Snabb kopiering i Dataflöden Gen2
Den här artikeln beskriver funktionen för snabb kopiering i Dataflöden Gen2 för Data Factory i Microsoft Fabric. Dataflöden hjälper dig att mata in och transformera data. Med introduktionen av utskalning av dataflöden med SQL DW-beräkning kan du transformera dina data i stor skala. Dina data måste dock matas in först. Med introduktionen av snabb kopiering kan du mata in terabyte data med den enkla upplevelsen av dataflöden, men med den skalbara serverdelen av pipelinens kopieringsaktivitet.
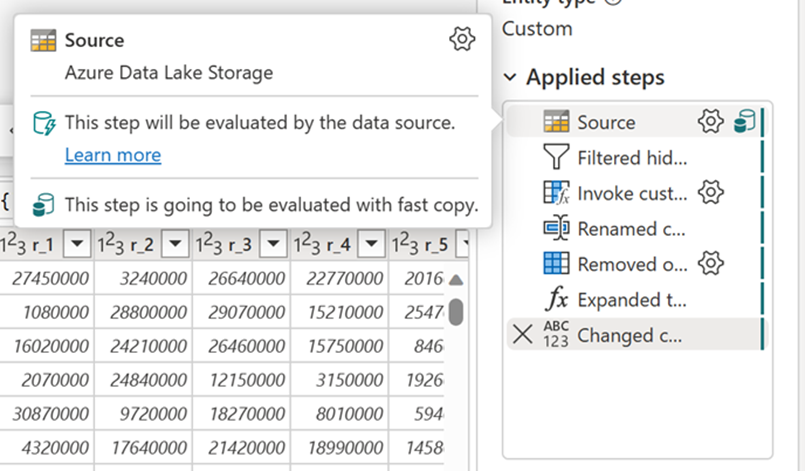
När du har aktiverat den här funktionen växlar Dataflöden automatiskt serverdelen när datastorleken överskrider ett visst tröskelvärde, utan att behöva ändra något under redigeringen av dataflödena. Efter uppdateringen av ett dataflöde kan du checka in uppdateringshistoriken för att se om snabb kopiering användes under körningen genom att titta på motortypen som visas där.
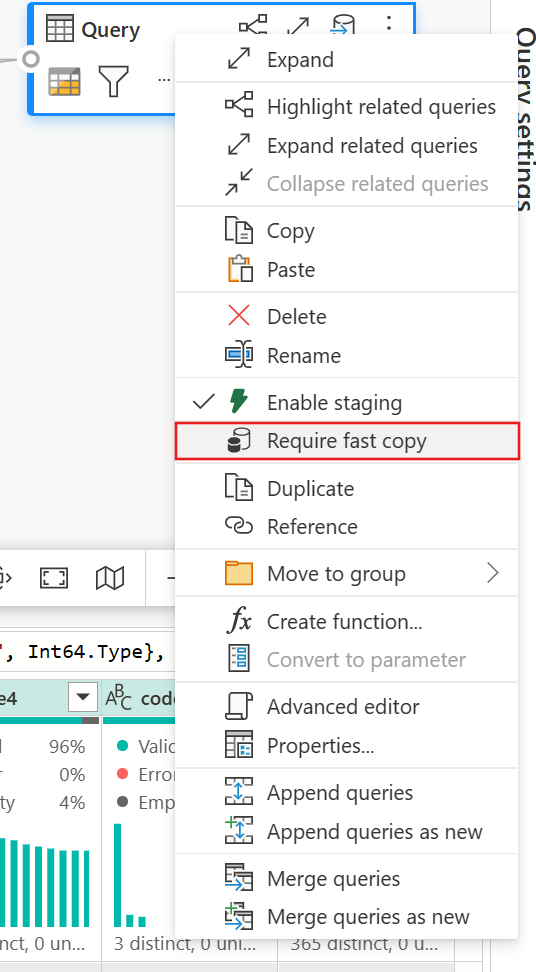
Med alternativet Kräv snabb kopiering aktiverat avbryts dataflödesuppdateringen om snabb kopiering inte används. Detta hjälper dig att undvika att vänta på att tidsgränsen för uppdateringen ska fortsätta. Det här beteendet kan också vara användbart i en felsökningssession för att testa dataflödesbeteendet med dina data samtidigt som väntetiden minskar. Med hjälp av snabbkopieringsindikatorerna i frågestegsfönstret kan du enkelt kontrollera om frågan kan köras med snabb kopiering.
Förutsättningar
- Du måste ha en infrastrukturkapacitet.
- För fildata är filerna i .csv eller parquet-format på minst 100 MB och lagras i ett Azure Data Lake Storage (ADLS) Gen2 eller ett Blob Storage-konto.
- För databas inklusive Azure SQL DB och PostgreSQL, 5 miljoner rader eller mer data i datakällan.
Kommentar
Du kan kringgå tröskelvärdet för att framtvinga snabb kopiering genom att välja inställningen "Kräv snabb kopiering".
Stöd för anslutningsprogram
Snabb kopiering stöds för närvarande för följande Dataflow Gen2-anslutningsappar:
- ADLS Gen2
- Blobb-lagring
- Azure SQL-databas
- Sjöhus
- PostgreSQL
- Lokal SQL Server
- Distributionslager
- Oracle
- Snowflake
Kopieringsaktiviteten stöder bara några transformeringar när du ansluter till en filkälla:
- Kombinera filer
- Välj kolumner
- Ändra datatyper
- Byt namn på en kolumn
- Ta bort en kolumn
Du kan fortfarande använda andra transformeringar genom att dela upp inmatnings- och transformeringsstegen i separata frågor. Den första frågan hämtar faktiskt data och den andra frågan refererar till dess resultat så att DW-beräkning kan användas. För SQL-källor stöds alla transformeringar som ingår i den interna frågan.
