Transformera data genom att köra en Azure Databricks-aktivitet
Med Azure Databricks-aktiviteten i Data Factory för Microsoft Fabric kan du orkestrera följande Azure Databricks-jobb:
- Notebook-fil
- Burk
- Python
Den här artikeln innehåller en stegvis genomgång som beskriver hur du skapar en Azure Databricks-aktivitet med hjälp av Data Factory-gränssnittet.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
- Ett klientkonto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- En arbetsyta skapas.
Konfigurera en Azure Databricks-aktivitet
Utför följande steg för att använda en Azure Databricks-aktivitet i en pipeline:
Konfigurera anslutning
Skapa en ny pipeline på din arbetsyta.
Klicka på Lägg till en pipelineaktivitet och sök efter Azure Databricks.
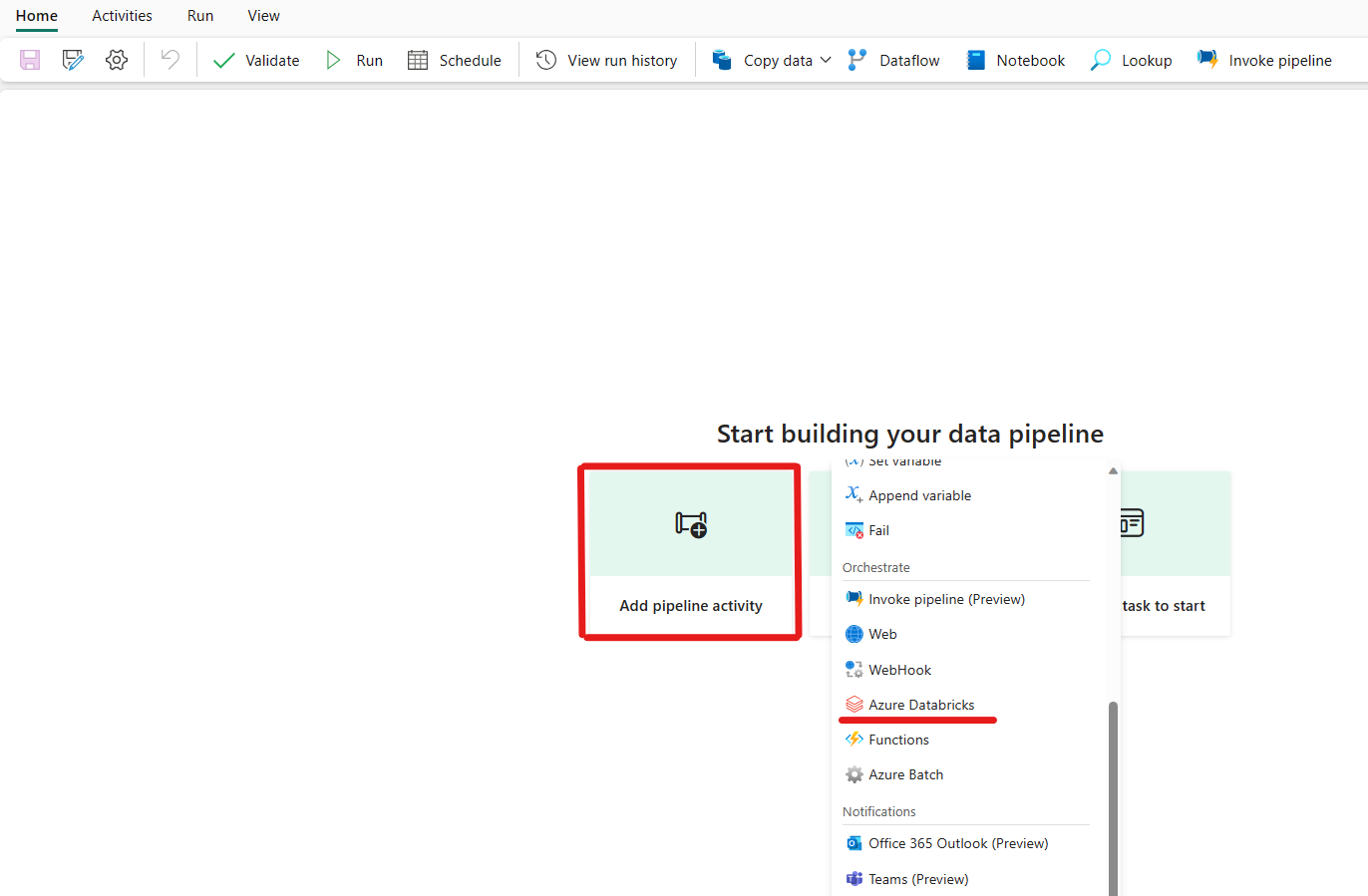
Alternativt kan du söka efter Azure Databricks i fönstret Pipelineaktiviteter och välja det för att lägga till det i pipelinearbetsytan.
