Så här konfigurerar du Amazon RDS för SQL Server i kopieringsaktivitet
Den här artikeln beskriver hur du använder kopieringsaktiviteten i en datapipeline för att kopiera data från Amazon RDS för SQL Server.
Konfiguration som stöds
För konfigurationen av varje flik under kopieringsaktivitet går du till följande avsnitt.
Allmänt
Se vägledningen allmänna inställningar för att konfigurera fliken Allmänna inställningar.
Källa
Följande egenskaper stöds för Amazon RDS för SQL Server under fliken Källa för en kopieringsaktivitet.
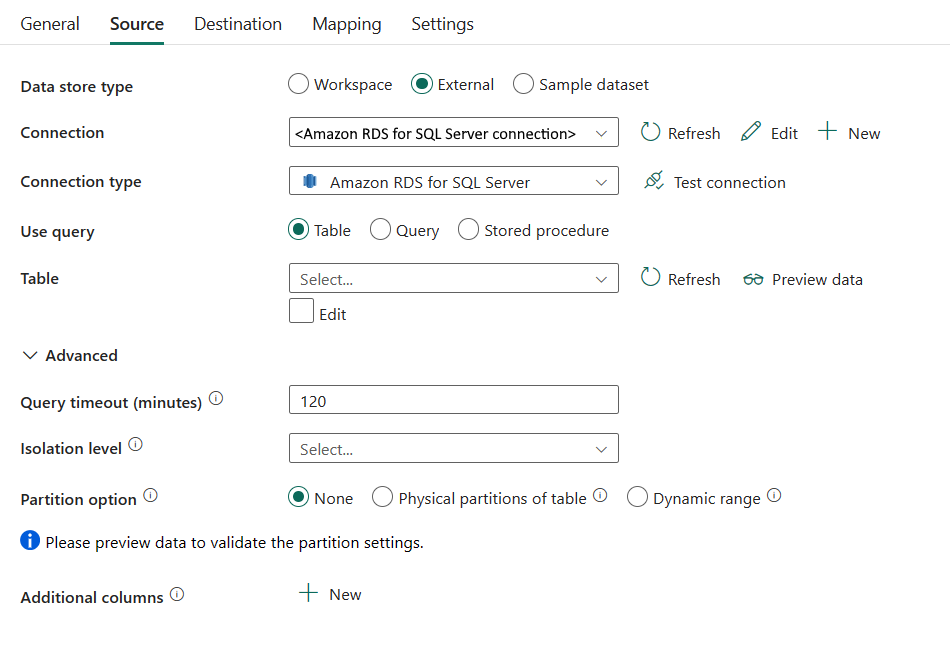
Följande egenskaper krävs:
Datalagertyp: Välj Extern.
Anslutning: Välj en Amazon RDS för SQL Server-anslutning från anslutningslistan. Om anslutningen inte finns skapar du en ny Amazon RDS för SQL Server-anslutning genom att välja Ny.
Anslutningstyp: Välj Amazon RDS för SQL Server.
Använd fråga: Ange hur data ska läsas. Du kan välja Tabell, Fråga eller Lagrad procedur. I följande lista beskrivs konfigurationen för varje inställning:
Tabell: Läsa data från den angivna tabellen. Välj källtabellen i listrutan eller välj Redigera för att ange den manuellt.
Fråga: Ange den anpassade SQL-frågan för att läsa data. Ett exempel är
select * from MyTable. Eller välj pennikonen som ska redigeras i kodredigeraren.