När du läser in frågan direkt till ett utdatamål stöds för närvarande endast Lakehouse-mål. Om du vill använda ett annat utdatamål kan du mellanlagra frågan först och referera till den senare.
Så här använder du snabbkopiering
Navigera till lämplig fabric-slutpunkt.
Navigera till en Premium-arbetsyta och skapa ett dataflöde Gen2.
På fliken Start i det nya dataflödet väljer du Alternativ:
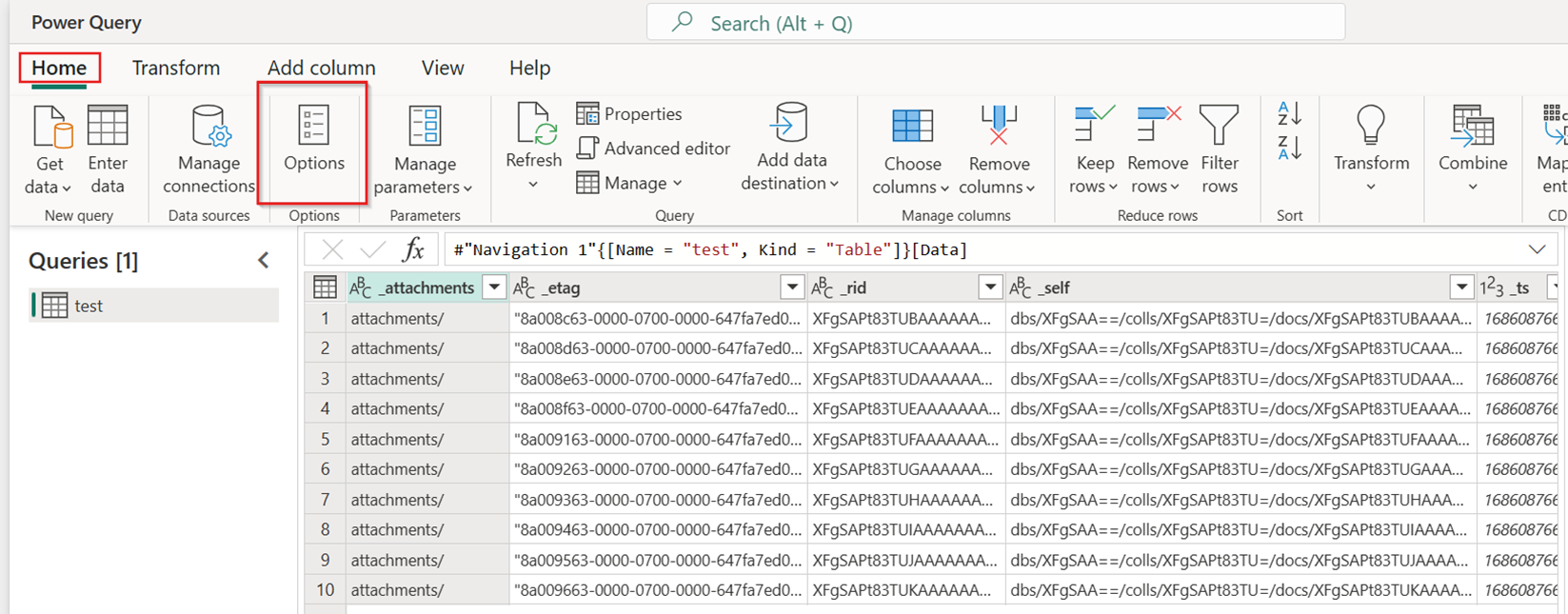
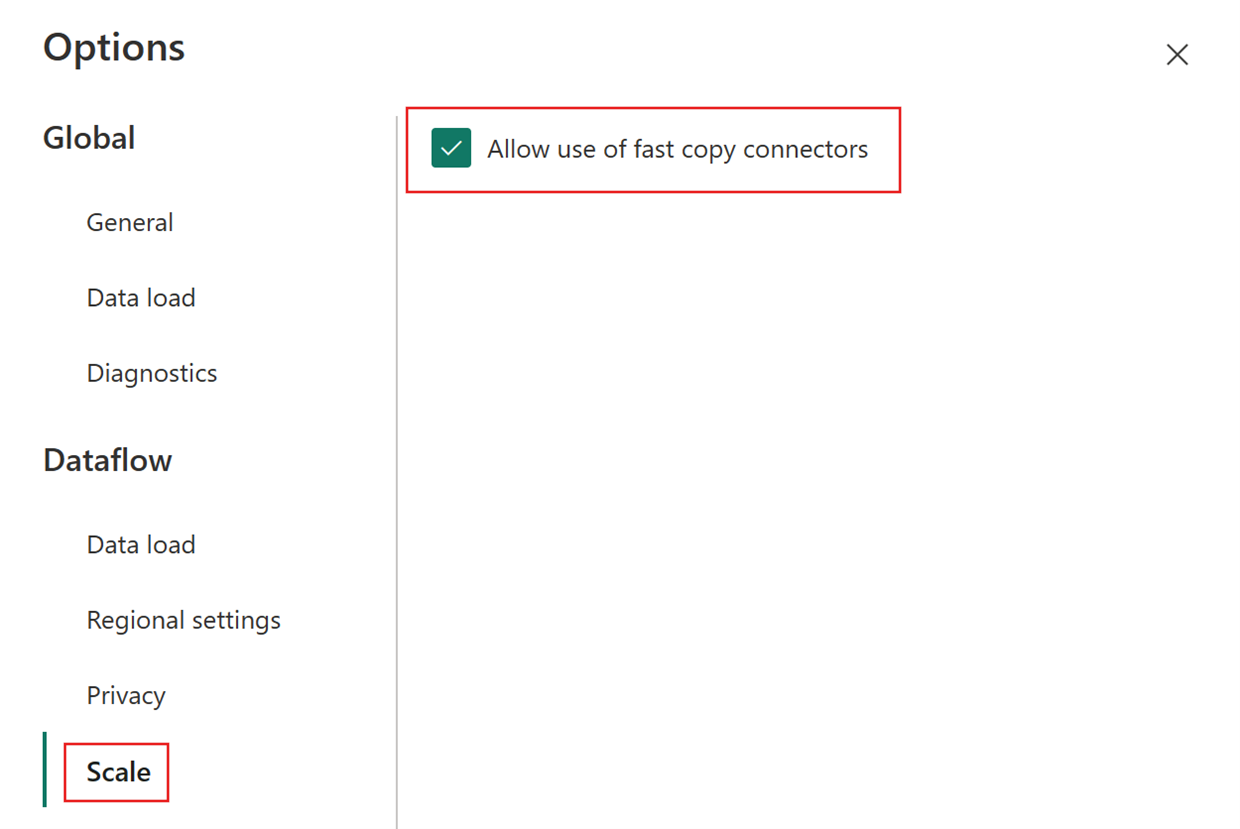
Välj sedan fliken Skala i dialogrutan Alternativ och markera kryssrutan Tillåt användning