Konfigurera informationslagret i en kopieringsaktivitet
Den här artikeln beskriver hur du använder kopieringsaktiviteten i datapipelinen för att kopiera data från och till ett informationslager.
Konfiguration som stöds
För konfigurationen av varje flik under kopieringsaktivitet går du till följande avsnitt.
Allmänt
För flikkonfigurationen Allmänt går du till Allmänt.
Källa
Följande egenskaper stöds för Data Warehouse som källa i en kopieringsaktivitet.
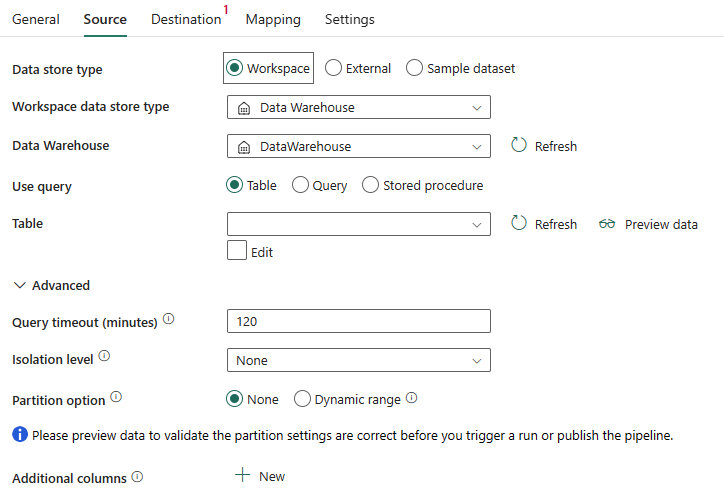
Följande egenskaper krävs:
Datalagertyp: Välj Arbetsyta.
Datalagertyp för arbetsyta: Välj Informationslager i listan över datalagertyper.
Informationslager: Välj ett befintligt informationslager från arbetsytan.
Använd fråga: Välj tabell, fråga eller lagrad procedur.
Om du väljer Tabell väljer du en befintlig tabell i tabelllistan eller anger ett tabellnamn manuellt genom att välja rutan Redigera .

Om du väljer Fråga använder du den anpassade SQL-frågeredigeraren för att skriva en SQL-fråga som hämtar källdata.

Om du väljer Lagrad procedur väljer du en befintlig lagrad procedur i listrutan eller anger ett lagrat procedurnamn som källa genom att välja rutan Redigera .

Under Avancerat kan du ange följande fält:
Tidsgräns för frågor (minuter): Tidsgräns för körning av frågekommandon med standardvärdet 120 minuter. Om den här egenskapen anges är de tillåtna värdena i formatet för ett tidsintervall, till exempel "02:00:00" (120 minuter).
Isoleringsnivå: Ange transaktionslåsningsbeteendet för SQL-källan.
Partitionsalternativ: Ange de datapartitioneringsalternativ som används för att läsa in data från Data Warehouse. Du kan välja Inget eller Dynamiskt intervall.
Om du väljer Dynamiskt intervall behövs intervallpartitionsparametern(
?AdfDynamicRangePartitionCondition) när du använder frågan med parallellaktiverad. Exempelfråga:SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.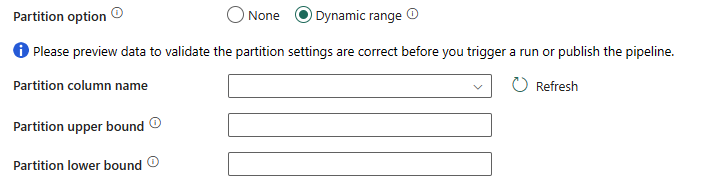
- Partitionskolumnnamn: Ange namnet på källkolumnen i heltal eller datum/datetime-typ (
int, ,smallintbigint,smalldatetimedate,datetime, ,datetime2ellerdatetimeoffset) som används av intervallpartitionering för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn. - Partitionens övre gräns: Det maximala värdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras.
