Snabbstart: Flytta och transformera data med dataflöden och datapipelines
I den här guiden lär du dig hur upplevelsen av dataflöden och datapipelines kan skapa en kraftfull och omfattande Data Factory-lösning.
Förutsättningar
För att komma igång måste du ha följande förutsättningar:
- Ett klientkonto med en aktiv prenumeration. Skapa ett kostnadsfritt konto.
- Kontrollera att du har en Microsoft Fabric-aktiverad arbetsyta: Skapa en arbetsyta som inte är den förinställda Min arbetsyta.
- En Azure SQL-databas med tabelldata.
- Ett Blob Storage-konto.
Dataflöden jämfört med pipelines
Med Dataflows Gen2 kan du använda ett gränssnitt med låg kod och över 300 data och AI-baserade transformeringar för att enkelt rensa, förbereda och transformera data med större flexibilitet än något annat verktyg. Med datapipelines kan du använda avancerade funktioner för dataorkestrering för att skapa flexibla dataarbetsflöden som uppfyller företagets behov. I en pipeline kan du skapa logiska grupper av aktiviteter som utför en uppgift, vilket kan vara att anropa ett dataflöde för att rensa och förbereda dina data. Även om det finns en viss överlappning mellan de två, beror valet av vilken som ska användas för ett specifikt scenario på om du behöver alla fördelar med pipelines eller kan använda de enklare men mer begränsade funktionerna i dataflöden. Mer information finns i Fabric-beslutsguiden
Transformera data med dataflöden
Följ de här stegen för att konfigurera ditt dataflöde.
Steg 1: Skapa ett dataflöde
Välj din Fabric-aktiverade arbetsyta och välj sedan Ny. Välj sedan Dataflöde Gen2.
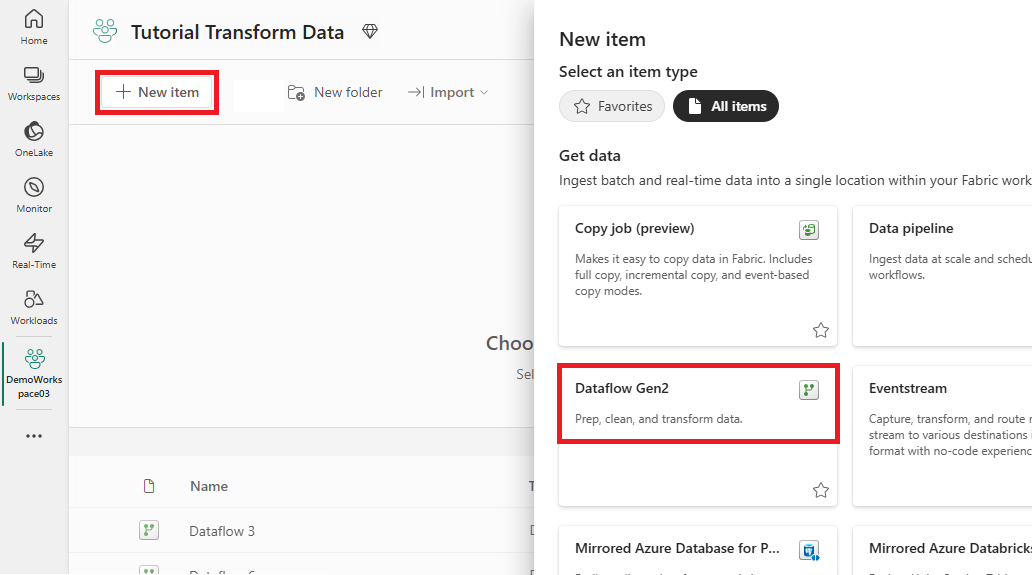
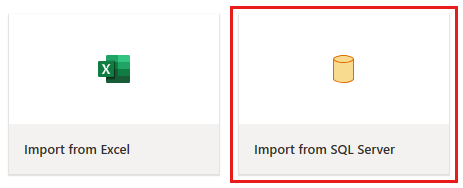
Fönstret dataflödesredigerare visas. Välj kortet Importera från SQL Server.


Steg 2: Hämta data
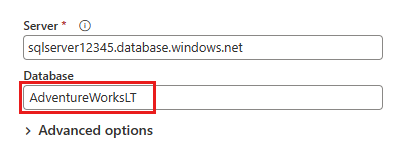
I dialogrutan Anslut till datakälla som visas härnäst anger du informationen för att ansluta till din Azure SQL-databas och väljer sedan Nästa. I det här exemplet använder du AdventureWorksLT exempeldatabas som konfigurerades när du konfigurerade Azure SQL-databasen i förhandskraven.
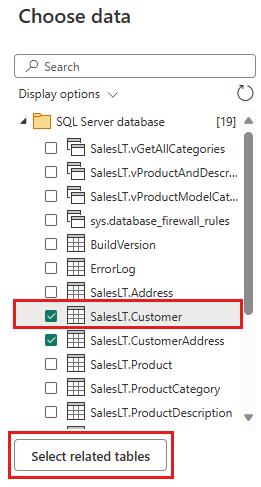
Välj de data som du vill transformera och välj sedan Skapa. För den här snabbstarten väljer du SalesLT.Customer från AdventureWorksLT exempeldata som tillhandahålls för Azure SQL DB och sedan knappen Välj relaterade tabeller för att automatiskt inkludera två andra relaterade tabeller.