av snabbkopiering av anslutningsappar för att aktivera snabb kopiering. Stäng sedan dialogrutan Alternativ.
Välj Hämta data och välj sedan ADLS Gen2-källan och fyll i informationen för containern.
Använd funktionen Kombinera fil.
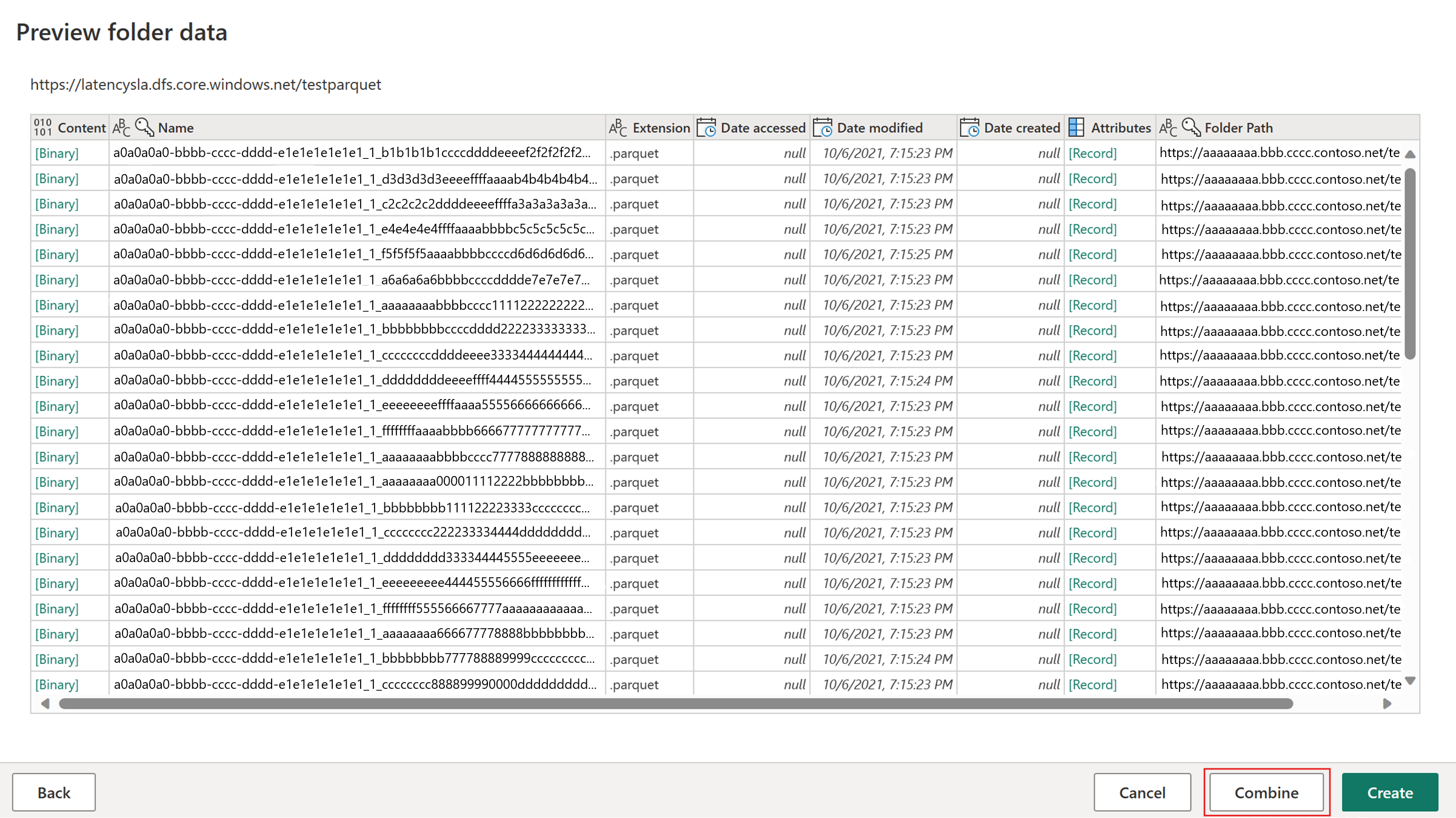
Om du vill säkerställa snabb kopiering använder du endast transformeringar som anges i avsnittet Anslutningsappsstöd i den här artikeln. Om du behöver tillämpa fler transformeringar mellanlagrar du data först och refererar till frågan senare. Gör andra transformeringar i den refererade frågan.
