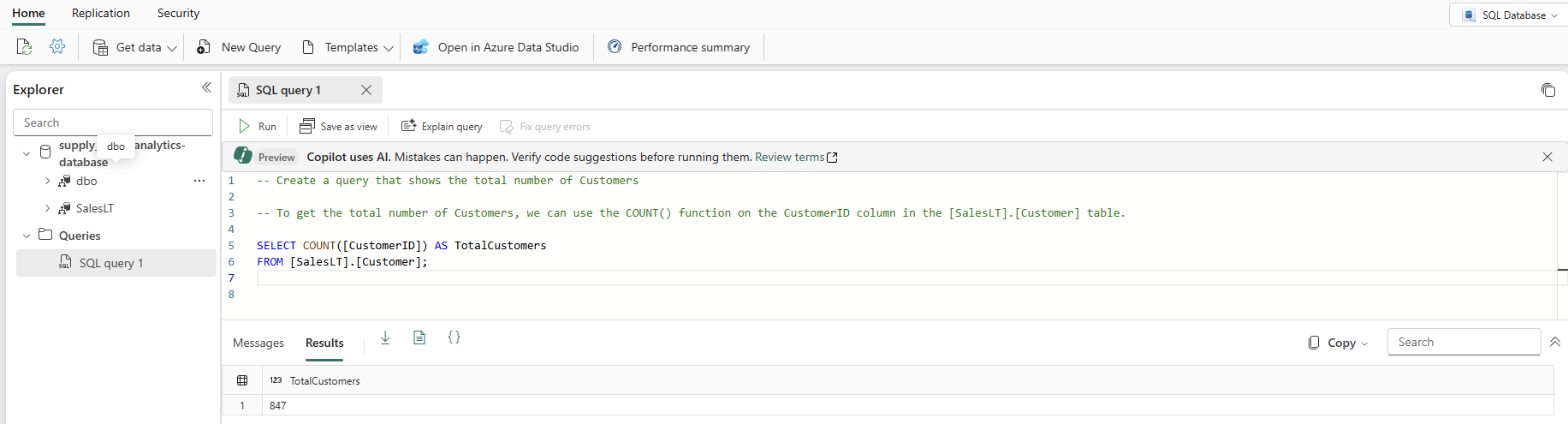
I databasvyn börjar du med att välja Ny fråga i ikonfältet. Detta ger en frågeredigerare som har funktionen Copilot AI som hjälper dig att skriva din kod. Copilot för SQL-databasen kan hjälpa dig att slutföra en fråga eller skapa en.
Skriv en T-SQL-kommentar överst i frågan, till exempel
-- Create a query that shows the total number of customersoch tryck på Retur. Du får ett resultat som liknar det här:
Om du trycker på "Tabb"-tangenten implementeras den föreslagna koden:
Välj Förklara fråga i ikonfältet i frågeredigeraren för att infoga kommentarer i koden för att förklara varje större steg:
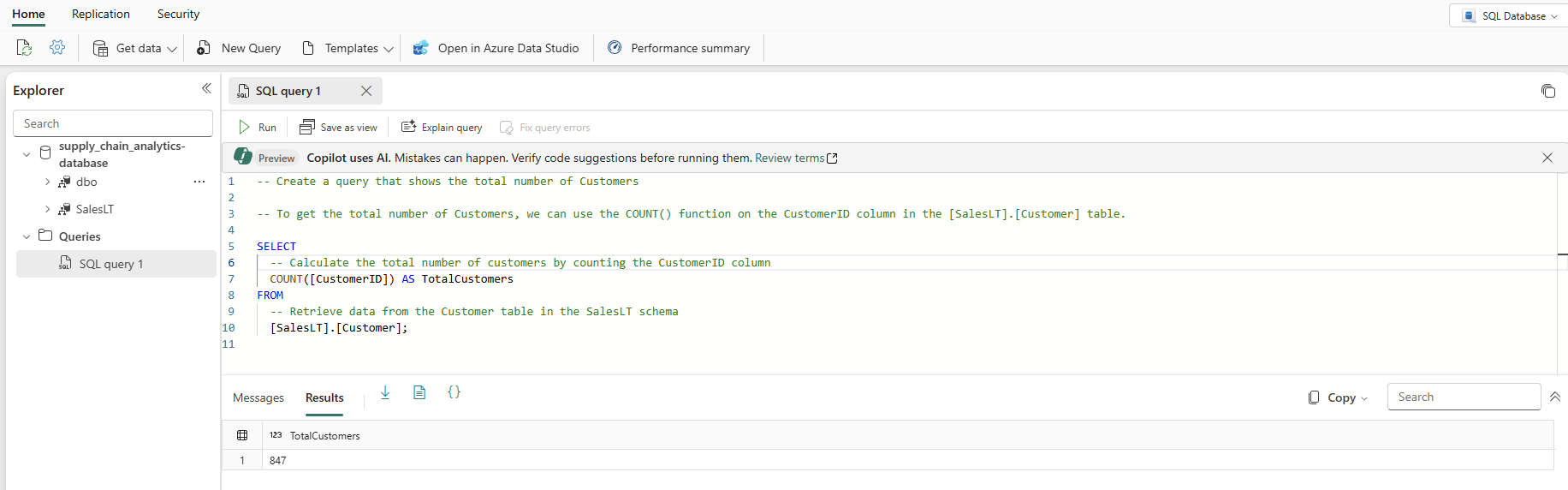
Kommentar
Copilot gör sitt bästa för att ta reda på din avsikt, men du bör alltid kontrollera koden den skapar innan du kör den och alltid testa i en separat miljö från produktion.



