Anvisningar: Få åtkomst till speglade Azure Cosmos DB-data i Lakehouse och notebook-filer från Microsoft Fabric (förhandsversion)
I den här guiden lär du dig att komma åt speglade Azure Cosmos DB-data i Lakehouse och notebook-filer från Microsoft Fabric (förhandsversion).
Viktigt!
Spegling för Azure Cosmos DB är för närvarande i förhandsversion. Produktionsarbetsbelastningar stöds inte under förhandsversionen. För närvarande stöds endast Azure Cosmos DB för NoSQL-konton.
Förutsättningar
- Ett befintligt Azure Cosmos DB för NoSQL-konto.
- Om du inte har en Azure-prenumeration kan du prova Azure Cosmos DB utan kostnad för NoSQL.
- Om du har en befintlig Azure-prenumeration skapar du ett nytt Azure Cosmos DB för NoSQL-konto.
- En befintlig infrastrukturkapacitet. Om du inte har någon befintlig kapacitet startar du en fabric-utvärderingsversion.
- Azure Cosmos DB för NoSQL-kontot måste konfigureras för infrastrukturspegling. Mer information finns i kontokrav.
Dricks
Under den offentliga förhandsversionen rekommenderar vi att du använder en test- eller utvecklingskopia av dina befintliga Azure Cosmos DB-data som kan återställas snabbt från en säkerhetskopia.
Konfigurera spegling och krav
Konfigurera spegling för Azure Cosmos DB för NoSQL-databasen. Om du är osäker på hur du konfigurerar spegling kan du läsa självstudien konfigurera speglad databas.
Gå till Infrastrukturportalen.
Skapa en ny anslutning och speglad databas med autentiseringsuppgifterna för ditt Azure Cosmos DB-konto.
Vänta tills replikeringen har slutfört den första ögonblicksbilden av data.
Få åtkomst till speglade data i Lakehouse och notebook-filer
Använd Lakehouse för att ytterligare utöka antalet verktyg som du kan använda för att analysera dina Azure Cosmos DB för NoSQL-speglade data. Här använder du Lakehouse för att skapa en Spark-notebook-fil för att köra frågor mot dina data.
Gå till fabric-portalens startsida igen.
I navigeringsmenyn väljer du Skapa.
Välj Skapa, leta upp avsnittet Dataingenjör ing och välj sedan Lakehouse.
Ange ett namn för Lakehouse och välj sedan Skapa.
Välj Hämta data och sedan Ny genväg. I listan med genvägsalternativ väljer du Microsoft OneLake.
Välj den speglade Azure Cosmos DB för NoSQL-databasen i listan över speglade databaser på din Infrastruktur-arbetsyta. Välj de tabeller som ska användas med Lakehouse, välj Nästa och välj sedan Skapa.
Öppna snabbmenyn för tabellen i Lakehouse och välj Ny eller befintlig anteckningsbok.
En ny notebook-fil öppnas automatiskt och läser in en dataram med hjälp av
SELECT LIMIT 1000.Kör frågor som
SELECT *att använda Spark.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)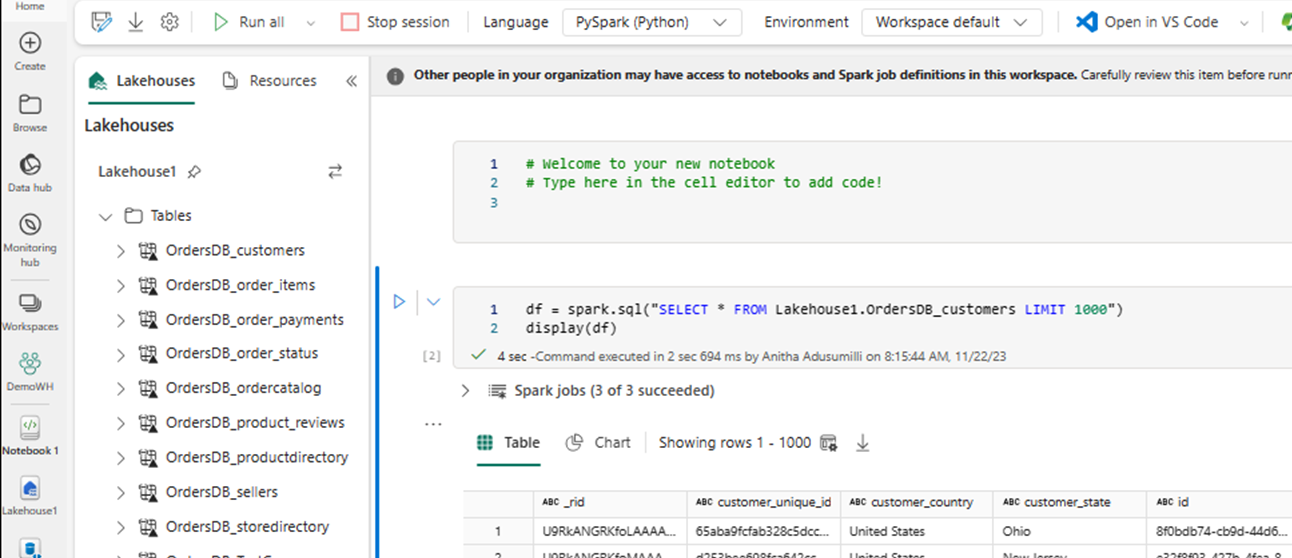
Kommentar
I det här exemplet förutsätts namnet på tabellen. Använd din egen tabell när du skriver Spark-frågan.

Skriv tillbaka med Spark
Slutligen kan du använda Spark- och Python-kod för att skriva tillbaka data till ditt Azure Cosmos DB-källkonto från notebook-filer i Fabric. Du kanske vill göra detta för att skriva tillbaka analysresultat till Cosmos DB, som sedan kan användas som serverplan för OLTP-program.
Skapa fyra kodceller i anteckningsboken.
Börja med att fråga dina speglade data.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")Dricks
Tabellnamnen i dessa exempelkodblock förutsätter ett visst dataschema. Ersätt gärna detta med dina egna tabell- och kolumnnamn.
Transformera och aggregera data.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))Konfigurera sedan Spark för att skriva tillbaka till ditt Azure Cosmos DB för NoSQL-konto med dina autentiseringsuppgifter, databasnamn och containernamn.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }Slutligen använder du Spark för att skriva tillbaka till källdatabasen.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()Kör alla kodceller.
Viktigt!
Skrivåtgärder till Azure Cosmos DB förbrukar enheter för begäranden (RU:er).