(Valfritt) Du kan ange alternativet Kräv snabb kopiering för frågan genom att högerklicka på den för att välja och aktivera det alternativet.
(Valfritt) För närvarande kan du bara konfigurera en Lakehouse som utdatamål. För andra mål mellanlagra du frågan och refererar till den senare i en annan fråga där du kan mata ut till valfri källa.
Kontrollera de snabba kopieringsindikatorerna för att se om frågan kan köras med snabb kopiering. I så fall visar motortypen CopyActivity.

Publicera dataflödet.
Kontrollera när uppdateringen har slutförts för att bekräfta att snabb kopiering har använts.

Så här delar du upp frågan för att utnyttja snabb kopiering
För optimala prestanda vid bearbetning av stora mängder data med Dataflöde Gen2 använder du funktionen Snabbkopia för att först mata in data i mellanlagring och transformerar dem sedan i stor skala med SQL DW-beräkning. Den här metoden förbättrar avsevärt prestanda från slutpunkt till slutpunkt.
För att implementera detta kan snabbkopieringsindikatorer hjälpa dig att dela upp frågan i två delar: datainmatning till mellanlagring och storskalig transformering med SQL DW-beräkning. Du uppmanas att förflytta så mycket av utvärderingen av en fråga som möjligt till Fast Copy som kan användas för att mata in dina data. När indikatorer för snabbkopiering indikerar att de resterande stegen inte kan köras med Snabbkopiering kan du dela upp återstående delar av frågan med mellanlagring aktiverat.
Stegdiagnostikindikatorer
| Indikator | Ikon | Beskrivning |
|---|---|---|
| Det här steget kommer att utvärderas med snabb kopiering | 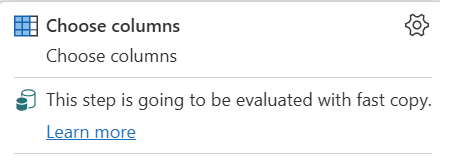
|
Indikatorn Snabbkopiering visar att frågan fram till det här steget stöder snabb kopiering. |
| Det här steget stöds inte av snabb kopiering | 
|
Indikatorn För snabbkopiering visar att det här steget inte stöder snabbkopiering. |
| Ett eller flera steg i din sökfråga stöds inte av snabb sökfråga | 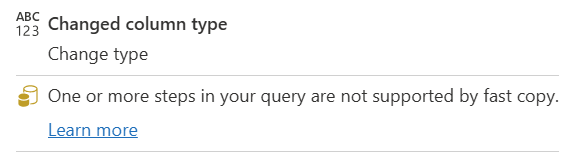
|
Indikatorn För snabbkopiering visar att vissa steg i den här frågan stöder Snabbkopiering, medan andra inte gör det. För att optimera, dela frågan: gula steg (stöds eventuellt av snabbkopiering) och röda steg (stöds inte). |
Stegvis vägledning
När du har slutfört datatransformeringslogik i Dataflow Gen2 utvärderar indikatorn för snabbkopiering varje steg för att avgöra hur många steg som kan utnyttja snabbkopiering för bättre prestanda.