Steg 3: Transformera dina data
Om den inte är markerad väljer du knappen diagramvy längs statusfältet längst ned på sidan eller väljer diagramvy under menyn Visa längst upp i Power Query-redigeraren. Något av dessa alternativ kan växla diagramvyn.
Högerklicka på frågan SalesLT Customer eller välj den lodräta ellipsen till höger om frågan och välj sedan Slå samman frågor.
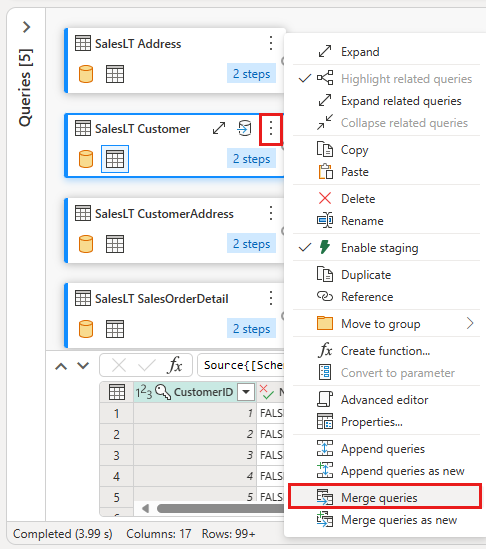
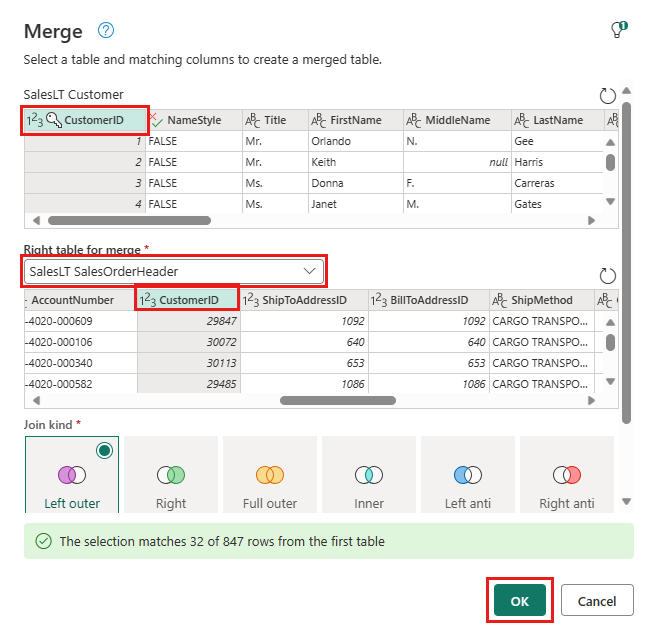
Konfigurera sammanfogningen genom att välja SalesLTOrderHeader tabell som höger tabell för kopplingen, kolumnen CustomerID från varje tabell som kopplingskolumn och vänster yttre som kopplingstyp. Välj sedan OK för att lägga till kopplingsfrågan.
Välj knappen Lägg till datamål, som ser ut som en databassymbol med en pil ovanför, från den nya kopplingsfrågan som du skapade. Välj sedan Azure SQL-databas som måltyp.
Ange information för din Azure SQL-databasanslutning där sammanslagningsfrågan ska publiceras. I det här exemplet kan du använda databasen AdventureWorksLT som vi också använde som datakälla för målet.
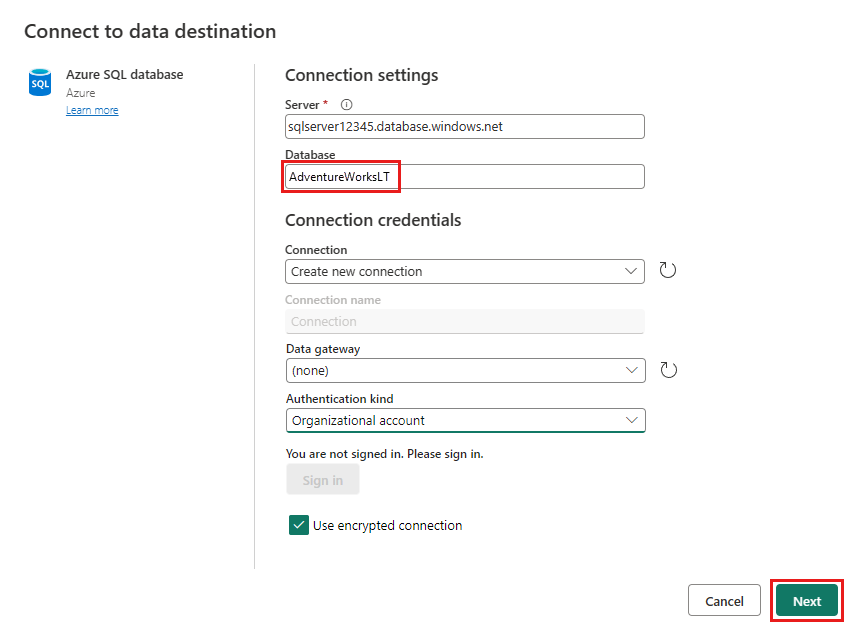
Välj en databas för att lagra data och ange ett tabellnamn och välj sedan Nästa.