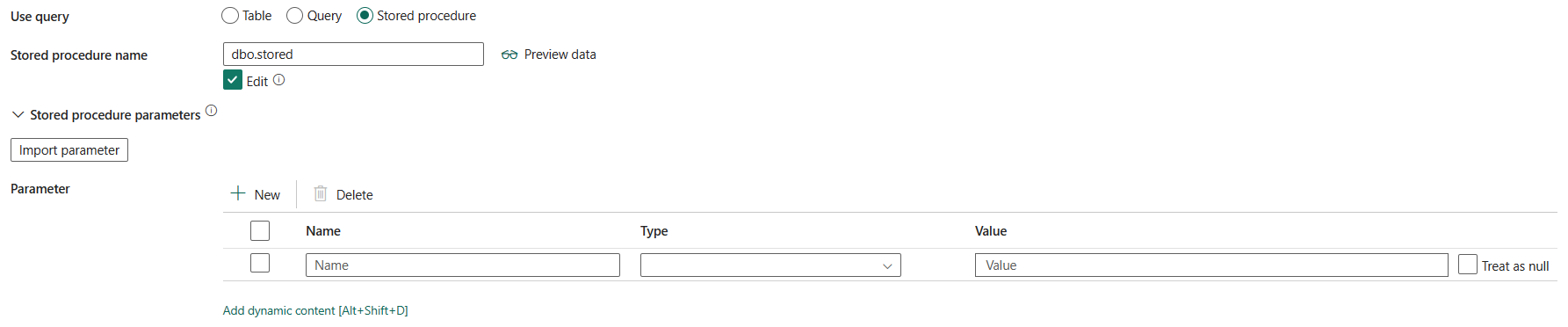
Lagrad procedur: Använd den lagrade proceduren som läser data från källtabellen. Den sista SQL-instruktionen måste vara en SELECT-instruktion i den lagrade proceduren.
Namn på lagrad procedur: Välj den lagrade proceduren eller ange namnet på den lagrade proceduren manuellt när du väljer Redigera för att läsa data från källtabellen.
Parametrar för lagrad procedur: Ange värden för parametrar för lagrad procedur. Tillåtna värden är namn- eller värdepar. Parametrarnas namn och hölje måste matcha namnen och höljet för de lagrade procedureparametrarna. Du kan välja Importera parametrar för att hämta parametrarna för lagrad procedur.
Under Avancerat kan du ange följande fält:
Tidsgräns för frågor (minuter): Ange tidsgränsen för körning av frågekommandon, standardvärdet är 120 minuter. Om en parameter anges för den här egenskapen är tillåtna värden tidsintervall, till exempel "02:00:00" (120 minuter).
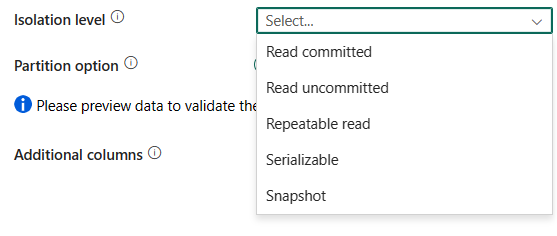
Isoleringsnivå: Anger transaktionslåsningsbeteendet för SQL-källan. De tillåtna värdena är: Read committed, Read uncommitted, Repeatable read, Serializable, Snapshot. Om den inte anges används databasens standardisoleringsnivå. Mer information finns i IsolationLevel Enum.
Partitionsalternativ: Ange de datapartitioneringsalternativ som används för att läsa in data från Amazon RDS för SQL Server. Tillåtna värden är: Ingen (standard), Fysiska partitioner av tabellen och Dynamiskt intervall. När ett partitionsalternativ är aktiverat (dvs. inte Ingen) styrs graden av parallellitet för samtidig inläsning av data från Amazon RDS för SQL Server av grad av kopieringsparallellitet på fliken inställningar för kopieringsaktivitet.
Ingen: Välj den här inställningen om du inte vill använda en partition.
Fysiska partitioner i tabellen: När du använder en fysisk partition bestäms partitionskolumnen och mekanismen automatiskt baserat på din fysiska tabelldefinition.
Dynamiskt intervall: När du använder en fråga med parallellaktiverad krävs intervallpartitionsparametern(
?DfDynamicRangePartitionCondition). Exempelfråga:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Partitionskolumnnamn: Ange namnet på källkolumnen i heltal eller datum/datetime-typ (
int, ,smallintbigint,smalldatetimedate,datetime, ,datetime2ellerdatetimeoffset) som används av intervallpartitionering för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn.Om du använder en fråga för att hämta källdata kopplar
?DfDynamicRangePartitionConditiondu in WHERE-satsen. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas .Partitionens övre gräns: Ange det maximala värdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas .
Partition med lägre gräns: Ange minimivärdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Ett exempel finns i avsnittet Parallellkopiering från SQL-databas .
