Bedömning av maskininlärningsmodeller med PREDICT i Microsoft Fabric
Med Microsoft Fabric kan användare operationalisera maskininlärningsmodeller med den skalbara funktionen PREDICT. Den här funktionen stöder batchbedömning i alla beräkningsmotorer. Användare kan generera batchförutsägelser direkt från en Microsoft Fabric-notebook-fil eller från objektsidan för en viss ML-modell.
I den här artikeln får du lära dig hur du använder PREDICT genom att skriva kod själv eller med hjälp av en guidad användargränssnittsupplevelse som hanterar batchbedömning åt dig.
Förutsättningar
Skaffa en Microsoft Fabric-prenumeration. Eller registrera dig för en kostnadsfri utvärderingsversion av Microsoft Fabric.
Logga in på Microsoft Fabric.
Använd upplevelseväxlaren till vänster på startsidan för att växla till Synapse Datavetenskap upplevelse.

Begränsningar
- Funktionen PREDICT stöds för närvarande för den här begränsade uppsättningen ML-modellsmaker:
- CatBoost
- Keras
- LightGBM
- ONNX
- Profet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT kräver att du sparar ML-modeller i MLflow-format, med deras signaturer ifyllda
- PREDICT stöder inte ML-modeller med multi-tensor-indata eller utdata
Anropa PREDICT från en notebook-fil
PREDICT stöder MLflow-paketerade modeller i Microsoft Fabric-registret. Om det redan finns en tränad och registrerad ML-modell på din arbetsyta kan du gå vidare till steg 2. Om inte, innehåller steg 1 exempelkod som hjälper dig att träna en exempellogistikregressionsmodell. Du kan använda den här modellen för att generera batchförutsägelser i slutet av proceduren.
Träna en ML-modell och registrera den med MLflow. Nästa kodexempel använder MLflow-API:et för att skapa ett maskininlärningsexperiment och startar sedan en MLflow-körning för en scikit-learn logistisk regressionsmodell. Modellversionen lagras och registreras sedan i Microsoft Fabric-registret. Besök hur du tränar ML-modeller med scikit-learn-resursen för mer information om träningsmodeller och spårning av dina egna experiment.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Läs in i testdata som en Spark DataFrame. För att generera batchförutsägelser med ML-modellen som tränades i föregående steg behöver du testdata i form av en Spark DataFrame. I följande kod ersätter du
testvariabelvärdet med dina egna data.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Skapa ett
MLFlowTransformerobjekt för att läsa in ML-modellen för slutsatsdragning. Om du vill skapa ettMLFlowTransformerobjekt för att generera batchförutsägelser måste du utföra följande åtgärder:- ange de
testDataFrame-kolumner som du behöver som modellindata (i det här fallet alla) - välj ett namn för den nya utdatakolumnen (i det här fallet
predictions) - ange rätt modellnamn och modellversion för generering av dessa förutsägelser.
Om du använder din egen ML-modell ersätter du värdena för indatakolumnerna, utdatakolumnens namn, modellnamn och modellversion.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- ange de
Generera förutsägelser med funktionen PREDICT. Om du vill anropa funktionen PREDICT använder du Transformer API, Spark SQL API eller en användardefinierad PySpark-funktion (UDF). I följande avsnitt visas hur du genererar batchförutsägelser med testdata och ML-modellen som definierats i föregående steg, med hjälp av de olika metoderna för att anropa funktionen PREDICT.
FÖRUTSÄGA med transformerings-API:et
Den här koden anropar funktionen PREDICT med Transformer-API:et. Om du använder din egen ML-modell ersätter du värdena för modellen och testar data.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
FÖRUTSÄGA med Spark SQL API
Den här koden anropar funktionen PREDICT med Spark SQL API. Om du använder din egen ML-modell ersätter du värdena för model_name, model_versionoch features med modellnamn, modellversion och funktionskolumner.