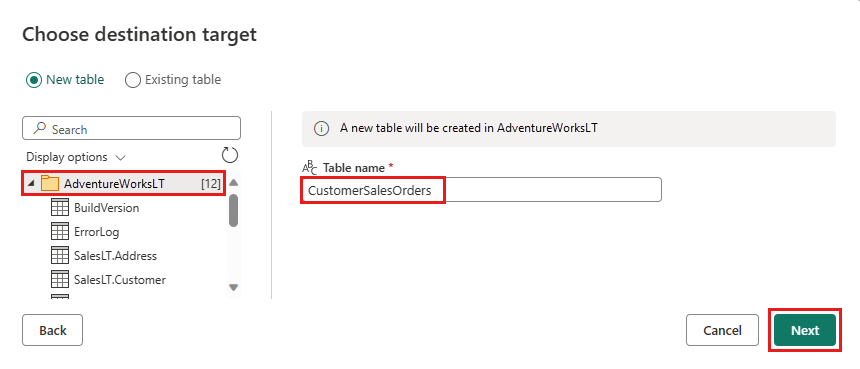
Du kan lämna standardinställningarna i dialogrutan Välj målinställningar och bara välja Spara inställningar utan att göra några ändringar här.
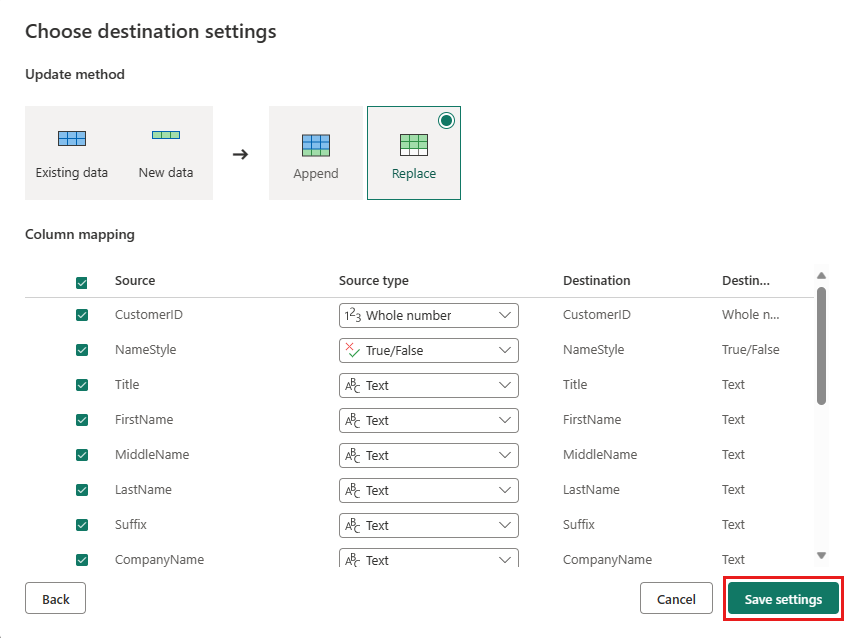
Välj Publicera tillbaka på dataflödesredigerarens sida för att publicera dataflödet.



Flytta data med datapipelines
Nu när du har skapat ett Dataflöde Gen2 kan du använda det i en pipeline. I det här exemplet kopierar du data som genererats från dataflödet till textformat i ett Azure Blob Storage-konto.
Steg 1: Skapa en ny datapipeline
Välj Nyfrån din arbetsyta och välj sedan Datapipeline.
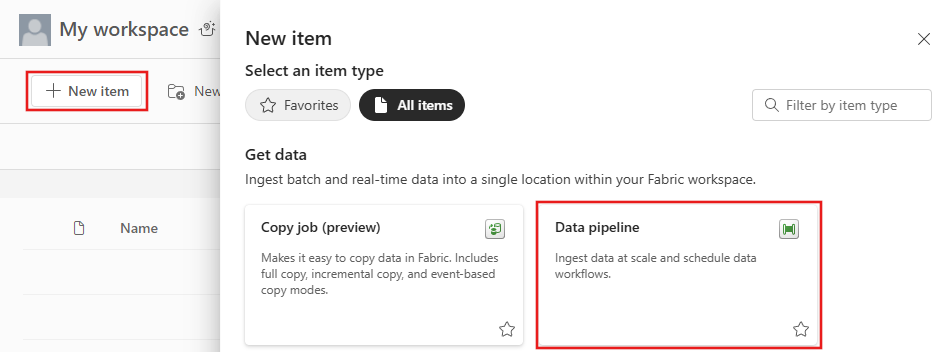
Namnge pipelinen och välj sedan Skapa.
