Transformera data genom att köra en Azure HDInsight-aktivitet
Med Azure HDInsight-aktiviteten i Data Factory för Microsoft Fabric kan du orkestrera följande Azure HDInsight-jobbtyper:
- Köra Hive-frågor
- Anropa ett MapReduce-program
- Köra Pig-frågor
- Köra ett Spark-program
- Köra ett Hadoop Stream-program
Den här artikeln innehåller en stegvis genomgång som beskriver hur du skapar en Azure HDInsight-aktivitet med hjälp av Data Factory-gränssnittet.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
- Ett klientkonto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- En arbetsyta skapas.
Lägga till en Azure HDInsight-aktivitet (HDI) i en pipeline med användargränssnittet
Skapa en ny datapipeline på din arbetsyta.
Sök efter Azure HDInsight från startskärmskortet och välj det eller välj aktiviteten i aktivitetsfältet för att lägga till den i pipelinearbetsytan.
Skapa aktiviteten från startskärmskortet:
Skapa aktiviteten från aktivitetsfältet:
Välj den nya Azure HDInsight-aktiviteten på pipelineredigerarens arbetsyta om den inte redan är markerad.
Se vägledningen allmänna inställningar för att konfigurera de alternativ som finns på fliken Allmänna inställningar .

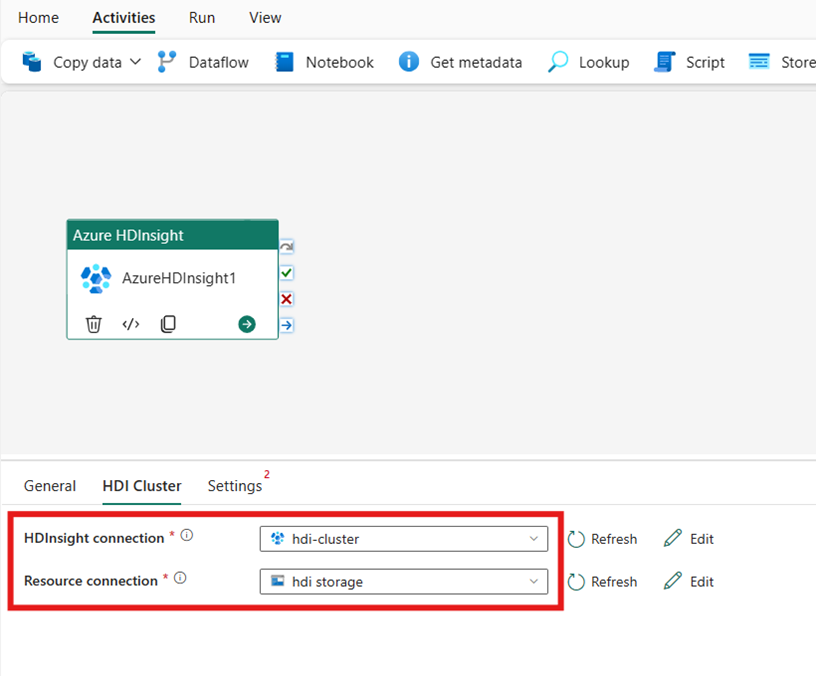
Konfigurera HDI-klustret
Välj fliken HDI-kluster . Sedan kan du välja en befintlig eller skapa en ny HDInsight-anslutning.
För resursanslutningen väljer du Azure Blob Storage som refererar till ditt Azure HDInsight-kluster. Du kan välja ett befintligt bloblager eller skapa ett nytt.
Konfigurera inställningar
Välj fliken Inställningar för att se de avancerade inställningarna för aktiviteten.