Kommentar
Användning av Spark SQL API för förutsägelsegenerering kräver fortfarande att ett MLFlowTransformer objekt skapas (som visas i steg 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT med en användardefinierad funktion
Den här koden anropar funktionen PREDICT med en PySpark UDF. Om du använder din egen ML-modell ersätter du värdena för modellen och funktionerna.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generera PREDICT-kod från en ML-modells objektsida
På objektsidan för valfri ML-modell kan du välja något av dessa alternativ för att starta batchförutsägelsegenereringen för en specifik modellversion med funktionen PREDICT:
- Kopiera en kodmall till en notebook-fil och anpassa parametrarna själv
- Använda en guidad användargränssnittsupplevelse för att generera PREDICT-kod
Använda en guidad användargränssnittsupplevelse
Den guidade användargränssnittsupplevelsen vägleder dig genom följande steg:
- Välj källdata för bedömning
- Mappa data korrekt till dina ML-modellindata
- Ange målet för dina modellutdata
- Skapa en notebook-fil som använder PREDICT för att generera och lagra förutsägelseresultat
Om du vill använda den guidade upplevelsen
Gå till objektsidan för en viss ML-modellversion.
I listrutan Använd den här versionen väljer du Använd den här modellen i guiden.
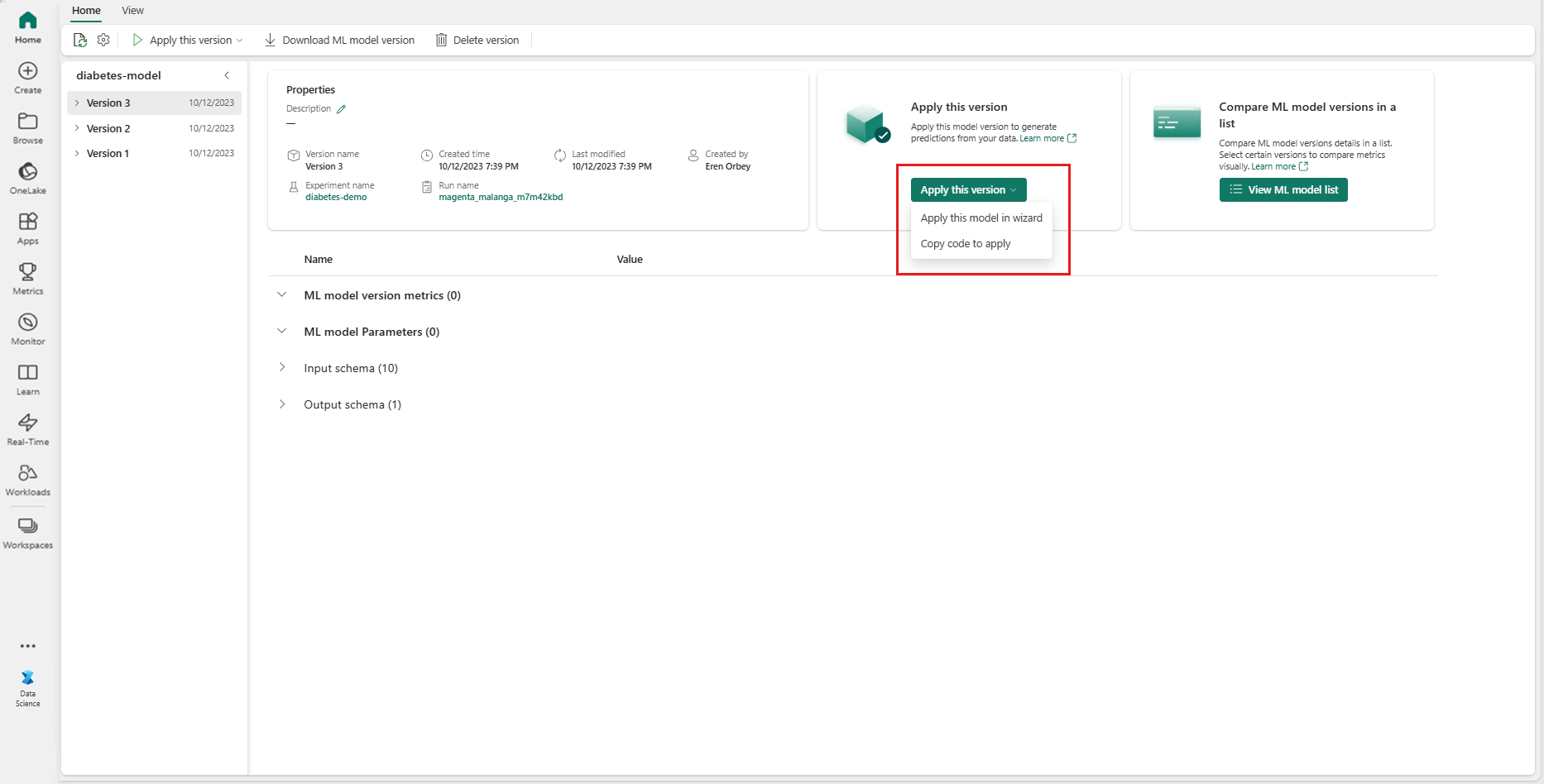
I steget "Välj indatatabell" öppnas fönstret "Tillämpa ML-modellförutsägelser".