- Partition med lägre gräns: Minimivärdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras.
- Partitionskolumnnamn: Ange namnet på källkolumnen i heltal eller datum/datetime-typ (
Ytterligare kolumner: Lägg till ytterligare datakolumner för att lagra källfilernas relativa sökväg eller statiska värde. Uttrycket stöds för det senare.


Mål
Följande egenskaper stöds för Data Warehouse som mål i en kopieringsaktivitet.
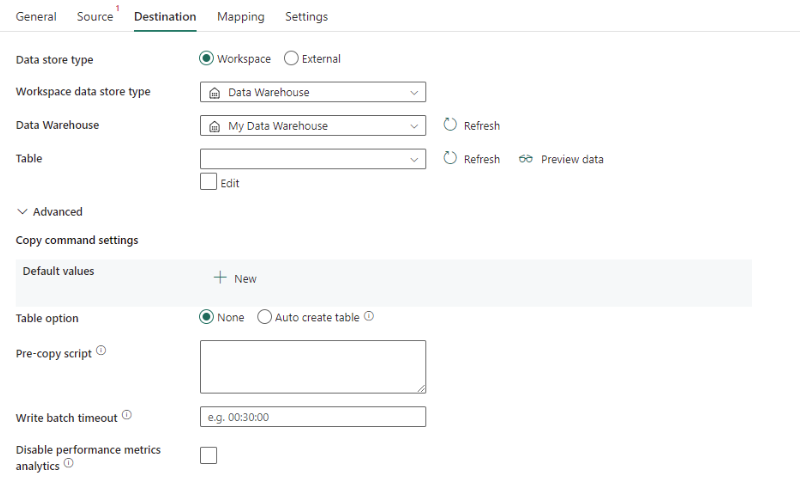
Följande egenskaper krävs:
- Datalagertyp: Välj Arbetsyta.
- Datalagertyp för arbetsyta: Välj Informationslager i listan över datalagertyper.
- Informationslager: Välj ett befintligt informationslager från arbetsytan.
- Tabell: Välj en befintlig tabell i tabelllistan eller ange ett tabellnamn som mål.
Under Avancerat kan du ange följande fält:
Inställningar för kopieringskommando: Ange egenskaper för kopieringskommando.
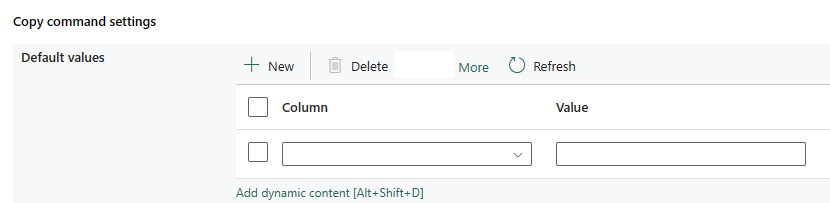
Tabellalternativ: Ange om måltabellen ska skapas automatiskt om ingen finns baserat på källschemat. Du kan välja Ingen eller Skapa tabell automatiskt.
Förkopieringsskript: Ange en SQL-fråga som ska köras innan du skriver data till Data Warehouse i varje körning. Använd den här egenskapen för att rensa inlästa data.
Tidsgräns för skrivning av batch: Väntetiden för att batchinfogningsåtgärden ska slutföras innan tidsgränsen uppnås. De tillåtna värdena är i formatet för ett tidsintervall. Standardvärdet är "00:30:00" (30 minuter).
Inaktivera prestandamåttanalys: Tjänsten samlar in mått för optimering och rekommendationer för kopieringsprestanda. Om du är intresserad av det här beteendet inaktiverar du den här funktionen.