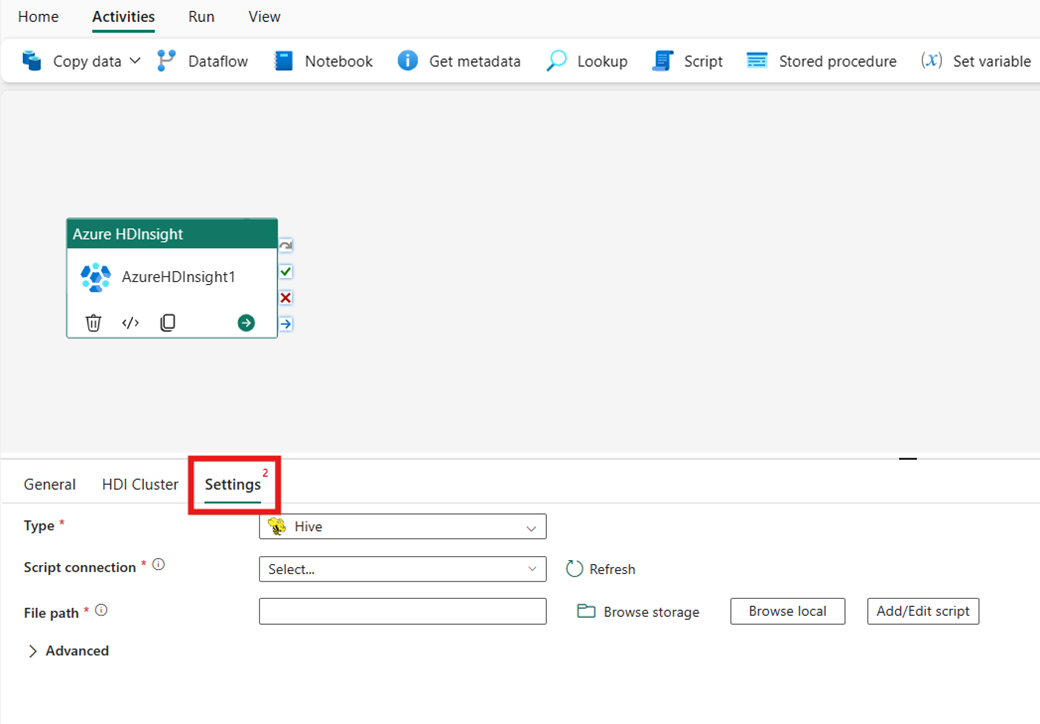
Alla avancerade klusteregenskaper och dynamiska uttryck som stöds i den länkade tjänsten Azure Data Factory och Synapse Analytics HDInsight stöds nu också i Azure HDInsight-aktiviteten för Data Factory i Microsoft Fabric, under avsnittet Avancerat i användargränssnittet. Alla dessa egenskaper har stöd för lätthanterade anpassade parameteruttryck med dynamiskt innehåll.
Klustertyp
Om du vill konfigurera inställningar för HDInsight-klustret väljer du först dess typ bland de tillgängliga alternativen, inklusive Hive, Map Reduce, Pig, Spark och Streaming.
Hive
Om du väljer Hive som Typ kör aktiviteten en Hive-fråga. Du kan också ange skriptanslutningen som refererar till ett lagringskonto som innehåller Hive-typen. Som standard används den lagringsanslutning som du angav på fliken HDI-kluster . Du måste ange den filsökväg som ska köras på Azure HDInsight. Du kan också ange fler konfigurationer i avsnittet Avancerat , Felsökningsinformation, Tidsgräns för frågor, argument, parametrar och variabler.