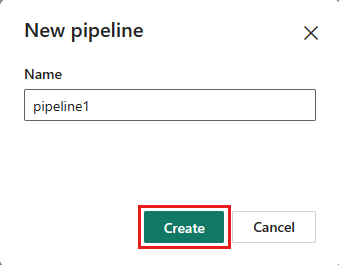
Steg 2: Konfigurera ditt dataflöde
Lägg till en ny dataflödesaktivitet i datapipelinen genom att välja Dataflöde på fliken Aktiviteter.

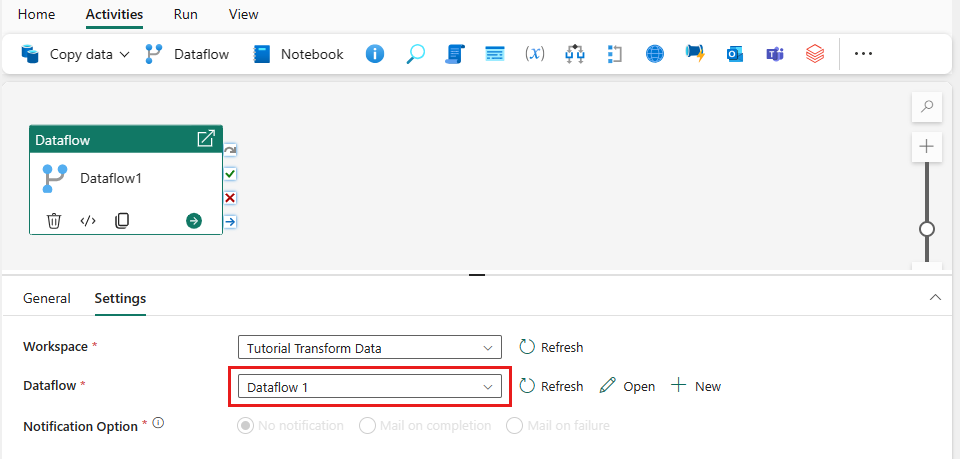
Välj dataflödet på pipelinearbetsytan, och sedan fliken Inställningar. Välj det dataflöde du skapade tidigare från listrutan.
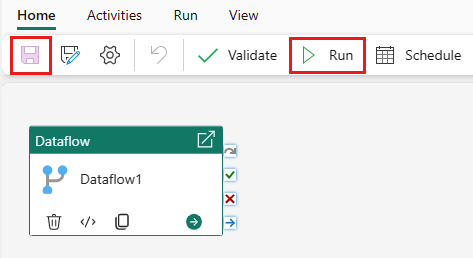
Välj Sparaoch sedan Kör för att köra dataflödet för att först fylla i den sammanfogade frågetabell som du skapade i föregående steg.
Steg 3: Använd kopieringsassistenten för att lägga till en kopieringsaktivitet
Välj Kopiera data på arbetsytan för att öppna verktyget Copy Assistant för att komma igång. Eller välj Använd kopieringsassistenten från listrutan Kopiera data under fliken Aktiviteter i menyfliksområdet.
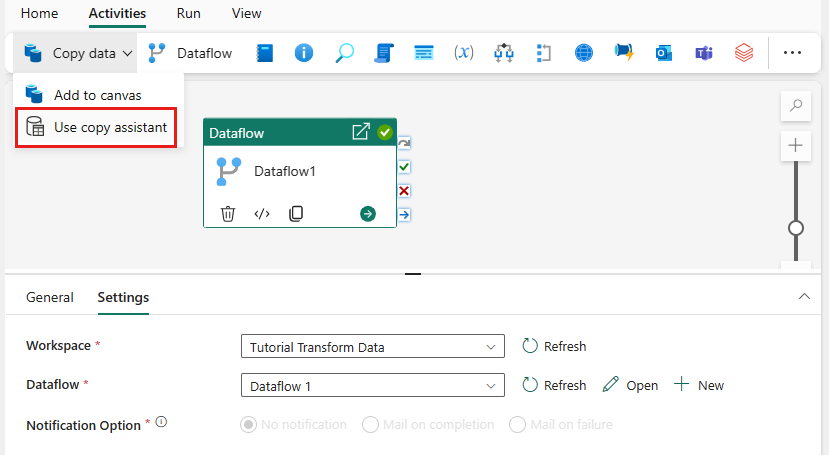
Välj din datakälla genom att välja en typ av datakälla. I den här självstudien använder du den Azure SQL Database som du tidigare använde när du skapade dataflödet, för att generera en ny sammanslagningsfråga. Rulla nedåt under exempeldataerbjudandena och välj fliken Azure och sedan Azure SQL Database-. Välj sedan Nästa för att fortsätta.