Ytterligare kolumner: Lägg till ytterligare datakolumner för att lagra källfilernas relativa sökväg eller statiska värde. Uttrycket stöds för det senare.
Observera följande:
- Om Frågan har angetts för källan kör kopieringsaktiviteten den här frågan mot Amazon RDS för SQL Server-källan för att hämta data. Du kan också ange en lagrad procedur genom att ange parametrarna För lagrad procedur och Parametrar för lagrad procedur om den lagrade proceduren tar parametrar.
- När du använder lagrad procedur i källan för att hämta data bör du tänka på att om den lagrade proceduren är utformad som att returnera ett annat schema när ett annat parametervärde skickas in, kan det uppstå ett fel eller ett oväntat resultat när du importerar schemat från användargränssnittet eller när du kopierar data till SQL Database med automatisk tabellskapande.
Mappning
För Konfiguration av fliken Mappning går du till Konfigurera dina mappningar under mappningsfliken.
Inställningar
För Inställningsflikskonfiguration går du till Konfigurera dina andra inställningar under fliken Inställningar.
Parallellkopiering från SQL-databas
Amazon RDS för SQL Server-anslutningsprogrammet i kopieringsaktivitet ger inbyggd datapartitionering för att kopiera data parallellt. Du hittar alternativ för datapartitionering på fliken Källa i kopieringsaktiviteten.
När du aktiverar partitionerad kopiering kör kopieringsaktiviteten parallella frågor mot din Amazon RDS för SQL Server-källan för att läsa in data efter partitioner. Parallellgraden styrs av grad av kopieringsparallellitet på fliken inställningar för kopieringsaktivitet. Om du till exempel anger Grad av kopieringsparallellitet till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på det angivna partitionsalternativet och inställningarna, och varje fråga hämtar en del av data från Amazon RDS för SQL Server.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från Amazon RDS för SQL Server. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager rekommenderar vi att du skriver till en mapp som flera filer (anger endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenario | Föreslagna inställningar |
|---|---|
| Full belastning från en stor tabell med fysiska partitioner. | Partitionsalternativ: Fysiska partitioner i tabellen. Under körningen identifierar tjänsten automatiskt de fysiska partitionerna och kopierar data efter partitioner. Om du vill kontrollera om tabellen har fysisk partition eller inte kan du läsa den här frågan. |
| Fullständig belastning från en stor tabell, utan fysiska partitioner, med ett heltal eller en datetime-kolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Partitionskolumn (valfritt): Ange den kolumn som används för att partitionera data. Om den inte anges används primärnyckelkolumnen. Partitionens övre gräns och partitionens nedre gräns (valfritt): Ange om du vill fastställa partitionssteget. Detta är inte för att filtrera raderna i tabellen, alla rader i tabellen partitioneras och kopieras. Om det inte anges identifierar kopieringsaktiviteten automatiskt värdena och det kan ta lång tid beroende på MIN- och MAX-värden. Vi rekommenderar att du anger övre och nedre gräns. Om partitionskolumnen "ID" till exempel har värden mellan 1 och 100 och du anger den nedre gränsen som 20 och den övre gränsen som 80, med parallell kopia som 4, hämtar tjänsten data med 4 partitioner – ID:n i intervallet <=20, [21, 50], [51, 80] >respektive =81. |
| Läs in en stor mängd data med hjälp av en anpassad fråga, utan fysiska partitioner, med ett heltal eller en date/datetime-kolumn för datapartitionering. | Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att partitionera data. Partitionens övre gräns och partitionens nedre gräns (valfritt): Ange om du vill fastställa partitionssteget. Detta är inte för att filtrera raderna i tabellen, alla rader i frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. Om partitionskolumnen "ID" till exempel har värden mellan 1 och 100 och du anger den nedre gränsen som 20 och den övre gränsen som 80, med parallell kopia som 4, hämtar tjänsten data med 4 partitioner – ID:n i intervallet <=20, [21, 50], [51, 80] >respektive =81. Här är fler exempelfrågor för olika scenarier: • Fråga hela tabellen: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Fråga från en tabell med kolumnval och ytterligare where-clause-filter: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Fråga med underfrågor: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Fråga med partition i underfrågor: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Metodtips för att läsa in data med partitionsalternativet:
- Välj distinkt kolumn som partitionskolumn (till exempel primärnyckel eller unik nyckel) för att undvika datasnedvridning.