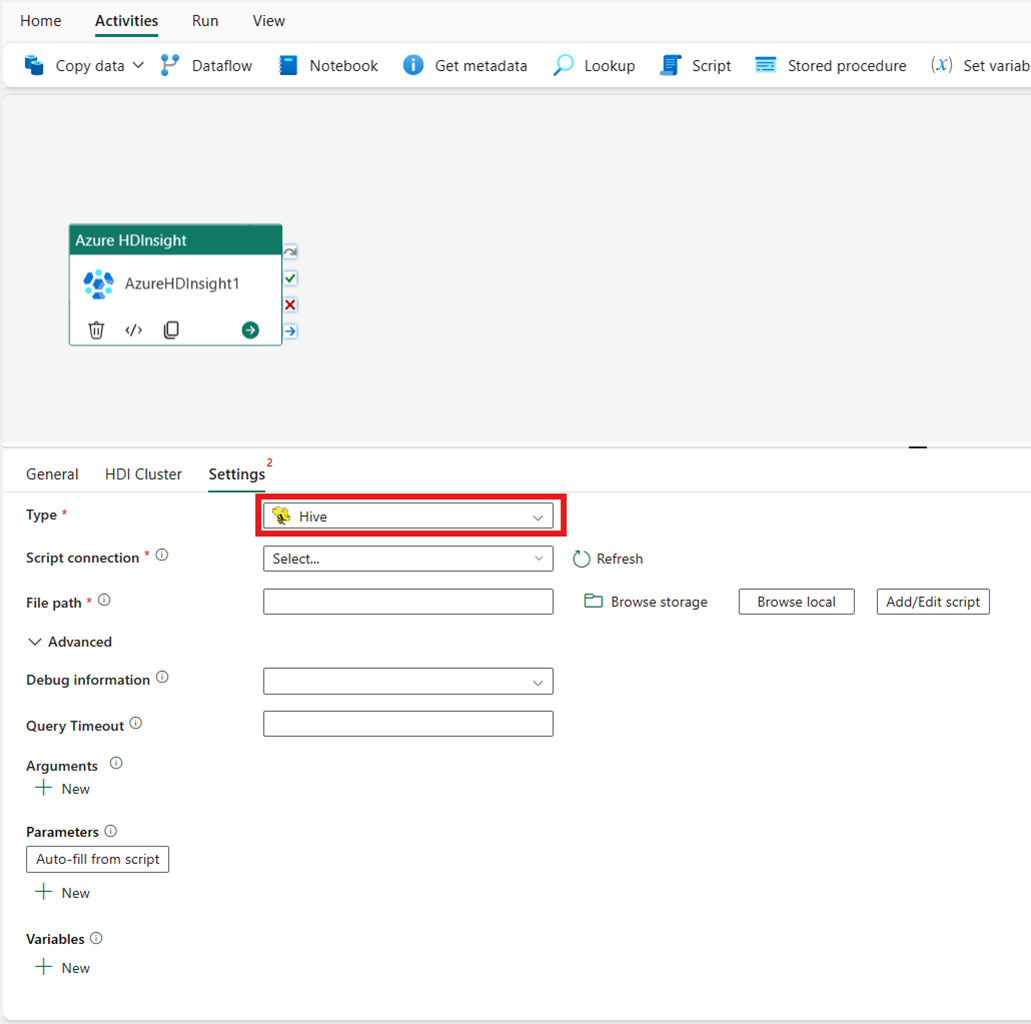
Kartreducering
Om du väljer Map Reduce för Type anropar aktiviteten ett Map Reduce-program. Du kan också ange i Jar-anslutningen som refererar till ett lagringskonto som innehåller map reduce-typen. Som standard används den lagringsanslutning som du angav på fliken HDI-kluster. Du måste ange klassnamnet och filsökvägen som ska köras i Azure HDInsight. Du kan också ange mer konfigurationsinformation, till exempel importera Jar-bibliotek, felsöka information, argument och parametrar i avsnittet Avancerat .