Välj en indatatabell från ett lakehouse på din aktuella arbetsyta.
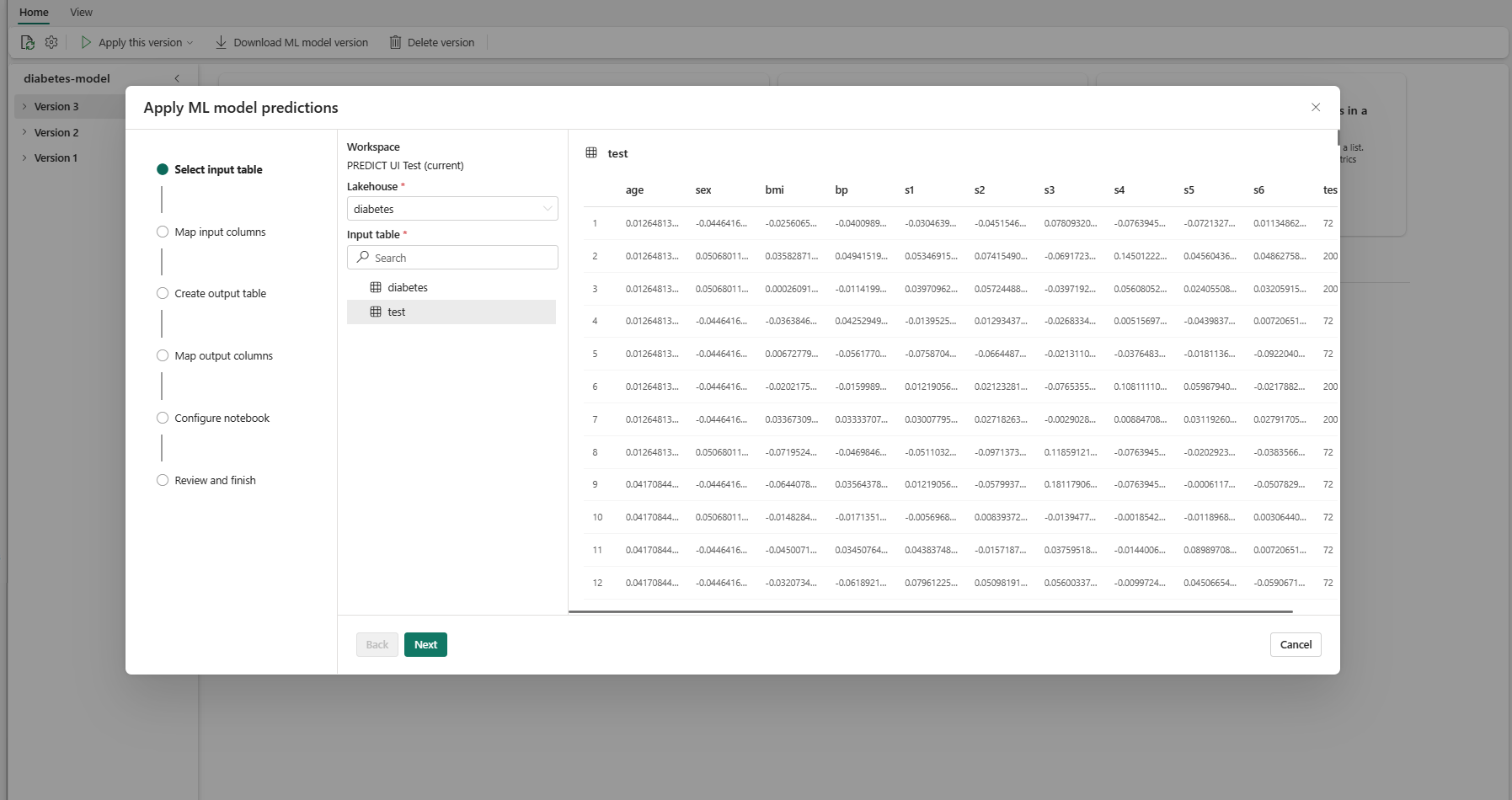
Välj Nästa för att gå till steget "Mappa indatakolumner".