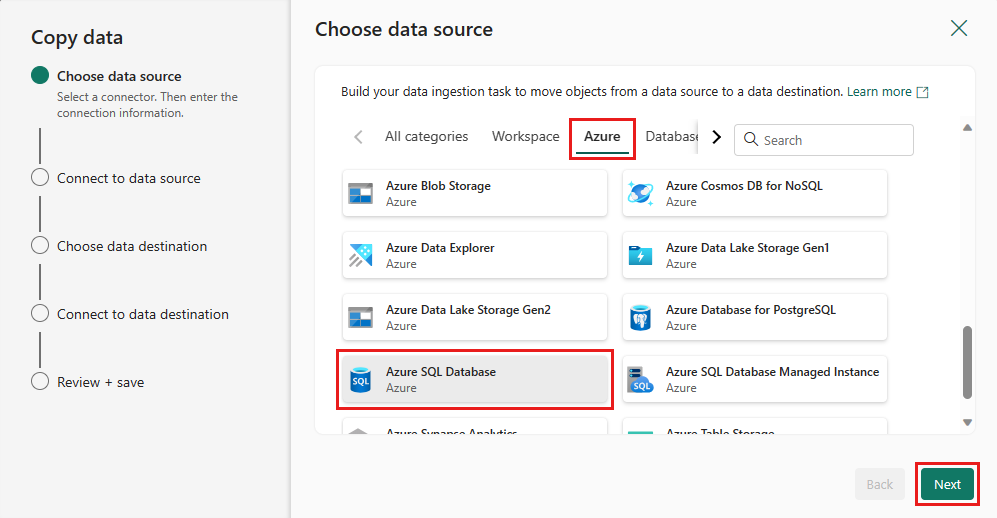
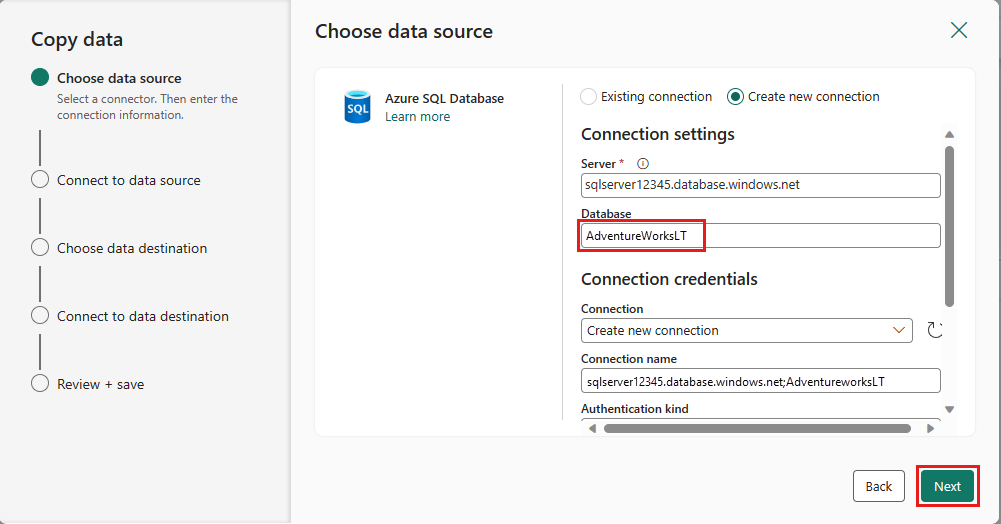
Skapa en anslutning till datakällan genom att välja Skapa ny anslutning. Fyll i nödvändig anslutningsinformation på panelen och ange AdventureWorksLT för databasen, där vi genererade sammanslagningsfrågan i dataflödet. Välj sedan Nästa.
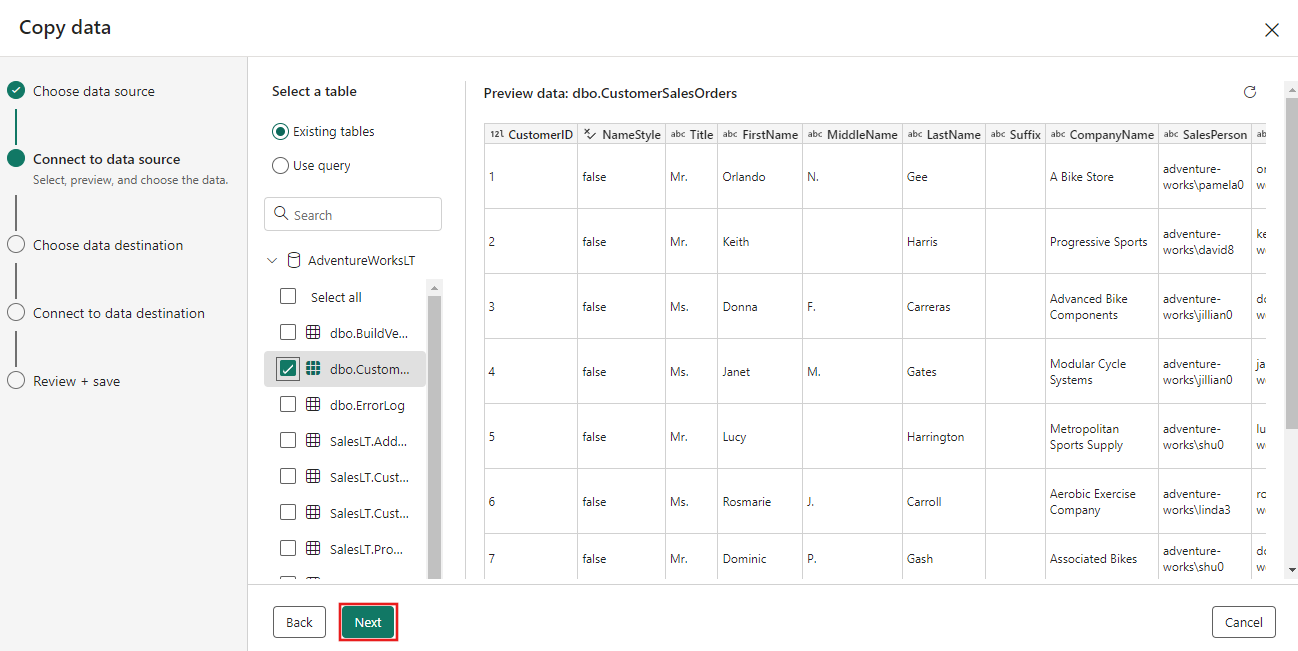
Välj den tabell som du genererade i dataflödessteget tidigare och välj sedan Nästa.