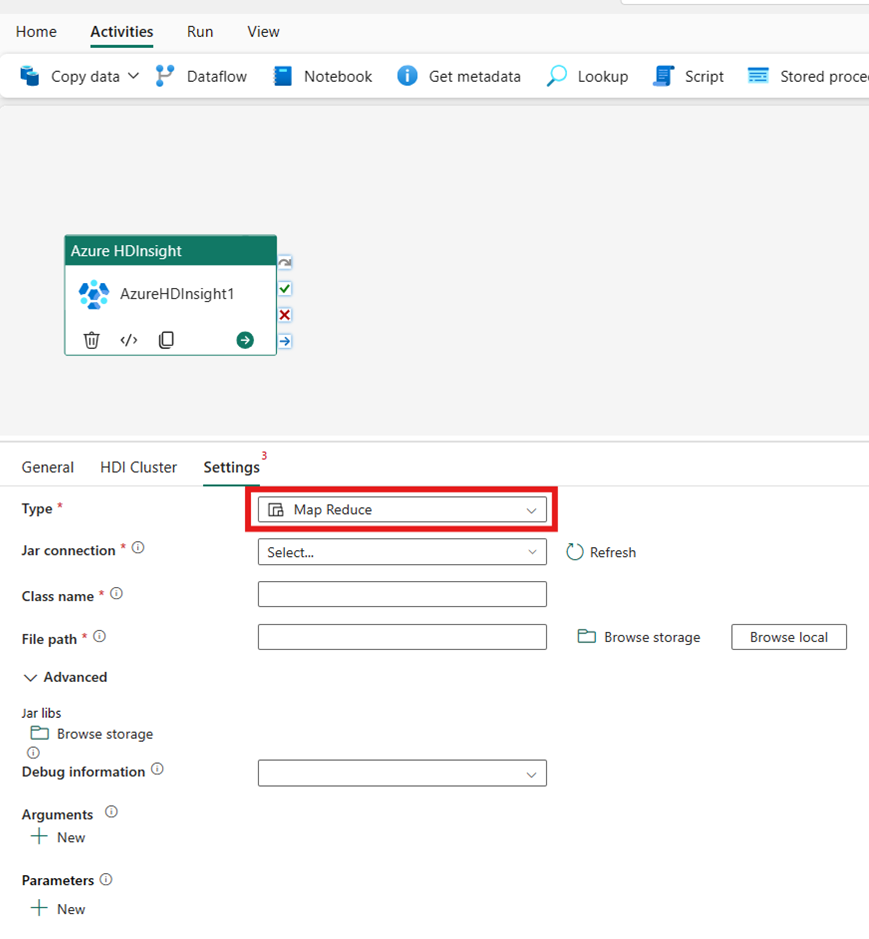
Pig
Om du väljer Pig för Type anropar aktiviteten en Pig-fråga. Du kan också ange inställningen Skriptanslutning som refererar till lagringskontot som innehåller Pig-typen. Som standard används den lagringsanslutning som du angav på fliken HDI-kluster. Du måste ange den filsökväg som ska köras på Azure HDInsight. Du kan också ange fler konfigurationer, till exempel felsökningsinformation, argument, parametrar och variabler i avsnittet Avancerat .