Mappa kolumnnamn från källtabellen till ML-modellens indatafält, som hämtas från modellens signatur. Du måste ange en indatakolumn för alla obligatoriska fält i modellen. Dessutom måste källkolumndatatyperna matcha modellens förväntade datatyper.
Dricks
Guiden fyller i den här mappningen i förväg om namnen på indatatabellkolumnerna matchar kolumnnamnen som loggas i ML-modellsignaturen.
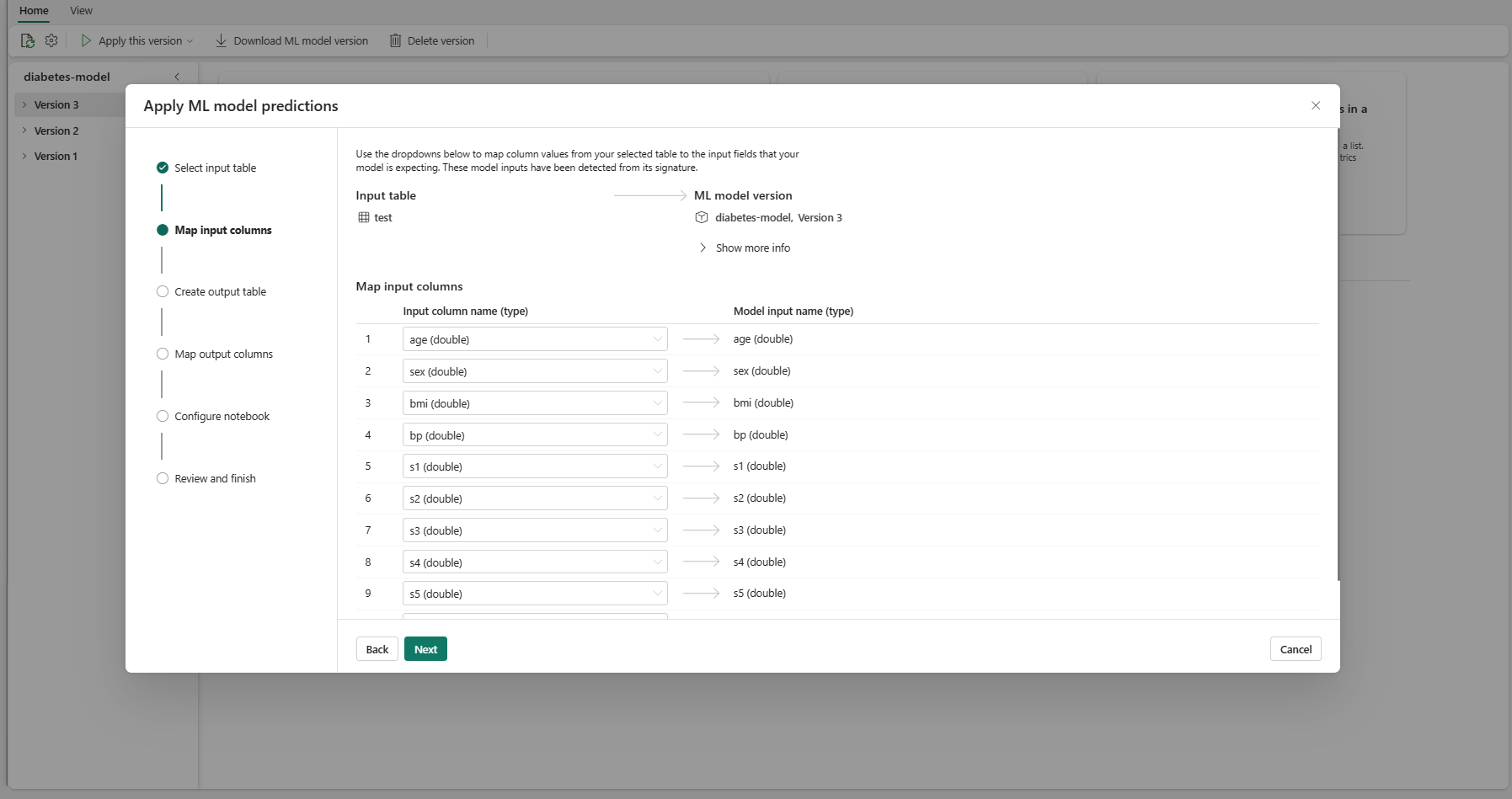
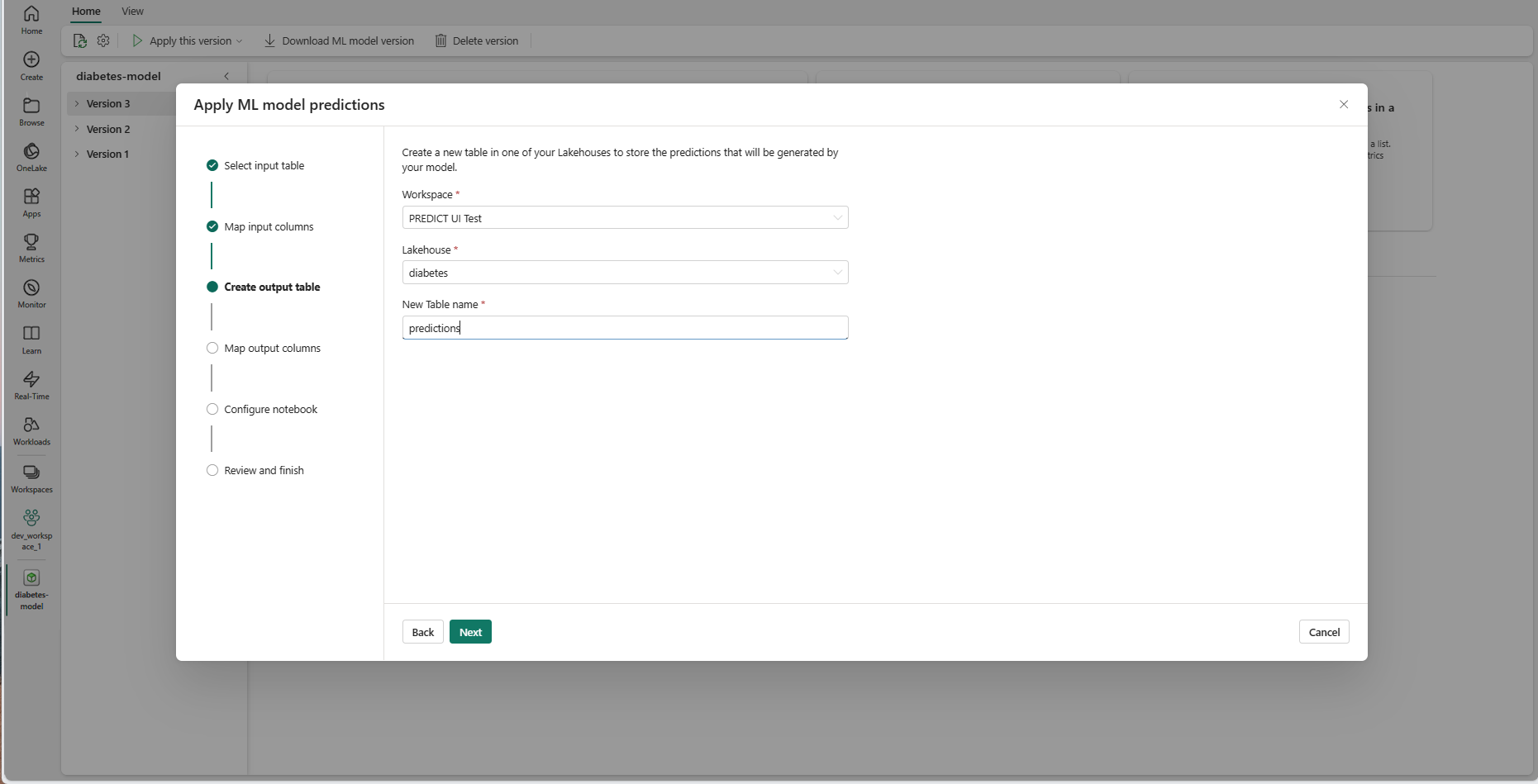
Välj Nästa för att gå till steget "Skapa utdatatabell".
Ange ett namn för en ny tabell i den valda lakehouse för din aktuella arbetsyta. Den här utdatatabellen lagrar ML-modellens indatavärden och lägger till förutsägelsevärdena i den tabellen. Som standard skapas utdatatabellen i samma lakehouse som indatatabellen. Du kan ändra målet lakehouse.
Välj Nästa för att gå till steget "Mappa utdatakolumner".
Använd de angivna textfälten för att namnge kolumnerna i utdatatabellen som lagrar ML-modellförutsägelserna.