Som mål väljer du Azure Blob Storage- och väljer sedan Nästa.
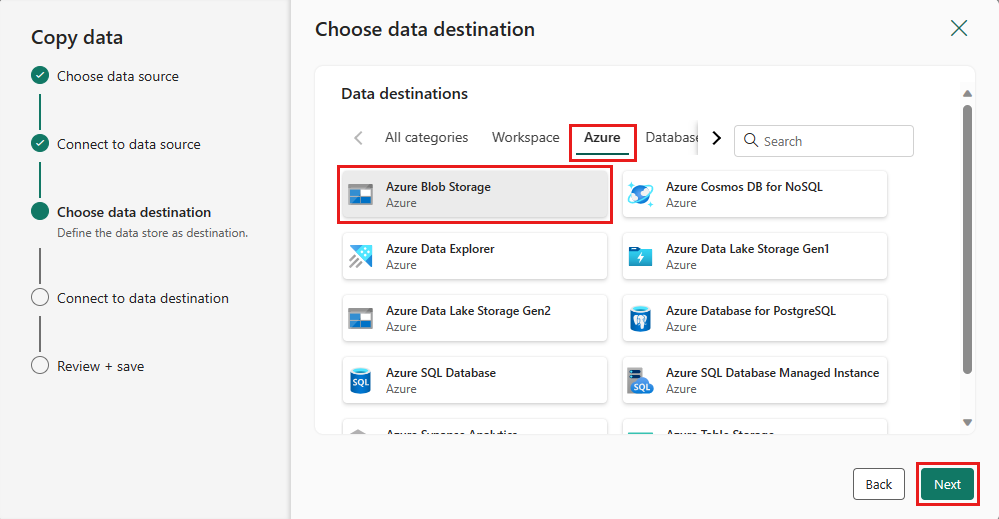
Skapa en anslutning till målet genom att välja Skapa ny anslutning. Ange information för anslutningen och välj sedan Nästa.
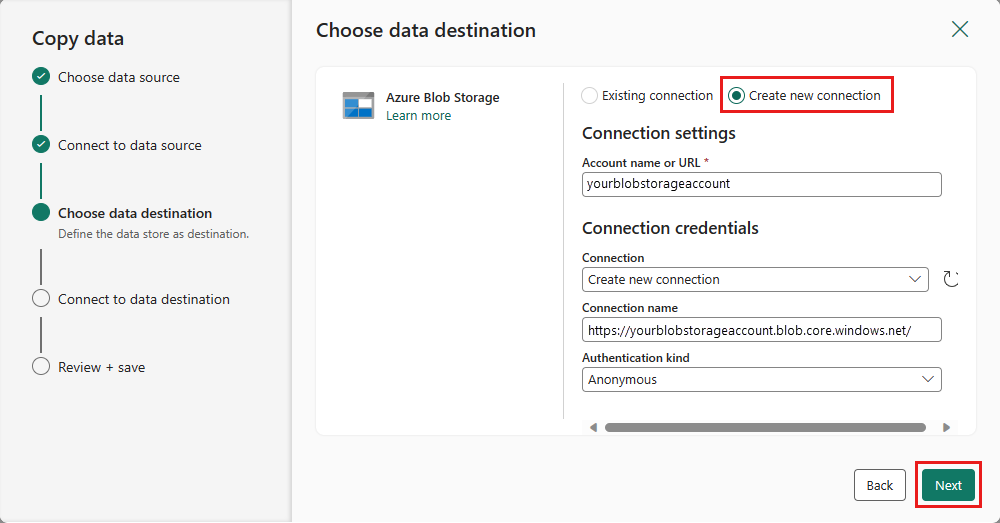
Välj sökvägen mapp och ange ett Filnamnoch välj sedan Nästa.