Välj den nya Azure Databricks-aktiviteten på arbetsytan om den inte redan är markerad.
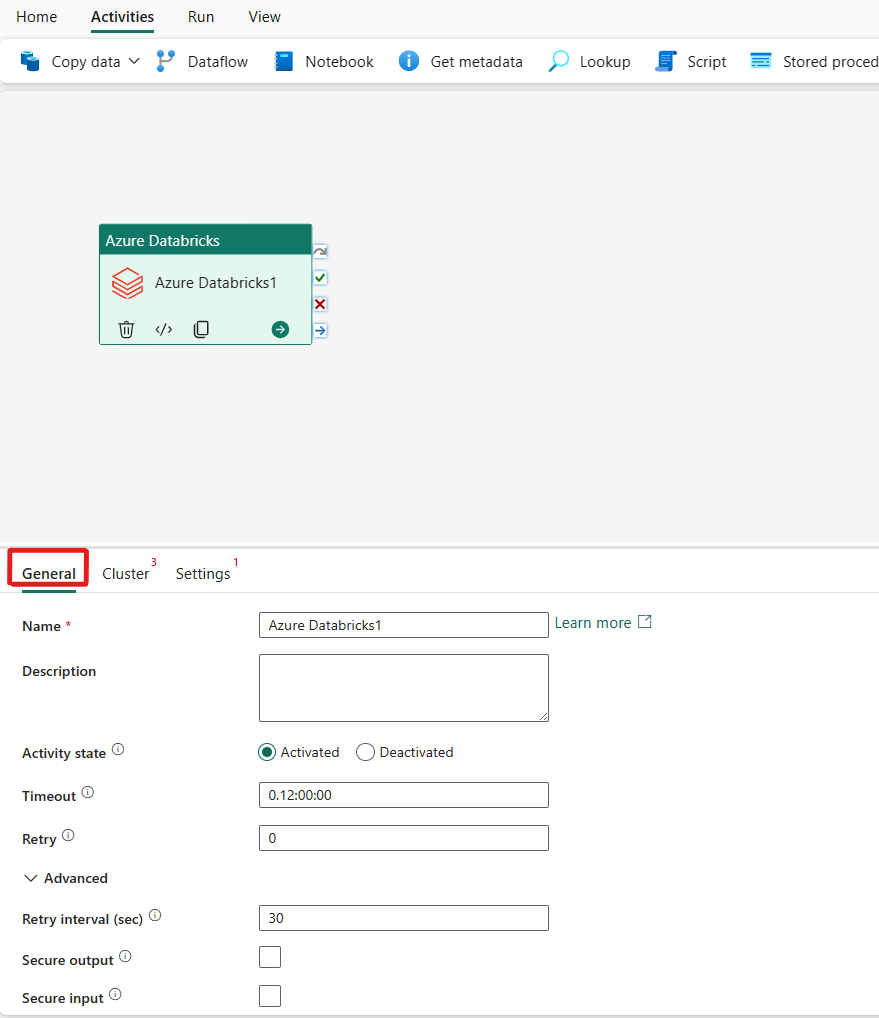
Se vägledningen allmänna inställningar för att konfigurera fliken Allmänna inställningar.
Konfigurera kluster
Välj fliken Kluster . Sedan kan du välja en befintlig eller skapa en ny Azure Databricks-anslutning och sedan välja ett nytt jobbkluster, ett befintligt interaktivt kluster eller en befintlig instanspool.
Beroende på vad du väljer för klustret fyller du i motsvarande fält enligt beskrivningen.
- Under det nya jobbklustret och den befintliga instanspoolen har du också möjlighet att konfigurera antalet arbetare och aktivera instanser av oanvänd kapacitet.
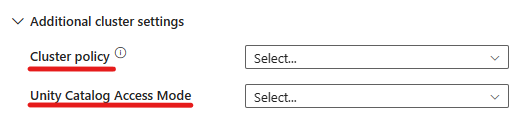
Du kan också ange ytterligare klusterinställningar, till exempel Klusterprincip, Spark-konfiguration, Spark-miljövariabler och anpassade taggar, efter behov för klustret som du ansluter till. Databricks init-skript och målsökväg för klusterloggar kan också läggas till under de ytterligare klusterinställningarna.
Kommentar
Alla avancerade klusteregenskaper och dynamiska uttryck som stöds i den länkade Azure Databricks-tjänsten Azure Databricks i Azure Databricks stöds nu också i Azure Databricks-aktiviteten i Microsoft Fabric under avsnittet "Ytterligare klusterkonfiguration" i användargränssnittet. Eftersom dessa egenskaper nu ingår i aktivitetsgränssnittet; de kan enkelt användas med ett uttryck (dynamiskt innehåll) utan att du behöver den avancerade JSON-specifikationen i den länkade Azure Databricks-tjänsten i Azure Databricks.