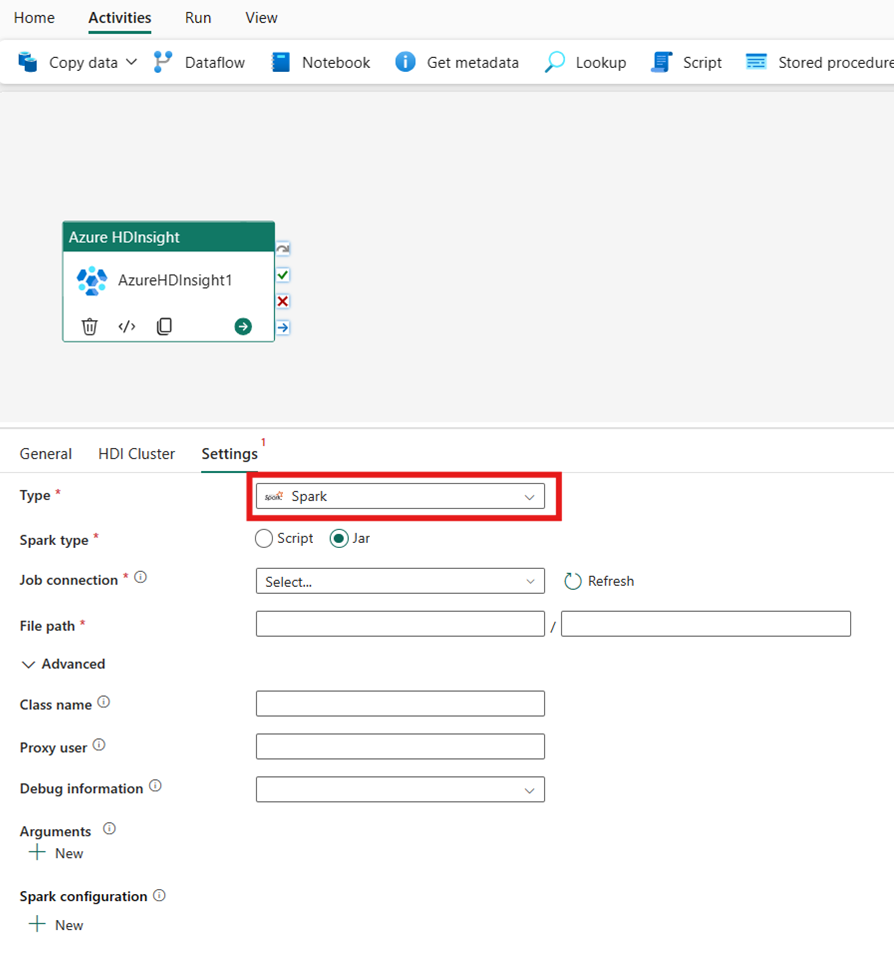
Spark
Om du väljer Spark som Typ anropar aktiviteten ett Spark-program. Välj antingen Skript eller Jar som Spark-typ. Du kan också ange jobbanslutningen som refererar till lagringskontot som innehåller Spark-typen. Som standard används den lagringsanslutning som du angav på fliken HDI-kluster. Du måste ange den filsökväg som ska köras på Azure HDInsight. Du kan också ange fler konfigurationer, till exempel klassnamn, proxyanvändare, felsökningsinformation, argument och spark-konfiguration under avsnittet Avancerat.
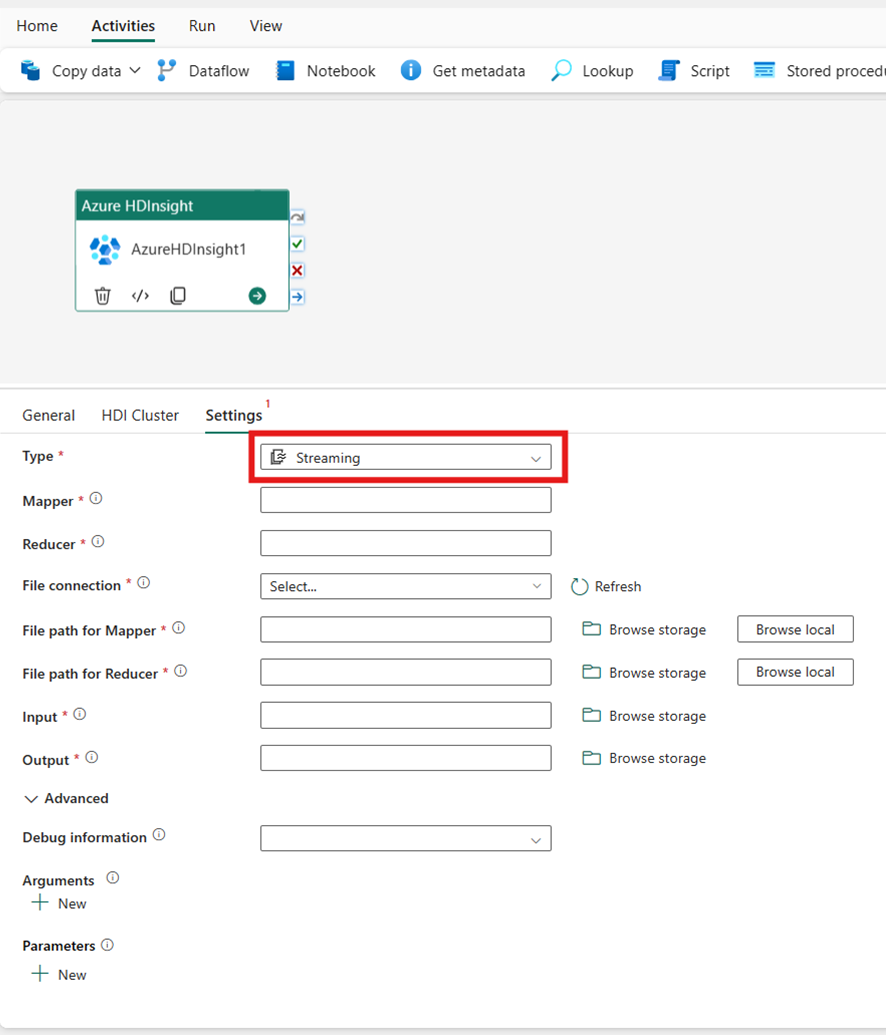
Strömning
Om du väljer Direktuppspelning för typ anropar aktiviteten ett strömningsprogram. Ange mappnings- och reducernamnen och du kan också ange filanslutningensom refererar till lagringskontot som innehåller strömningstypen. Som standard används den lagringsanslutning som du angav på fliken HDI-kluster. Du måste ange filsökvägen för Mapper och Filsökväg för att Reducer ska köras i Azure HDInsight. Inkludera alternativen indata och utdata för WASB-sökvägen. Du kan också ange fler konfigurationer, till exempel felsökningsinformation, argument och parametrar i avsnittet Avancerat.
Egenskapsreferens
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | För Hadoop Streaming Activity är aktivitetstypen HDInsightStreaming | Ja |
| Mapper | Anger namnet på den körbara mapparen | Ja |
| Reducering | Anger namnet på den körbara reducern | Ja |