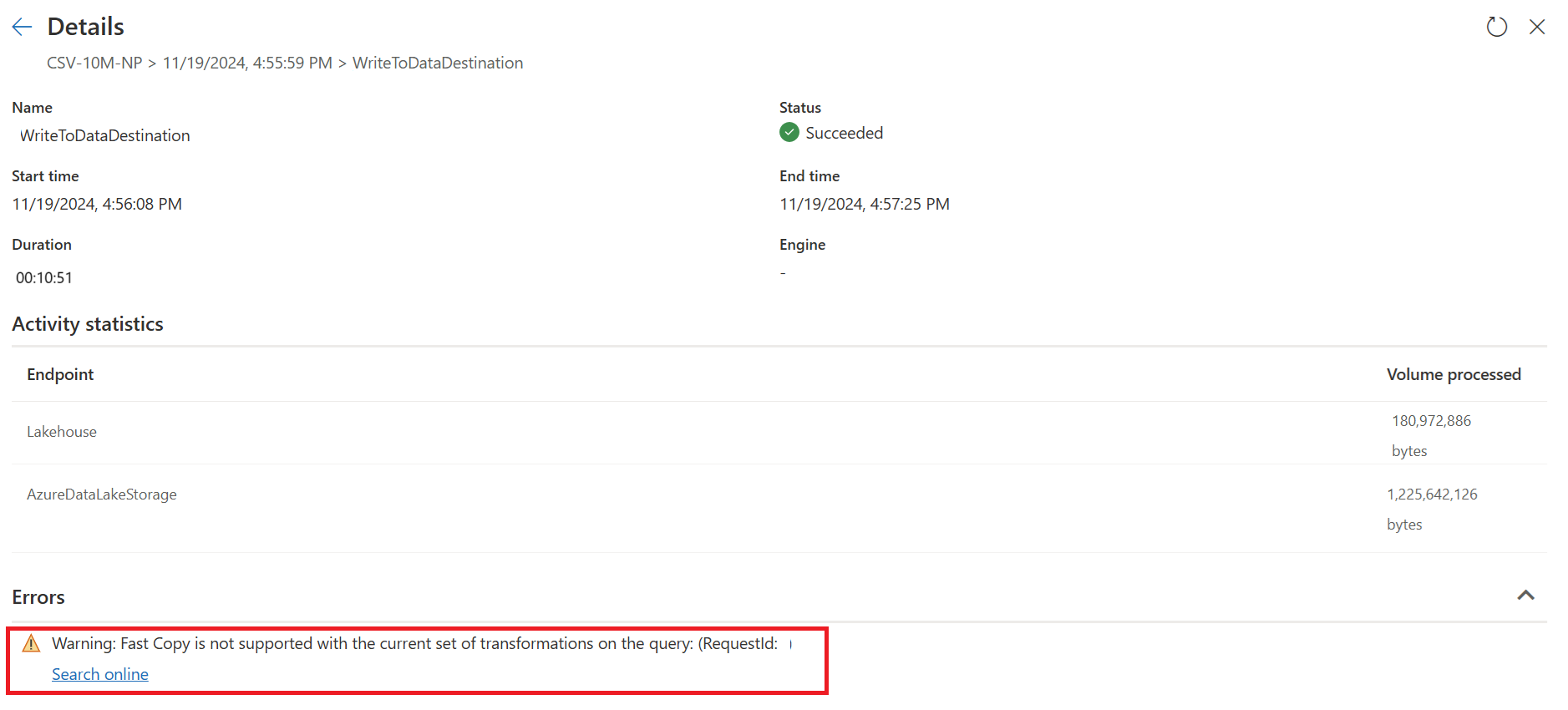
I exemplet nedan visas det sista steget rött, vilket anger att steget med Gruppera efter inte stöds av Snabbkopiering. Alla tidigare steg som visas som gula kan dock eventuellt stödjas av Snabbkopiering.
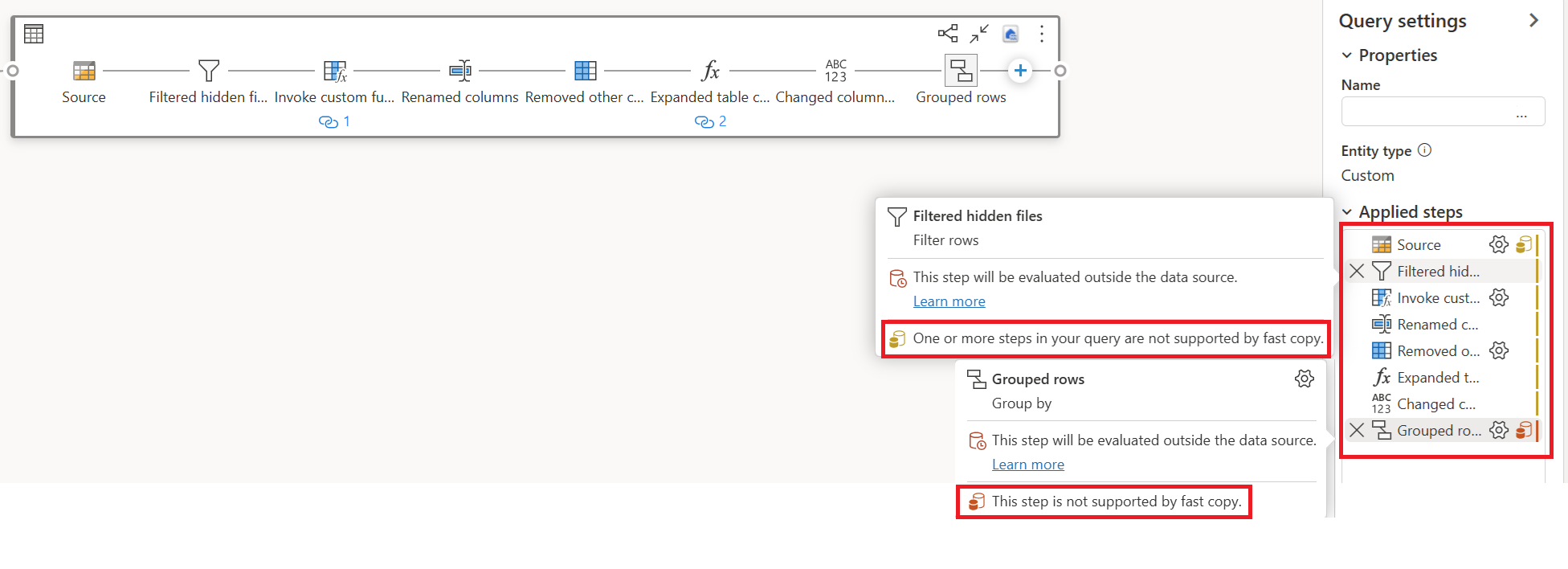
För närvarande, om du publicerar och kör dataflödet Gen2 direkt, kommer den inte att använda snabbkopieringsmotorn för att läsa in dina data som bilden nedan:
Om du vill använda motorn För snabb kopiering och förbättra prestandan för dataflödet Gen2 kan du dela upp frågan