- Om tabellen har inbyggd partition använder du partitionsalternativet Fysiska partitioner i tabellen för att få bättre prestanda.
Exempelfråga för att kontrollera fysisk partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Om tabellen har en fysisk partition ser du "HasPartition" som "ja" som följande.

Tabellsammanfattning
Se följande tabell för sammanfattningen och mer information om Amazon RDS för SQL Server-kopieringsaktivitet.
Källinformation
| Name | Beskrivning | Värde | Obligatoriskt | JSON-skriptegenskap |
|---|---|---|---|---|
| Typ av datalager | Din datalagertyp. | Externt | Ja | / |
| Anslutning | Din anslutning till källdatalagret. | < din anslutning > | Ja | anslutning |
| Anslutningstyp | Din anslutningstyp. Välj Amazon RDS för SQL Server. | Amazon RDS för SQL Server | Ja | / |
| Använda fråga | Den anpassade SQL-frågan för att läsa data. | •Bord •Fråga • Lagrad procedur |
Ja | / |
| Tabell | Källdatatabellen. | < namn på måltabellen> | Nej | Schemat table |
| Fråga | Den anpassade SQL-frågan för att läsa data. | < din fråga > | Nej | sqlReaderQuery |
| Namn på lagrad procedur | Den här egenskapen är namnet på den lagrade proceduren som läser data från källtabellen. Den sista SQL-instruktionen måste vara en SELECT-instruktion i den lagrade proceduren. | < namn på lagrad procedur > | Nej | sqlReaderStoredProcedureName |
| Parameter för lagrad procedur | Dessa parametrar är för den lagrade proceduren. Tillåtna värden är namn- eller värdepar. Parametrarnas namn och hölje måste matcha namnen och höljet för de lagrade procedureparametrarna. | < namn- eller värdepar > | Nej | storedProcedureParameters |
| Tidsgräns för frågor | Tidsgränsen för körning av frågekommandon. | tidsintervall (standardvärdet är 120 minuter) |
Nej | queryTimeout |
| Isoleringsnivå | Anger transaktionslåsningsbeteendet för SQL-källan. | • Läs bekräftad • Läs obekräftade • Repeterbar läsning •Serialiseras •Ögonblicksbild |
Nej | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead •Serialiseras •Ögonblicksbild |
| Partitionsalternativ | Alternativen för datapartitionering som används för att läsa in data från Amazon RDS för SQL Server. | • Ingen (standard) • Fysiska partitioner av tabellen • Dynamiskt intervall |
Nej | partitionOption: • Ingen (standard) • PhysicalPartitionsOfTable • DynamicRange |
| Partitionskolumnnamn | Namnet på källkolumnen i heltal eller datum/datetime-typ (int, , bigintsmallint, date, smalldatetime, datetime, datetime2eller datetimeoffset) som används av intervallpartitionering för parallell kopiering. Om det inte anges identifieras indexet eller den primära nyckeln i tabellen automatiskt och används som partitionskolumn. Om du använder en fråga för att hämta källdata kopplar ?DfDynamicRangePartitionCondition du in WHERE-satsen. |
< dina partitionskolumnnamn > | Nej | partitionColumnName |
| Partitionens övre gräns | Det maximala värdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. | < partitionens övre gräns > | Nej | partitionUpperBound |
| Partition, nedre gräns | Minimivärdet för partitionskolumnen för partitionsintervalldelning. Det här värdet används för att bestämma partitionssteget, inte för att filtrera raderna i tabellen. Alla rader i tabellen eller frågeresultatet partitioneras och kopieras. Om det inte anges identifierar kopieringsaktivitet automatiskt värdet. | < partitionens nedre gräns > | Nej | partitionLowerBound |
| Ytterligare kolumner | Lägg till ytterligare datakolumner för att lagra källfilernas relativa sökväg eller statiska värde. Uttrycket stöds för det senare. | • Namn •Värde |
Nej | additionalColumns: •Namn •värde |