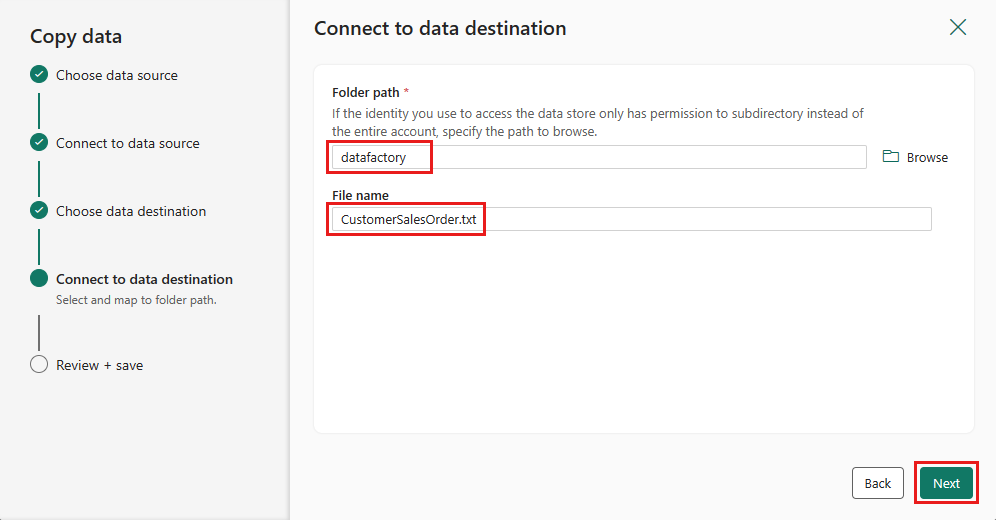
Välj Nästa igen för att acceptera standardfilformatet, kolumn avgränsare, rad avgränsare och komprimeringstyp, om du vill inkludera en rubrik.
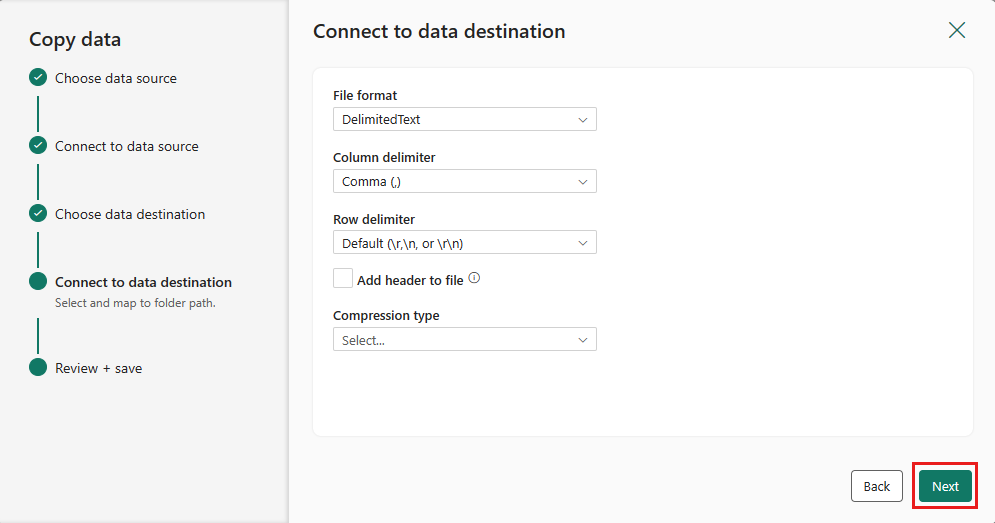
Slutför inställningarna. Granska och välj sedan Spara + Kör för att slutföra processen.
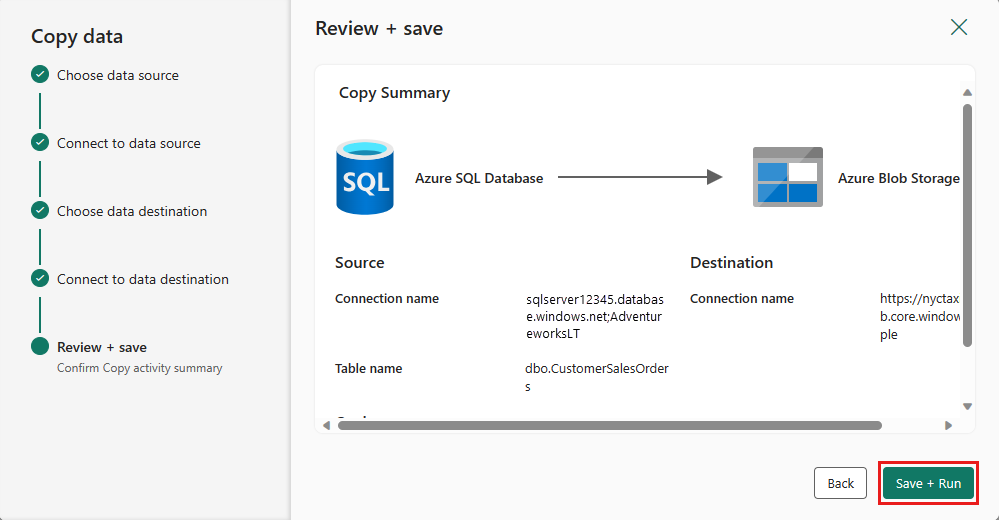
Steg 5: Utforma din datapipeline och spara för att köra och läsa in data
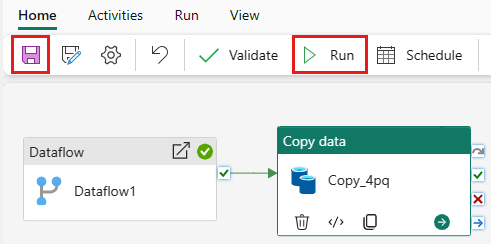
Om du vill köra aktiviteten Kopiera efter aktiviteten Dataflöde, drar du från Framgångsrik på aktiviteten Dataflöde till aktiviteten Kopiera. Aktiviteten Kopiera körs bara efter att aktiviteten Dataflöde har slutförts.