I en produktionsmiljö kan du ha data som redan är i ett normaliserat format för dagliga programåtgärder, som du har simulerat här med SalesLT-data . När du skapar en fråga sparas den automatiskt i objektet Frågor i fönstret Utforskaren. Du bör se frågan som "SQL-fråga 1". Som standard numrerar systemet frågorna som "SQL-fråga 1", men du kan välja ellipserna bredvid frågenamnet för att duplicera, byta namn på eller ta bort frågan.
Infoga data med Transact-SQL
Du har blivit ombedd att skapa nya objekt för att spåra organisationens leveranskedja, så du måste lägga till en uppsättning objekt för ditt program. I det här exemplet skapar du ett enskilt objekt i ett nytt schema. Du kan lägga till fler tabeller för att helt normalisera programmet. Du kan lägga till mer data, till exempel flera komponenter per produkt, ha mer leverantörsinformation och så vidare. Senare i den här självstudien får du se hur data speglas till SQL-analysslutpunkten och hur du kan köra frågor mot data med ett GraphQL-API för att justera automatiskt när objekten läggs till eller ändras.
Följande steg använder ett T-SQL-skript för att skapa ett schema, en tabell och data för simulerade data för analys av leveranskedjan.
Välj knappen Ny fråga i verktygsfältet i SQL-databasen för att skapa en ny fråga.
Klistra in följande skript i området Fråga och välj Kör för att köra det. Följande T-SQL-skript:
- Skapar ett schema med namnet
SupplyChain. - Skapar en tabell med namnet
SupplyChain.Warehouse. - Fyller i
SupplyChain.Warehousetabellen med några slumpmässigt skapade produktdata frånSalesLT.Product.
/* Create the Tutorial Schema called SupplyChain for all tutorial objects */ CREATE SCHEMA SupplyChain; GO /* Create a Warehouse table in the Tutorial Schema NOTE: This table is just a set of INT's as Keys, tertiary tables will be added later */ CREATE TABLE SupplyChain.Warehouse ( ProductID INT PRIMARY KEY -- ProductID to link to Products and Sales tables , ComponentID INT -- Component Identifier, for this tutorial we assume one per product, would normalize into more tables , SupplierID INT -- Supplier Identifier, would normalize into more tables , SupplierLocationID INT -- Supplier Location Identifier, would normalize into more tables , QuantityOnHand INT); -- Current amount of components in warehouse GO /* Insert data from the Products table into the Warehouse table. Generate other data for this tutorial */ INSERT INTO SupplyChain.Warehouse (ProductID, ComponentID, SupplierID, SupplierLocationID, QuantityOnHand) SELECT p.ProductID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS ComponentID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierLocationID, ABS(CHECKSUM(NEWID())) % 100 + 1 AS QuantityOnHand FROM [SalesLT].[Product] AS p; GODin SQL-databas i Fabric-databasen innehåller nu information om lager. Du använder dessa data i ett senare steg i den här självstudien.
- Skapar ett schema med namnet
Du kan välja dessa tabeller i explorer-fönstret och tabelldata visas – du behöver inte skriva en fråga för att se den.
Infoga data med hjälp av en Microsoft Fabric-pipeline
Ett annat sätt att importera data till och exportera data från din SQL-databas i Fabric är att använda en Microsoft Fabric Data Pipeline. Datapipelines är ett alternativ till att använda kommandon, i stället med hjälp av ett grafiskt användargränssnitt. En datapipeline är en logisk gruppering av aktiviteter som tillsammans utför en datainmatningsuppgift. Med pipelines kan du hantera aktiviteter för att extrahera, transformera och läsa in (ETL) i stället för att hantera var och en individuellt.