i två delar: datainmatning till mellanlagring och storskalig transformering med SQL DW-beräkning, enligt följande:
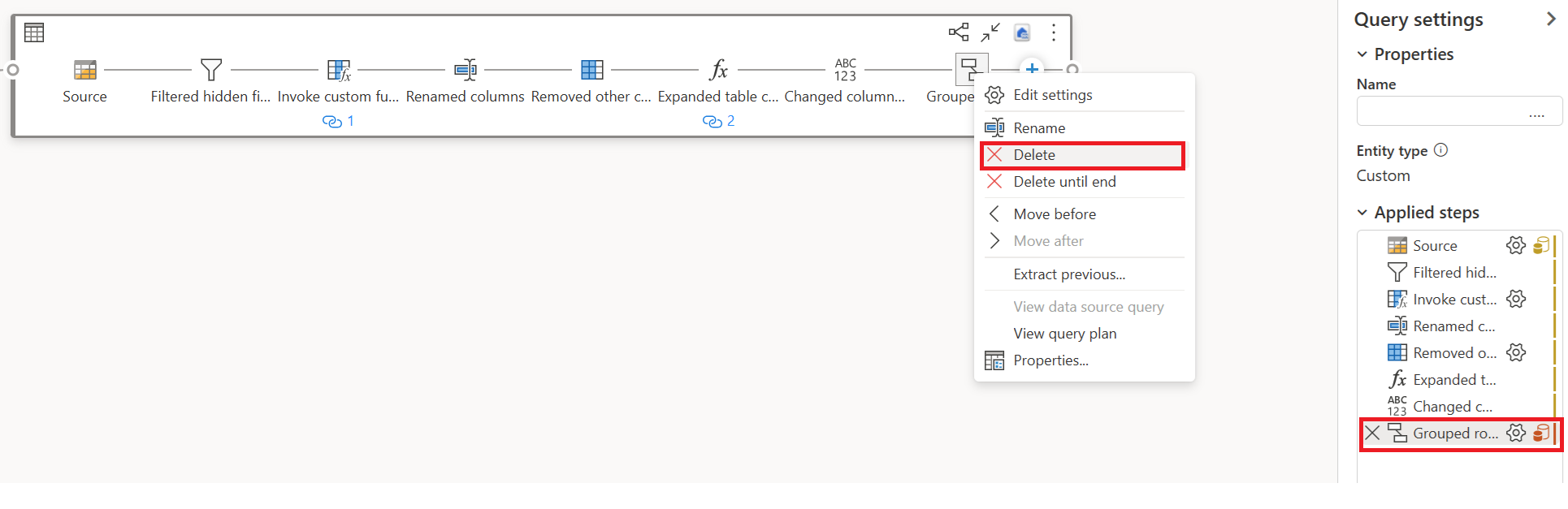
Ta bort transformeringar (som visar rött) som inte stöds av Snabbkopiering, tillsammans med målet (om det definieras).
Indikatorn för snabbkopiering visar nu grönt för de återstående stegen, vilket innebär att din första fråga kan utnyttja Snabbkopiering för bättre prestanda.
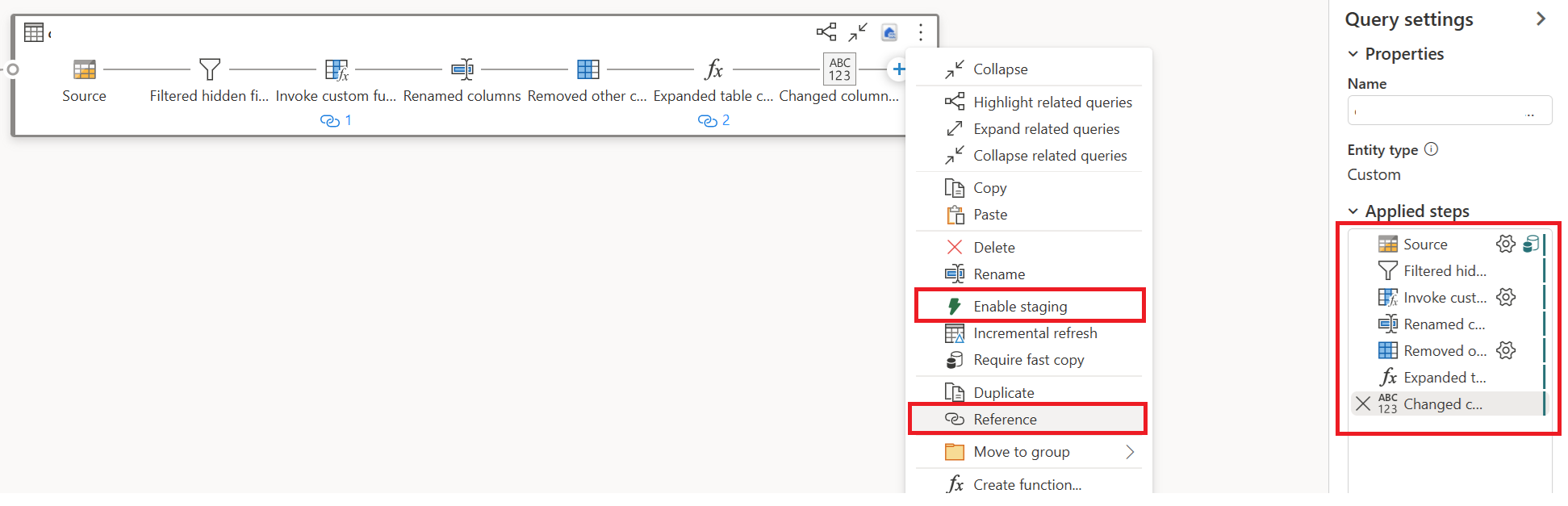
Välj Åtgärd för din första fråga och välj sedan Aktivera mellanlagring och referens.
