Transformera data genom att köra en Spark-jobbdefinitionsaktivitet
Med aktiviteten Spark-jobbdefinition i Data Factory för Microsoft Fabric kan du skapa anslutningar till dina Spark-jobbdefinitioner och köra dem från en datapipeline.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
- Ett klientkonto med en aktiv prenumeration. Skapa ett konto kostnadsfritt.
- En arbetsyta skapas.
Lägga till en Spark-jobbdefinitionsaktivitet i en pipeline med användargränssnittet
Skapa en ny datapipeline på din arbetsyta.
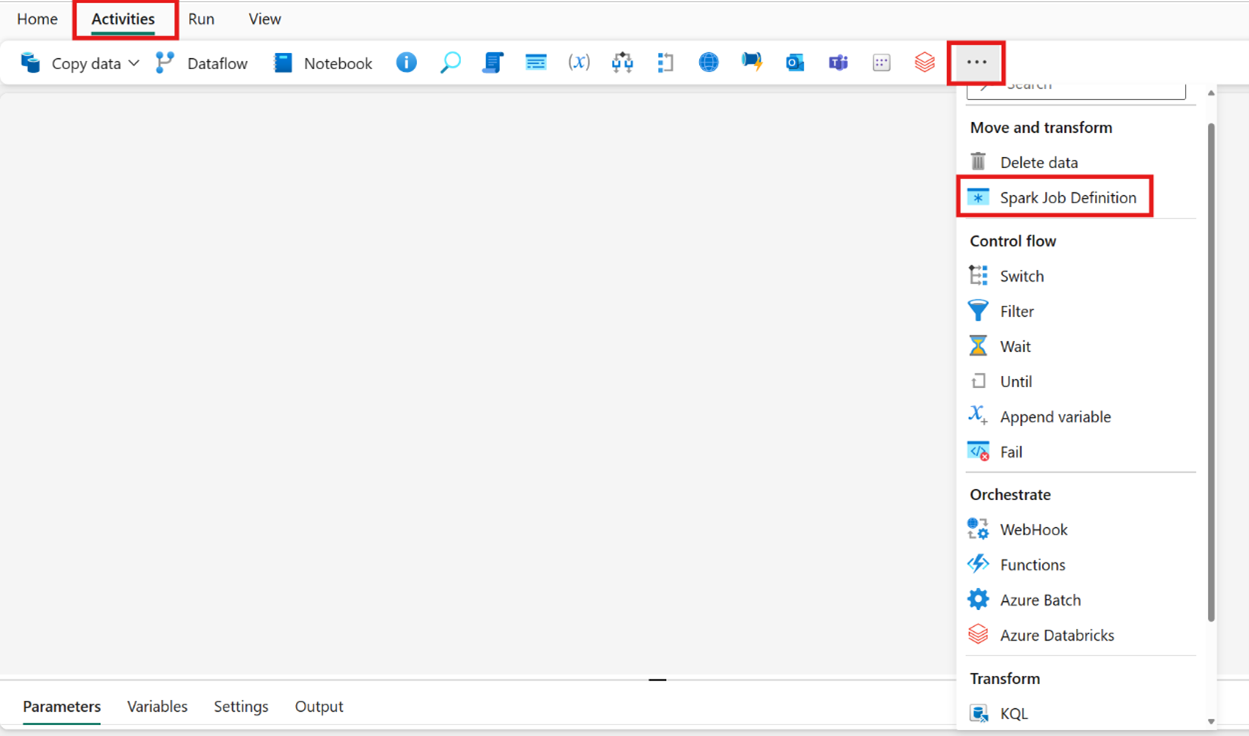
Sök efter Spark-jobbdefinition från startskärmskortet och välj det eller välj aktiviteten i aktivitetsfältet för att lägga till den i pipelinearbetsytan.