Direktkopiering
COPY-instruktionen är det primära sättet att mata in data i lagertabeller. Kommandot COPY för Data Warehouse har direkt stöd för Azure Blob Storage och Azure Data Lake Storage Gen2 som källdatalager. Om dina källdata uppfyller de villkor som beskrivs i det här avsnittet använder du KOMMANDOT KOPIERA för att kopiera direkt från källdatalagret till Information Warehouse.
Källdata och -format innehåller följande typer och autentiseringsmetoder:
Typ av källdatalager som stöds Format som stöds Typ av källautentisering som stöds Azure Blob Storage Avgränsad text
ParquetAnonym autentisering
Kontonyckelautentisering
Signaturautentisering för delad åtkomstAzure Data Lake Storage Gen2 Avgränsad text
ParquetKontonyckelautentisering
Signaturautentisering för delad åtkomstFöljande formatinställningar kan anges:
- För Parquet: Komprimeringstypen kan vara Ingen, snabb eller gzip.
- För DelimitedText:
- Radavgränsare: När avgränsaren kopierar avgränsad text till informationslagret via kommandot kopiera direkt anger du radavgränsaren explicit (\r; \n; eller \r\n). Endast när källfilens radgränsare är \r\n fungerar standardvärdet (\r, \n eller \r\n). Annars aktiverar du mellanlagring för ditt scenario.
- Null-värdet lämnas som standard eller är inställt på tom sträng ("").
- Kodning lämnas som standard eller anges till UTF-8 eller UTF-16.
- Hoppa över radantal lämnas som standard eller anges till 0.
- Komprimeringstypen kan vara Ingen eller gzip.
Om källan är en mapp måste du markera kryssrutan Rekursivt .
Starttid (UTC) och Sluttid (UTC) i Filtrera efter senast ändrad, Prefix, Aktivera partitionsidentifiering och Ytterligare kolumner har inte angetts.
Mer information om hur du matar in data i informationslagret med hjälp av kommandot COPY finns i den här artikeln.
Om källdatalagret och formatet inte ursprungligen stöds av ett COPY-kommando använder du den mellanlagrade kopian med hjälp av kommandofunktionen KOPIERA i stället. Den konverterar automatiskt data till ett copy-kommandokompatibelt format och anropar sedan ett COPY-kommando för att läsa in data till Data Warehouse.
Mellanlagrad kopia
När dina källdata inte är internt kompatibla med COPY-kommandot aktiverar du datakopiering via en mellanlagringslagring. I det här fallet konverterar tjänsten automatiskt data för att uppfylla dataformatkraven för COPY-kommandot. Sedan anropas COPY-kommandot för att läsa in data till Data Warehouse. Slutligen rensas dina tillfälliga data från lagringen.
Om du vill använda mellanlagrad kopia går du till fliken Inställningar och väljer Aktivera mellanlagring. Du kan välja Arbetsyta för att använda automatiskt skapad mellanlagring i Infrastrukturresurser. För externt stöds Azure Blob Storage och Azure Data Lake Storage Gen2 som extern mellanlagring. Du måste först skapa en Azure Blob Storage- eller Azure Data Lake Storage Gen2-anslutning och sedan välja anslutningen i listrutan för att använda mellanlagringen.
Observera att du måste se till att IP-intervallet för informationslagret har tillåtits korrekt från mellanlagringen.
Mappning
För konfigurationen av fliken Mappning går du till Mappning om du inte tillämpar informationslagret med tabellen för automatisk skapande som mål.
Om du använder Data Warehouse med tabellen för automatisk skapande som mål, förutom konfigurationen i Mappning, kan du redigera typen för dina målkolumner. När du har valt Importera scheman kan du ange kolumntypen i målet.
Till exempel är typen för ID-kolumnen i källan int, och du kan ändra den till flyttaltyp vid mappning till målkolumnen.
Inställningar
För fliken Inställningar går du till Inställningar.
Tabellsammanfattning
Följande tabeller innehåller mer information om en kopieringsaktivitet i Data Warehouse.