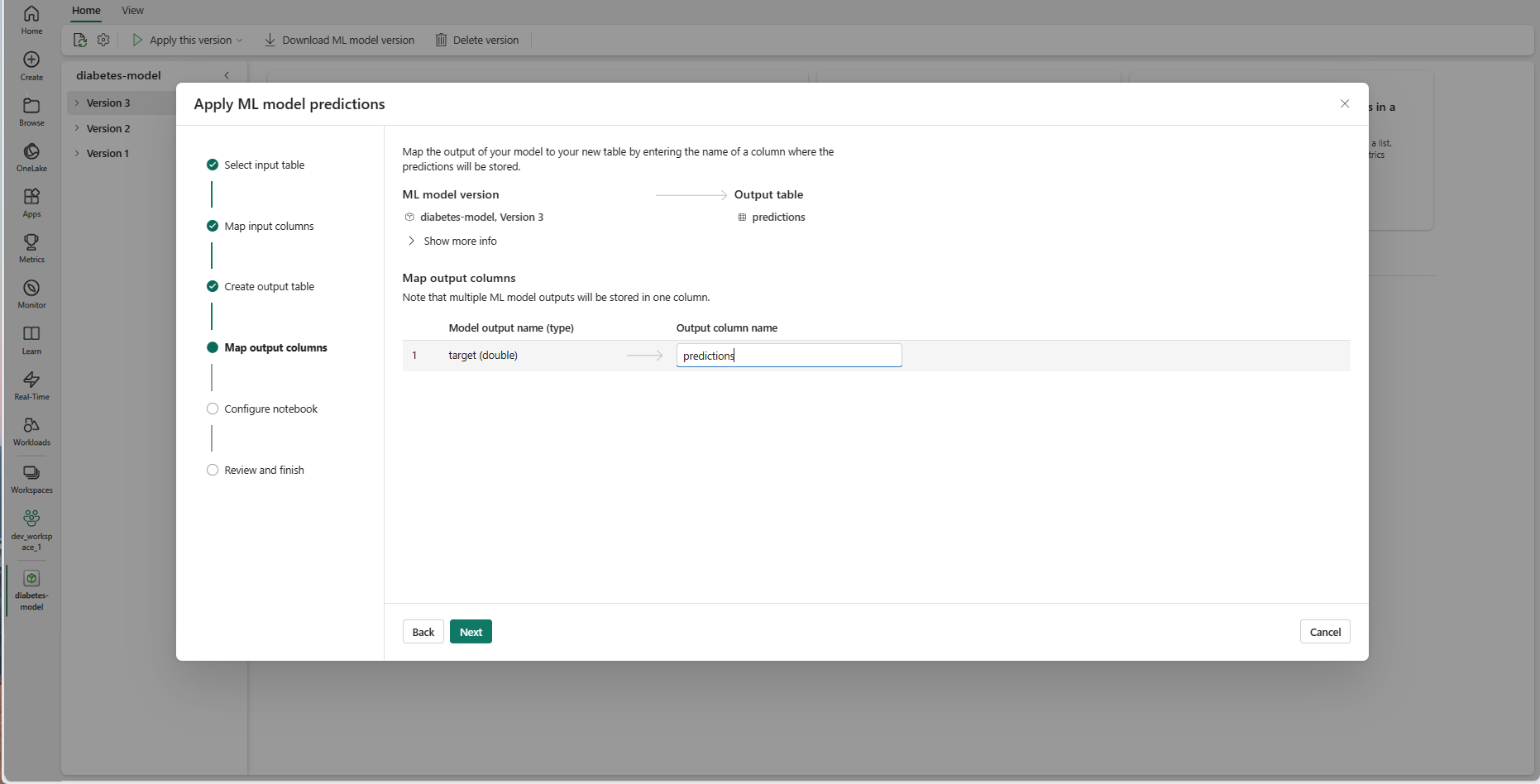
Välj Nästa för att gå till steget "Konfigurera anteckningsbok".
Ange ett namn på en ny notebook-fil som kör den genererade PREDICT-koden. Guiden visar en förhandsversion av den genererade koden i det här steget. Om du vill kan du kopiera koden till Urklipp och klistra in den i en befintlig anteckningsbok.