Skapa aktiviteten från startskärmskortet:
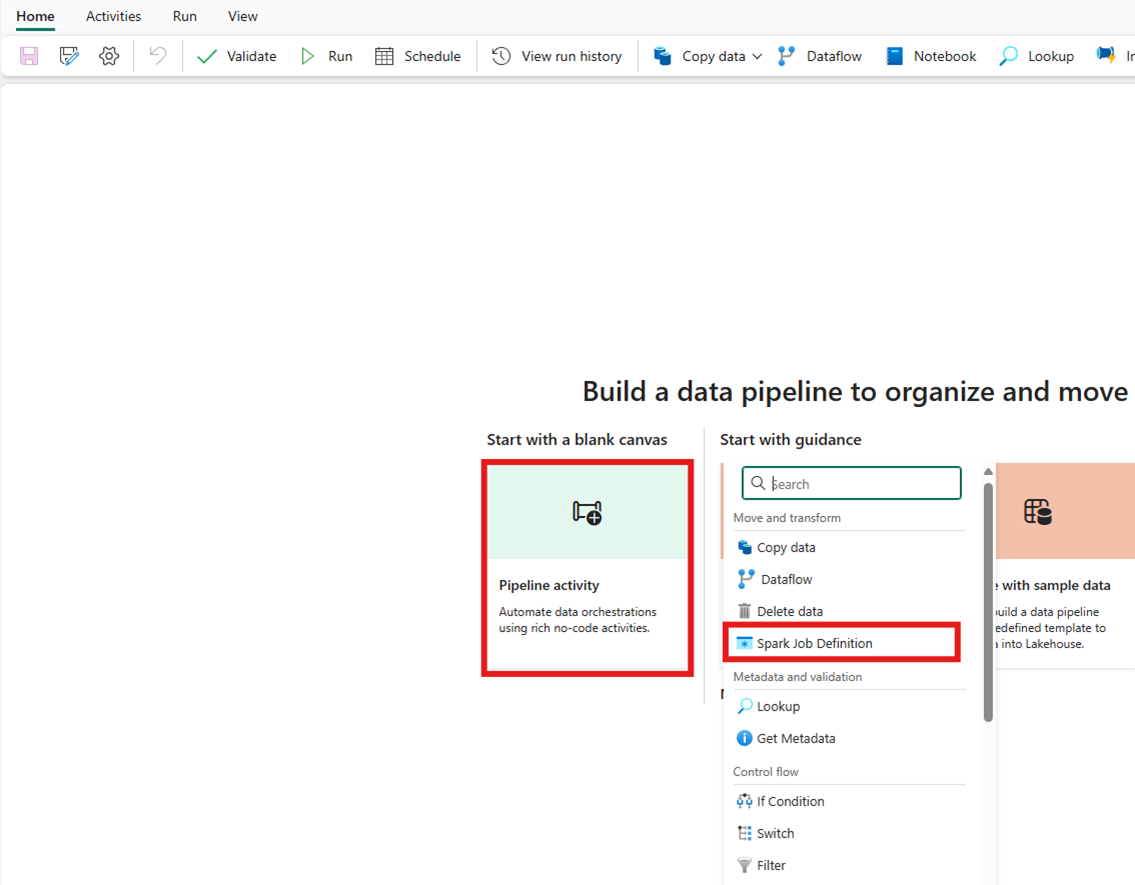
Skapa aktiviteten från aktivitetsfältet:
Välj den nya Spark-jobbdefinitionsaktiviteten på arbetsytan i pipelineredigeraren om den inte redan är markerad.
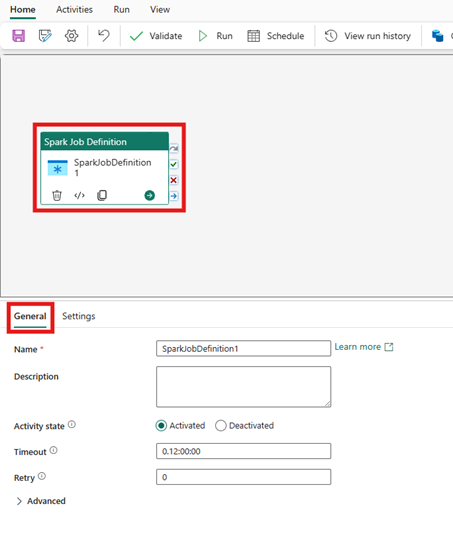
Se Allmänna inställningar vägledning för att konfigurera de alternativ som finns på fliken Allmänna inställningar.



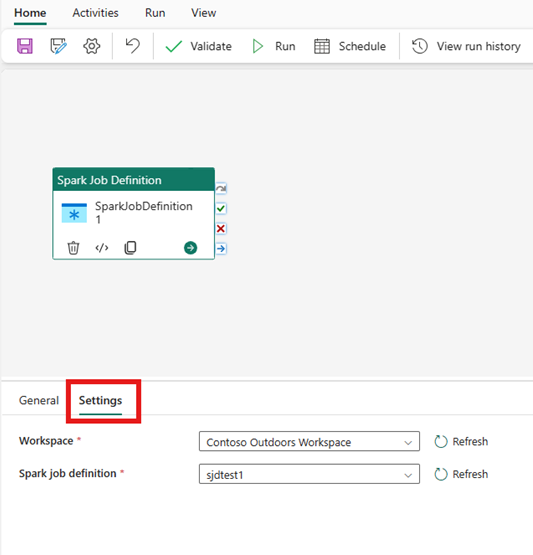
Aktivitetsinställningar för Spark-jobbdefinition
Välj fliken Inställningar i panelen för aktivitetsegenskaper och välj sedan den Fabric-arbetsyta som innehåller den Spark-jobb-definition som du vill köra.
Kända begränsningar
Aktuella begränsningar i Spark-jobbdefinitionsaktiviteten för Fabric Data Factory visas här. Det här avsnittet kan komma att ändras.
- Vi stöder för närvarande inte att skapa en ny Spark-jobbdefinitionsaktivitet inom aktiviteten (under Inställningar)
- Stöd för parameterisering är inte tillgängligt.
- Även om vi stöder övervakning av aktiviteten via utdatafliken kan du inte övervaka Spark-jobbdefinitionen på en mer detaljerad nivå än. Länkar till övervakningssidan, status, varaktighet och tidigare Spark-jobbdefinitionskörningar är till exempel inte tillgängliga direkt i Data Factory. Du kan dock se mer detaljerad information på övervakningssidan för Spark-jobbdefinition.
Spara, kör eller schemalägg pipelinen
När du har konfigurerat andra aktiviteter som krävs för pipelinen växlar du till fliken Start överst i pipelineredigeraren och väljer knappen Spara för att spara pipelinen. Välj Kör för att köra den direkt eller Schemalägg för att schemalägga den. Du kan också visa körningshistoriken här eller konfigurera andra inställningar.