Välj Spara för att spara din datapipeline. Välj sedan Kör för att köra din datapipeline och importera din data.
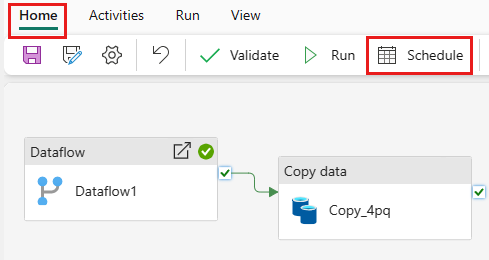
Schemalägg körning av pipeline
När du har utvecklat och testat din pipeline kan du schemalägga den så att den körs automatiskt.
På fliken Start i pipeline-redigeringsfönstret väljer du Schemalägg.
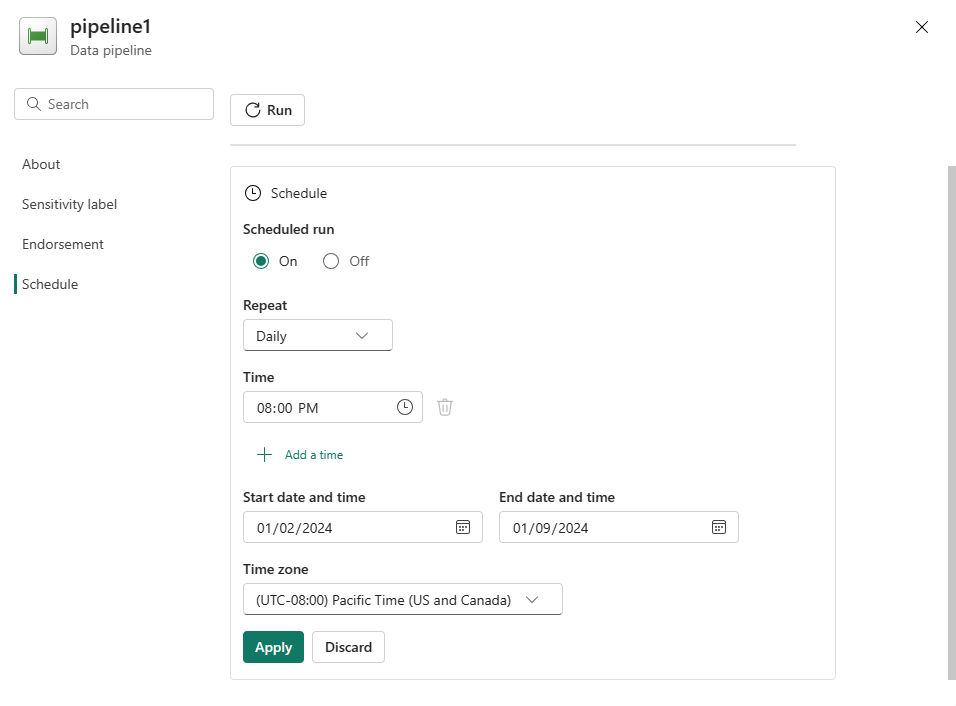
Konfigurera schemat efter behov. Exemplet här schemalägger pipelinen så att den körs dagligen kl. 20:00 till slutet av året.
Relaterat innehåll
Det här exemplet visar hur du skapar och konfigurerar ett Dataflöde Gen2 för att skapa en sammanslagningsfråga och lagra den i en Azure SQL-databas och sedan kopierar data från databasen till en textfil i Azure Blob Storage. Du har lärt dig att:
- Skapa ett dataflöde.
- Transformera data med dataflödet.
- Skapa en datapipeline med hjälp av dataflödet.
- Beställ körningen av stegen i pipelinen.
- Kopiera data med kopieringsassistenten.
- Kör och schemalägg din datapipeline.
Gå vidare för att lära dig mer om hur du övervakar pipelinekörningarna.