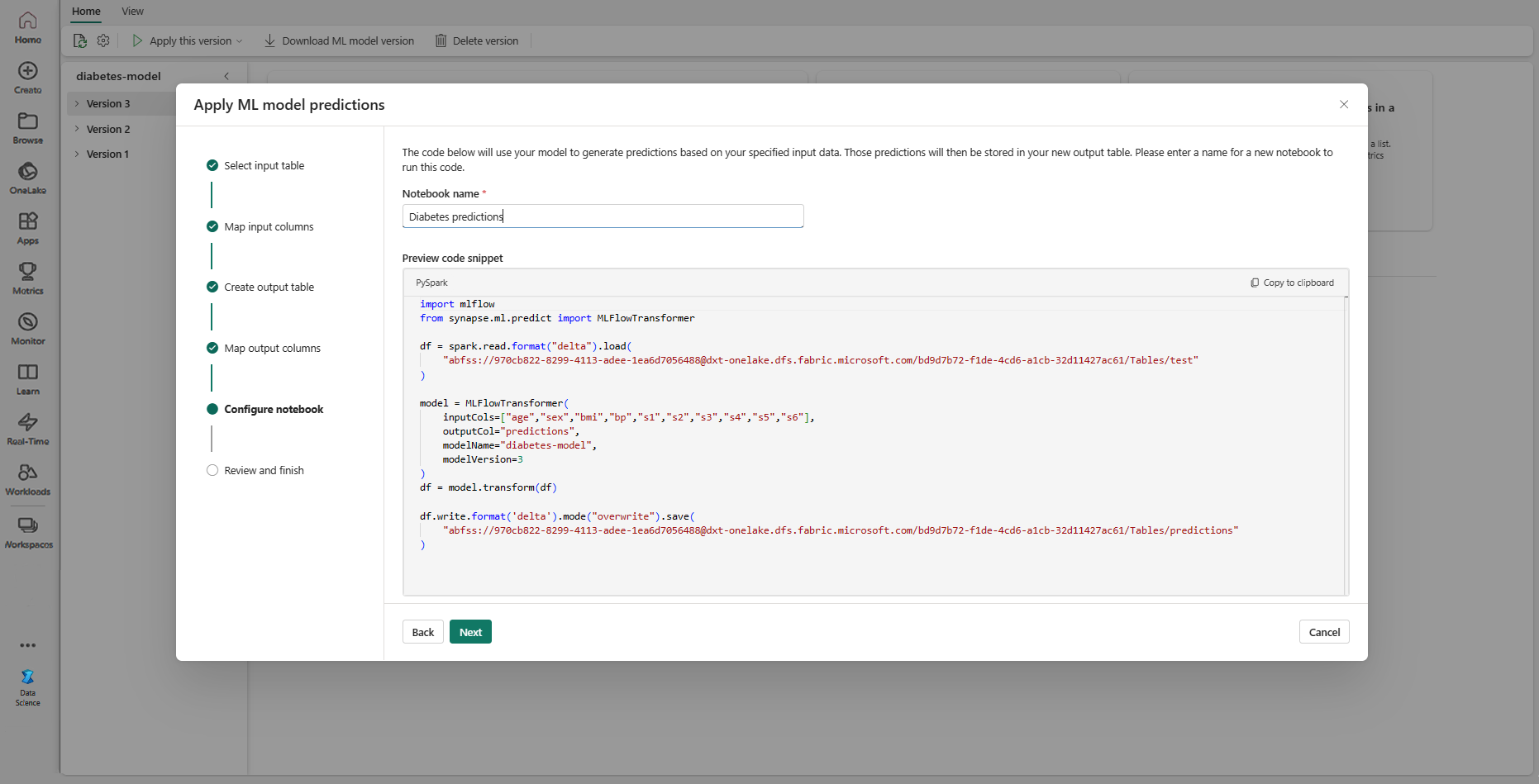
Välj Nästa för att gå till steget "Granska och slutför".
