Handledning: Mata in data i ett datalager
Gäller för:✅ Warehouse i Microsoft Fabric
I den här självstudien lär du dig hur du matar in data från Microsoft Azure Storage till ett lager för att skapa tabeller.
Not
Den här självstudien är en del av ett heltäckande scenario. För att kunna slutföra den här självstudien måste du först slutföra de här självstudierna:
Mata in data
I den här uppgiften får du lära dig hur du matar in data i lagret för att skapa tabeller.
Kontrollera att arbetsytan som du skapade i den första självstudien är öppen.
I landningsfönstret för arbetsytan väljer du + Nytt objekt för att visa den fullständiga listan över tillgängliga objekttyper.
I listan, i avsnittet Hämta data, väljer du objekttypen Datapipeline.
I fönstret Ny pipeline, skriv in i rutan Namn
Load Customer Data.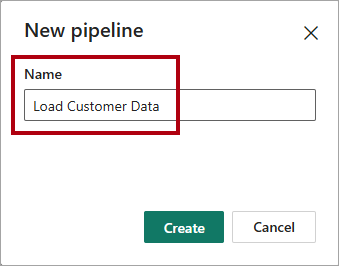
Om du vill provisionera pipelinen väljer du Skapa. Etableringen är klar när Skapa en datapipeline landningssidan visas.
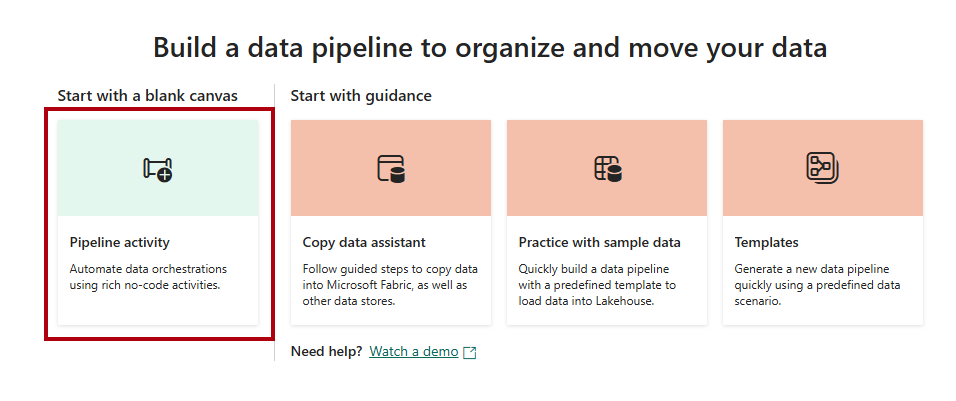
På startsidan för datapipelinen väljer du Pipeline-aktivitet.
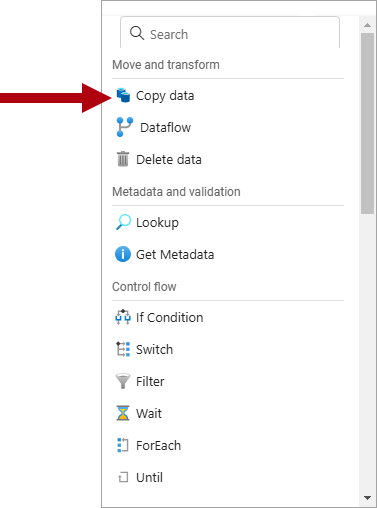
I menyn, från sektionen Flytta och transformera, välj Kopiera data.
På pipelinens designarbetsyta väljer du aktiviteten Kopiera data.
Om du vill konfigurera aktiviteten på sidan Allmänt ersätter du standardtexten med
CD Load dimension_customeri rutan Namn .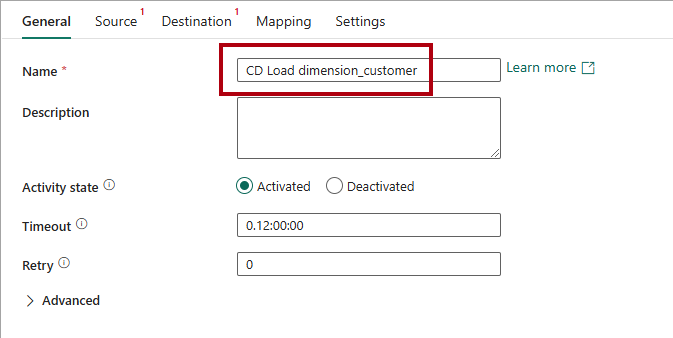
På sidan Source, i listrutan Anslutning, väljer du Mer för att visa alla datakällor som du kan välja från, inklusive datakällor i OneLake-katalogen.