Microsoft Fabric Pipelines kan innehålla ett dataflöde. Dataflöde Gen2 använder ett Power Query-gränssnitt som gör att du kan utföra transformeringar och andra åtgärder på data. Du använder det här gränssnittet för att hämta data från företaget Northwind Traders , som Contoso samarbetar med. De använder för närvarande samma leverantörer, så du importerar deras data och visar namnen på dessa leverantörer med hjälp av en vy som du skapar i ett annat steg i den här självstudien.
Kom igång genom att öppna SQL-databasvyn för exempeldatabasen i Infrastrukturportalen, om den inte redan är det.
Välj knappen Hämta data i menyraden.
Välj Nytt dataflöde Gen2.
I Power Query-vyn väljer du knappen Hämta data . Detta startar en guidad process i stället för att hoppa till ett visst dataområde.
I sökrutan i Välj datakälla visar du typ odata.
Välj OData från Resultaten från Nya källor .
I textrutan URL i vyn Anslut till datakälla skriver du texten:
https://services.odata.org/v4/northwind/northwind.svc/för Open Data-flödet för exempeldatabasenNorthwind. Välj knappen Nästa för att fortsätta.
Rulla ned till tabellen Leverantörer från OData-feeden och markera kryssrutan bredvid den. Välj sedan knappen Skapa .
Välj + nu plussymbolen bredvid avsnittet Datamål i frågeinställningarna och välj SQL-databas i listan.
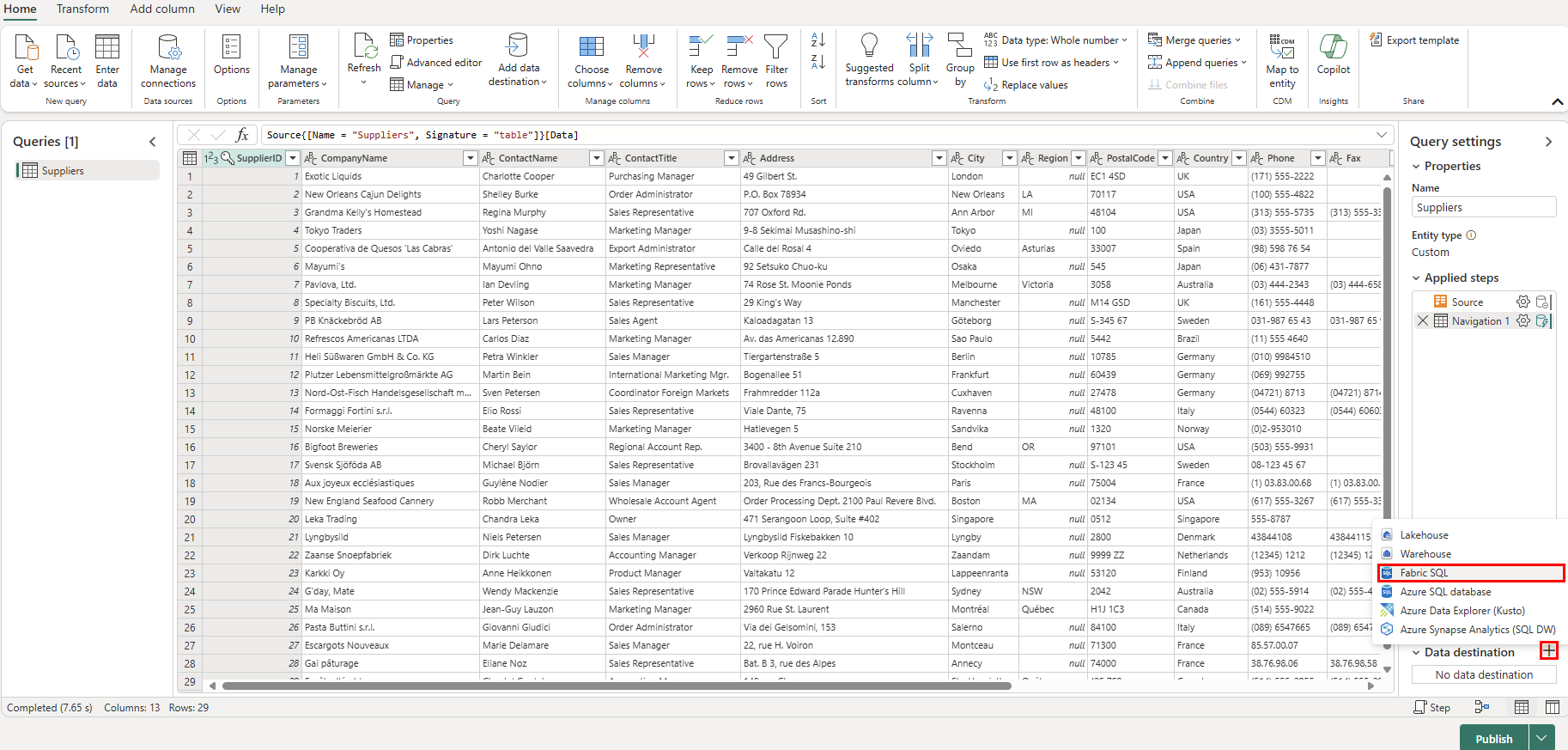
På sidan Anslut till datamål kontrollerar du att autentiseringstypenär inställd på Organisationskonto. Välj Logga in och ange dina autentiseringsuppgifter för Microsoft Entra-ID i databasen.