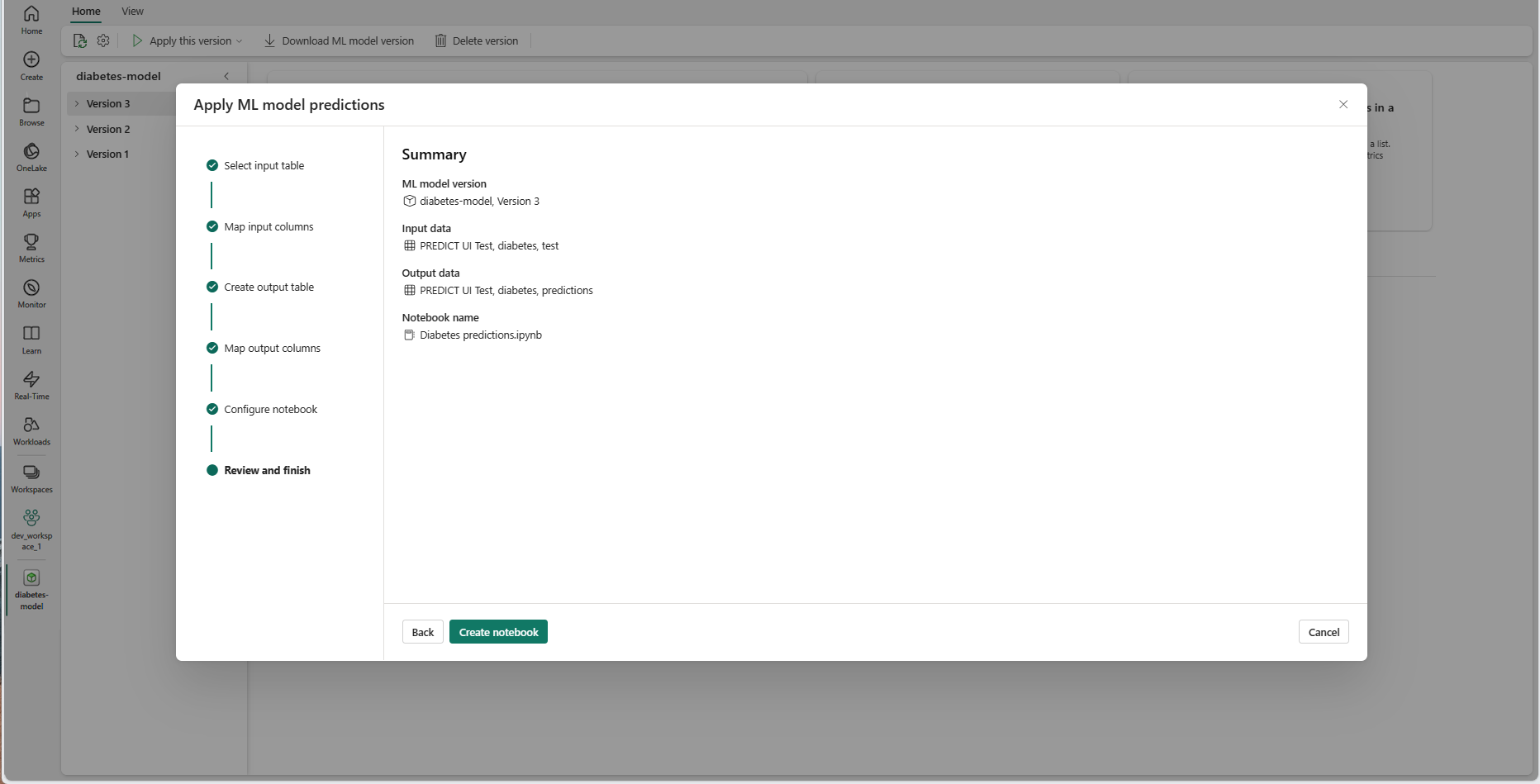
Granska informationen på sammanfattningssidan och välj Skapa anteckningsbok för att lägga till den nya notebook-filen med dess genererade kod på arbetsytan. Du tas direkt till anteckningsboken, där du kan köra koden för att generera och lagra förutsägelser.







Använda en anpassningsbar kodmall
Så här använder du en kodmall för att generera batchförutsägelser:
- Gå till objektsidan för en viss ML-modellversion.
- Välj Kopiera kod som ska tillämpas i listrutan Tillämpa den här versionen . Med markeringen kan du kopiera en anpassningsbar kodmall.
Du kan klistra in den här kodmallen i en notebook-fil för att generera batchförutsägelser med ML-modellen. Om du vill köra kodmallen måste du ersätta följande värden manuellt:
<INPUT_TABLE>: Filsökvägen för tabellen som tillhandahåller indata till ML-modellen<INPUT_COLS>: En matris med kolumnnamn från indatatabellen som ska matas till ML-modellen<OUTPUT_COLS>: Ett namn på en ny kolumn i utdatatabellen som lagrar förutsägelser<MODEL_NAME>: Namnet på ML-modellen som ska användas för att generera förutsägelser<MODEL_VERSION>: Den version av ML-modellen som ska användas för att generera förutsägelser<OUTPUT_TABLE>: Filsökvägen för tabellen som lagrar förutsägelserna

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)