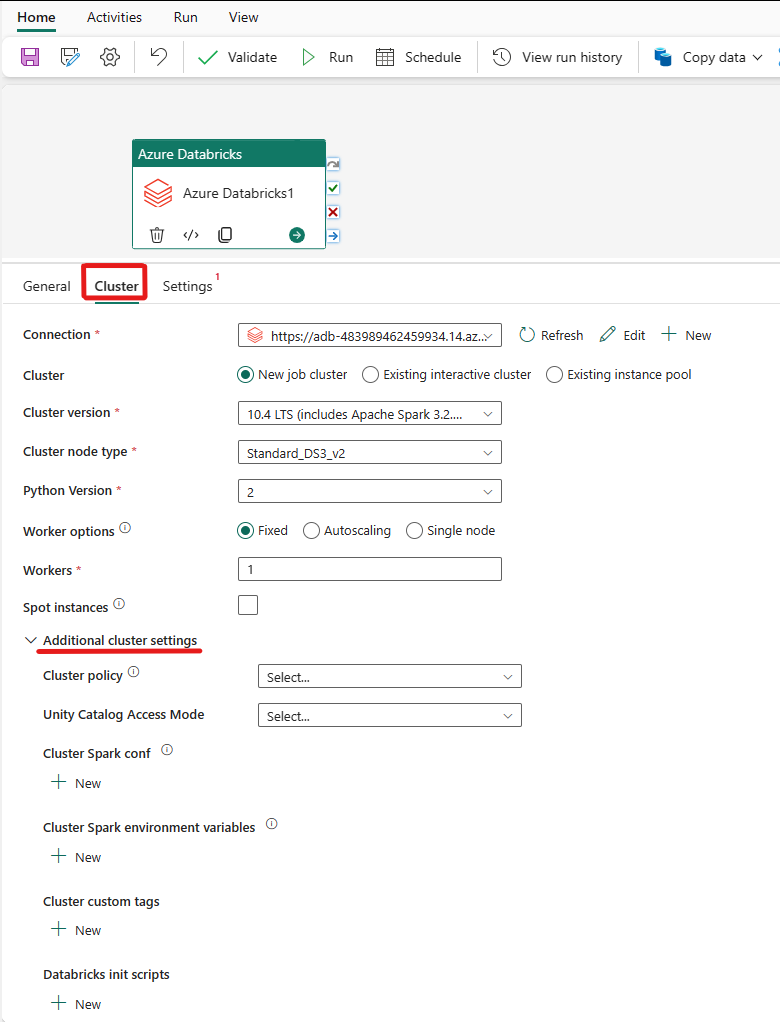
Azure Databricks-aktiviteten stöder nu även stöd för klusterprincip och Unity Catalog.
- Under avancerade inställningar har du möjlighet att välja klusterprincip så att du kan ange vilka klusterkonfigurationer som tillåts.
- Under avancerade inställningar har du också möjlighet att konfigurera åtkomstläget för Unity-katalogen för extra säkerhet. De tillgängliga typerna av åtkomstläge är:
- Enkel användaråtkomstLäge Det här läget är utformat för scenarier där varje kluster används av en enskild användare. Det säkerställer att dataåtkomsten i klustret endast är begränsad till den användaren. Det här läget är användbart för uppgifter som kräver isolering och enskild datahantering.
- Läge för delad åtkomst I det här läget kan flera användare komma åt samma kluster. Den kombinerar Unity Catalogs datastyrning med de äldre åtkomstkontrollistorna för tabeller (ACL). Det här läget möjliggör åtkomst till samarbetsdata samtidigt som styrnings- och säkerhetsprotokoll upprätthålls. Den har dock vissa begränsningar, till exempel att den inte stöder Databricks Runtime ML, Spark-skicka jobb och specifika Spark-API:er och UDF:er.
- Inget åtkomstläge Det här läget inaktiverar interaktion med Unity-katalogen, vilket innebär att kluster inte har åtkomst till data som hanteras av Unity Catalog. Det här läget är användbart för arbetsbelastningar som inte kräver Unity Catalogs styrningsfunktioner.
Konfigurera inställningar
Om du väljer fliken Inställningar kan du välja mellan tre alternativ för vilken Azure Databricks-typ du vill orkestrera.