Välj + Ny för att skapa en ny datakälla.
Sök efter och välj sedan Azure Blobs.
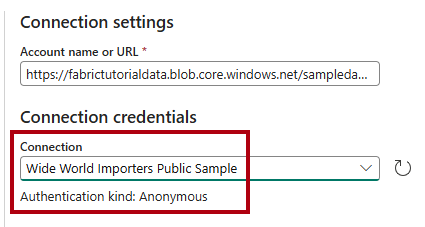
På sidan Connect-datakälla anger du
https://fabrictutorialdata.blob.core.windows.net/sampledata/i rutan Kontonamn eller URL .Observera att listrutan Anslutningsnamn fylls i automatiskt och att autentiseringstypen är inställd på Anonym.
Välj Anslut.
På sidan Source fyller du i följande inställningar för att få åtkomst till Parquet-filerna i datakällan:
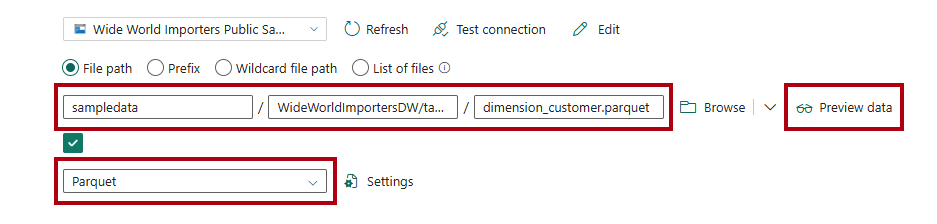
I rutorna Filsökväg anger du:
Filsökväg: Container:
sampledataFilsökväg – katalog:
WideWorldImportersDW/tablesFilsökväg – Filnamn:
dimension_customer.parquet
I listrutan Filformat väljer du Parquet.
Om du vill förhandsgranska data och testa att det inte finns några fel väljer du Förhandsgranska data.
På sidan Mål går du till listrutan Anslutning och väljer lagret
Wide World Importers.För alternativet Tabellväljer du alternativet Skapa tabell automatiskt.
I den första Tabell rutan anger du
dbo.I den andra rutan anger du
dimension_customer.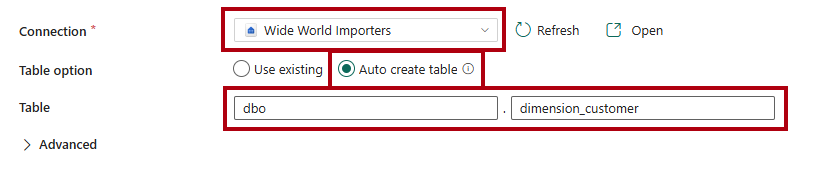
I menyfliksområdet Start väljer du Kör.
I Spara och köra? dialogruta väljer du Spara och kör för att pipelinen ska ladda tabellen
dimension_customer.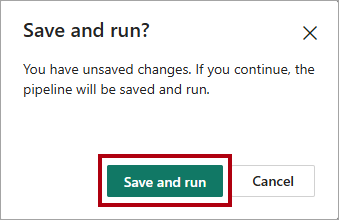
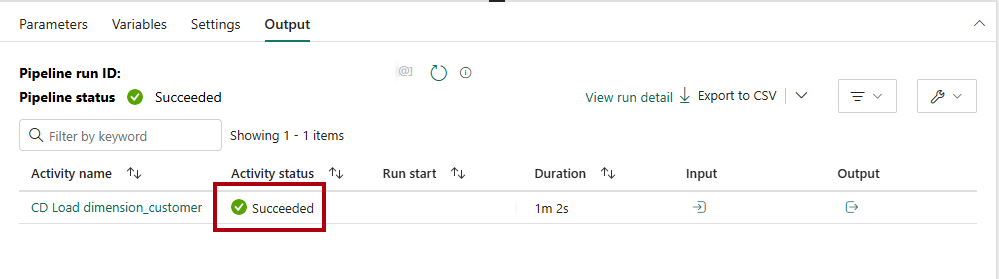
Om du vill övervaka kopieringsaktivitetens förlopp granskar du pipelinekörningsaktiviteterna på sidan Utdata (vänta tills den har slutförts med statusen Lyckades).