Källinformation
| Name | Beskrivning | Värde | Obligatoriskt | JSON-skriptegenskap |
|---|---|---|---|---|
| Typ av datalager | Din datalagertyp. | Arbetsyta | Ja | / |
| Datalagertyp för arbetsyta | Avsnittet för att välja datalagertyp för arbetsytan. | Informationslager | Ja | type |
| Informationslager | Det informationslager som du vill använda. | <ditt informationslager> | Ja | slutpunkt artifactId |
| Använda fråga | Sättet att läsa data från Data Warehouse. | •Tabeller •Fråga • Lagrad procedur |
Nej | (under typeProperties ->source)• typeProperties: schema table • sqlReaderQuery • sqlReaderStoredProcedureName |
| Tidsgräns för frågor (minuter) | Tidsgräns för körning av frågekommandon med standardvärdet 120 minuter. Om den här egenskapen anges är de tillåtna värdena i formatet för ett tidsintervall, till exempel "02:00:00" (120 minuter). | tidsintervall | Nej | queryTimeout |
| Isoleringsnivå | Beteendet för transaktionslåsning för källan. | •Ingen •Ögonblicksbild |
Nej | isolationLevel |
| Partitionsalternativ | Alternativen för datapartitionering som används för att läsa in data från Data Warehouse. | •Ingen • Dynamiskt intervall |
Nej | partitionOption |
| Partitionskolumnnamn | Namnet på källkolumnen i heltal eller datum/datetime-typ (int, , bigintsmallint, date, smalldatetime, datetime, datetime2eller datetimeoffset) som används av intervallpartitionering för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn. |
<partitionskolumnnamn> | Nej | partitionColumnName |
| Partitionens övre gräns | Det maximala värdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. | <partitionens övre gräns> | Nej | partitionUpperBound |
| Partition, nedre gräns | Minimivärdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. | <partition, nedre gräns> | Nej | partitionLowerBound |
| Ytterligare kolumner | Lägg till ytterligare datakolumner för att lagra källfilernas relativa sökväg eller statiska värde. | • Namn •Värde |
Nej | additionalColumns: •Namn •värde |
Målinformation
| Name | Beskrivning | Värde | Obligatoriskt | JSON-skriptegenskap |
|---|---|---|---|---|
| Typ av datalager | Din datalagertyp. | Arbetsyta | Ja | / |
| Datalagertyp för arbetsyta | Avsnittet för att välja datalagertyp för arbetsytan. | Informationslager | Ja | type |
| Informationslager | Det informationslager som du vill använda. | <ditt informationslager> | Ja | slutpunkt artifactId |
| Tabell | Måltabellen för att skriva data. | <namn på måltabellen> | Ja | Schemat table |
| Kopiera kommandoinställningar | Egenskapsinställningarna för kopieringskommandot. Innehåller standardvärdeinställningarna. | Standardvärde: •Spalt •Värde |
Nej | copyCommandSettings: defaultValues: • columnName • defaultValue |
| Tabellalternativ | Om måltabellen ska skapas automatiskt om ingen finns baserat på källschemat. | •Ingen • Skapa tabell automatiskt |
Nej | tableOption: • Skapa automatiskt |
| Förkopieringsskript | En SQL-fråga som ska köras innan du skriver data till Data Warehouse i varje körning. Använd den här egenskapen för att rensa inlästa data. | <förkopieringsskript> | Nej | preCopyScript |
| Tidsgräns för skrivning av batch | Väntetiden för att batchinfogningsåtgärden ska slutföras innan tidsgränsen uppnås. De tillåtna värdena är i formatet för ett tidsintervall. Standardvärdet är "00:30:00" (30 minuter). | tidsintervall | Nej | writeBatchTimeout |
| Inaktivera analys av prestandamått | Tjänsten samlar in mått för optimering och rekommendationer för kopieringsprestanda, vilket ger ytterligare åtkomst till huvuddatabasen. | markera eller avmarkera | Nej | disableMetricsCollection: sant eller falskt |