I en ny refererad fråga läste du omvandlingen "Gruppera efter" och målet (om tillämpligt).
Publicera och uppdatera dataflödet Gen2. Nu visas två frågor i dataflödet Gen2, och den totala varaktigheten är till stor del reducerad.
Den första sökningen matar in data i mellanlagring med Snabbkopiering.
Den andra frågan utför storskaliga transformeringar med sql DW-beräkning.
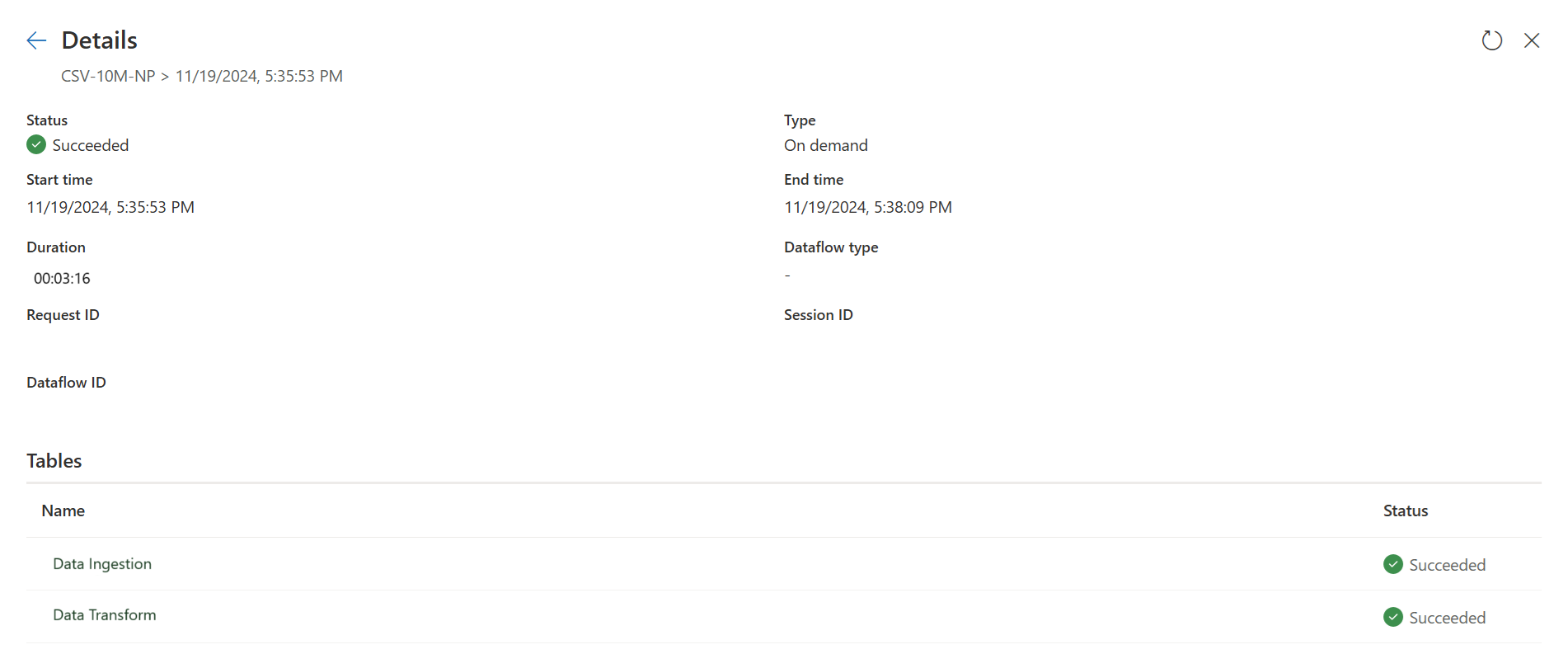
Den första frågan:
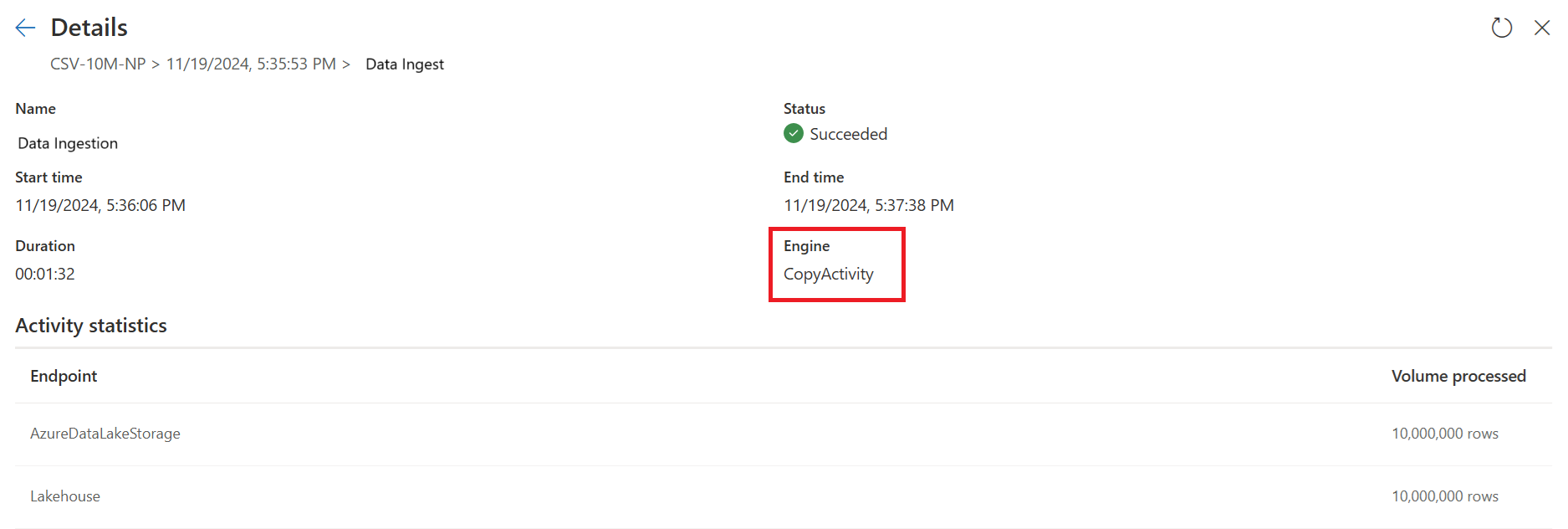
Den andra frågan:
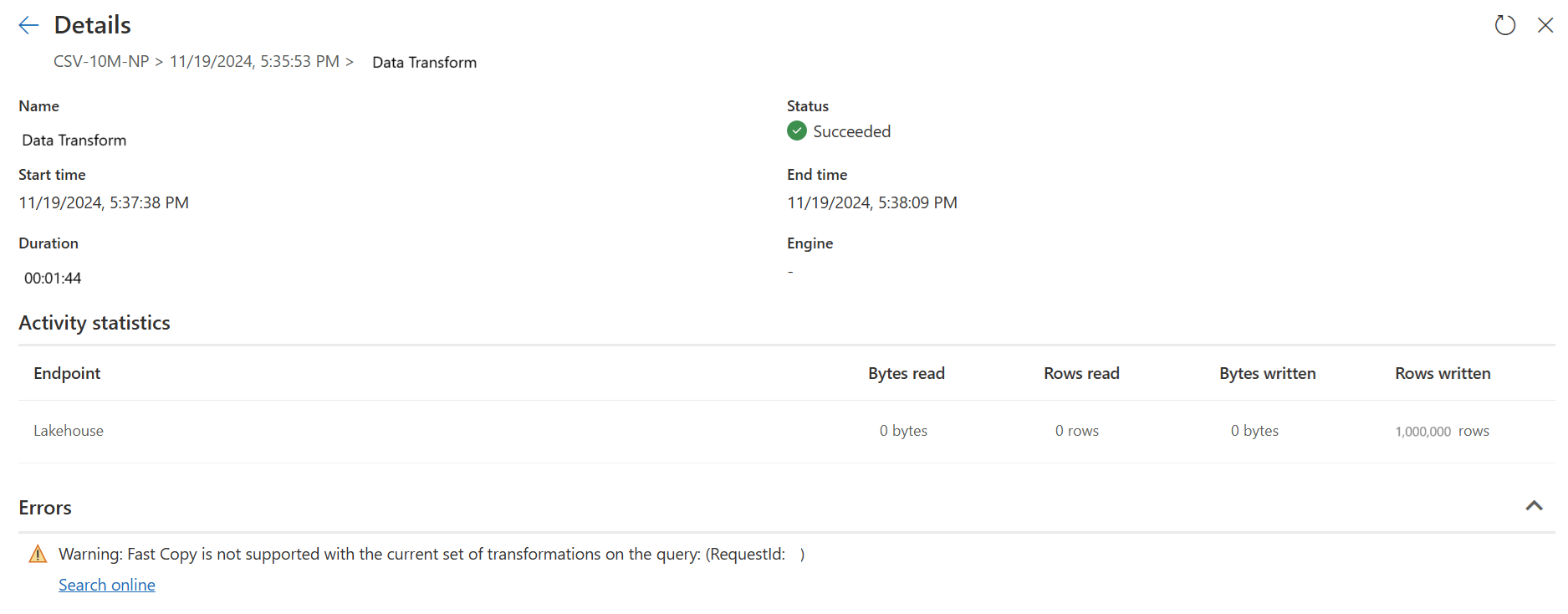
Kända begränsningar
- En lokal datagateway version 3000.214.2 eller senare krävs för att stödja Snabbkopiering.
- VNet-gatewayen stöds inte.
- Det går inte att skriva data till en befintlig tabell i Lakehouse.
- Det fasta schemat stöds inte.