| Combiner | Anger namnet på den körbara kombinationsappen | Nej |
| filanslutning | Referens till en länkad Azure Storage-tjänst som används för att lagra de Mapper-, Combiner- och Reducer-program som ska köras. | Nej |
| Endast Azure Blob Storage- och ADLS Gen2-anslutningar stöds här. Om du inte anger den här anslutningen används lagringsanslutningen som definierats i HDInsight-anslutningen. | ||
| filePath | Ange en sökvägsmatris till programmen Mapper, Combiner och Reducer som lagras i Azure Storage som refereras till av filanslutningen. | Ja |
| indata | Anger WASB-sökvägen till indatafilen för Mapper. | Ja |
| utdata | Anger WASB-sökvägen till utdatafilen för reducern. | Ja |
| getDebugInfo | Anger när loggfilerna kopieras till Azure Storage som används av HDInsight-klustret (eller) som anges av scriptLinkedService. | Nej |
| Tillåtna värden: Ingen, Alltid eller Fel. Standardvärde: Ingen. | ||
| Argument | Anger en matris med argument för ett Hadoop-jobb. Argumenten skickas som kommandoradsargument till varje uppgift. | Nej |
| Definierar | Ange parametrar som nyckel/värde-par för referens i Hive-skriptet. | Nej |
Spara och köra eller schemalägga pipelinen
När du har konfigurerat andra aktiviteter som krävs för pipelinen växlar du till fliken Start överst i pipelineredigeraren och väljer knappen Spara för att spara pipelinen. Välj Kör för att köra den direkt eller Schemalägg för att schemalägga den. Du kan också visa körningshistoriken här eller konfigurera andra inställningar.