När du har anslutit väljer du knappen Nästa .
Välj namnet på arbetsytan som du skapade i det första steget i den här självstudien i avsnittet Välj målmål .
Välj den databas som visas under den. Kontrollera att alternativknappen Ny tabell är markerad och lämna namnet på tabellen som Leverantörer och välj knappen Nästa .
Lämna skjutreglaget Använd automatiska inställningar i vyn Välj målinställningar och välj knappen Spara inställningar.
Välj knappen Publicera för att starta dataöverföringen.
Du återgår till vyn Arbetsyta, där du hittar det nya dataflödesobjektet.

När kolumnen Uppdaterad visar aktuellt datum och tid kan du välja databasnamnet i Utforskaren och sedan expandera
dboschemat för att visa den nya tabellen. (Du kan behöva välja Uppdateringsikonen i verktygsfältet.)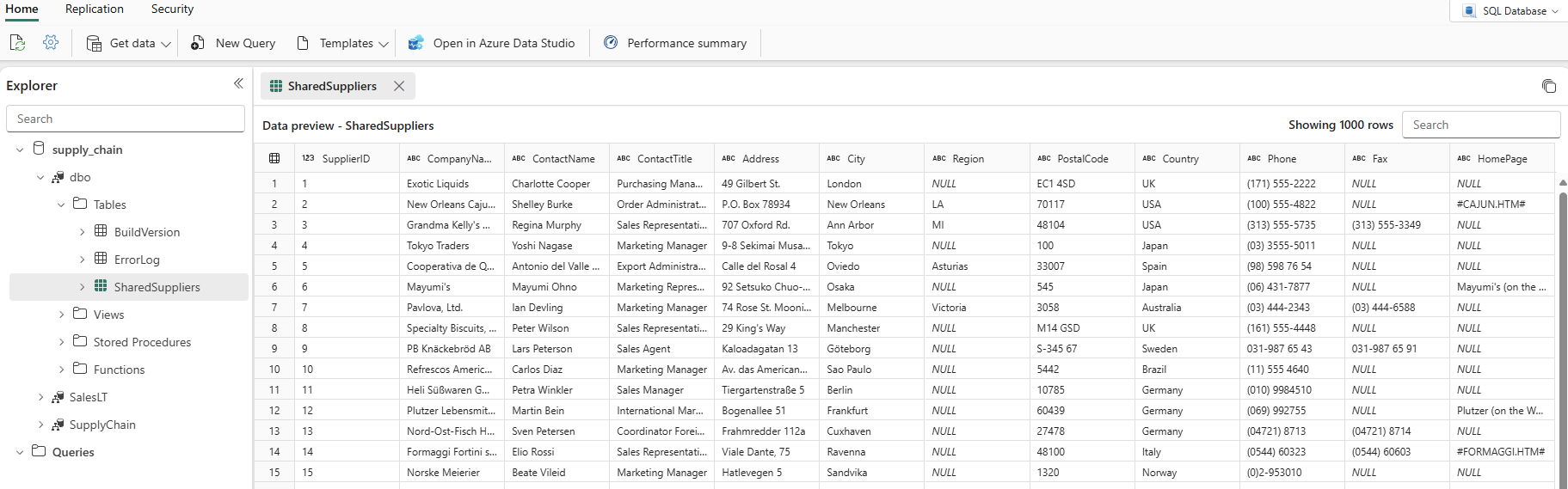




Data matas nu in i databasen. Nu kan du skapa en fråga som kombinerar data från Suppliers tabellen med hjälp av den här tertiära tabellen. Du kommer att göra detta senare i vår självstudie.