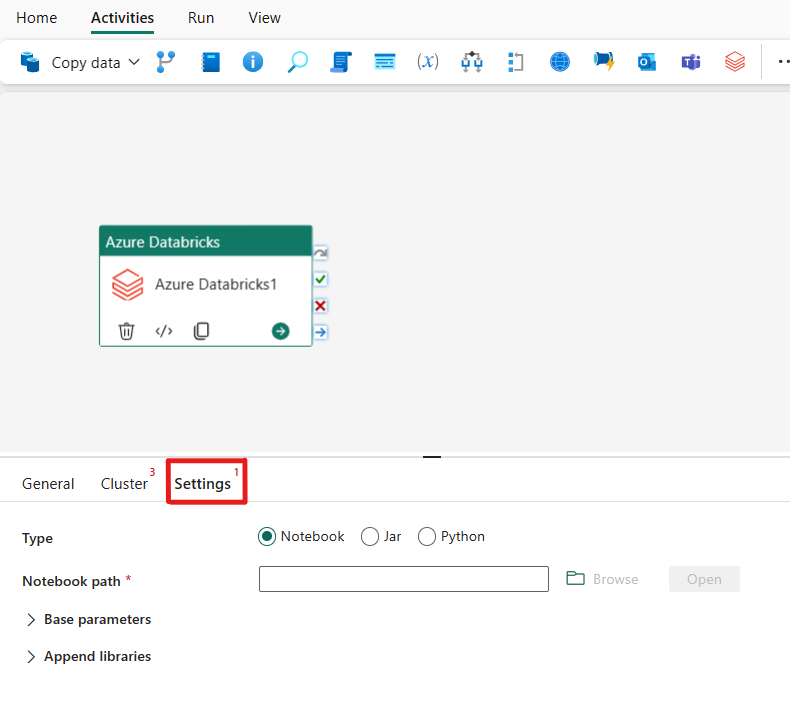
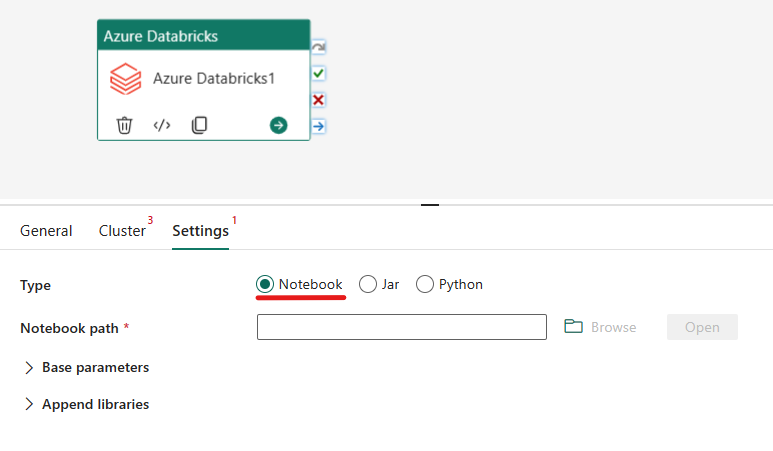
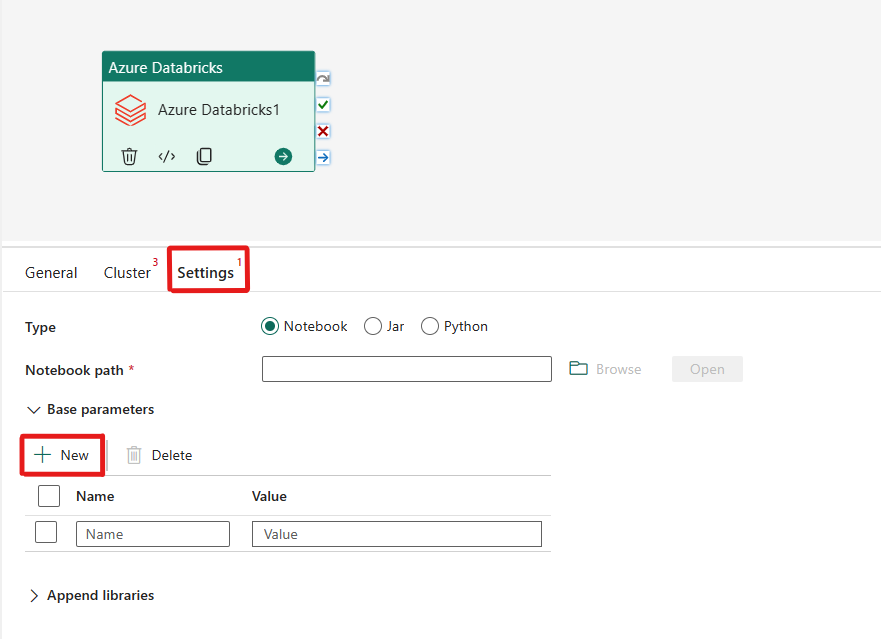
Samordna notebook-typen i Azure Databricks-aktiviteten:
Under fliken Inställningar kan du välja alternativknappen Notebook för att köra en notebook-fil. Du måste ange den notebook-sökväg som ska köras på Azure Databricks, valfria basparametrar som ska skickas till notebook-filen och eventuella ytterligare bibliotek som ska installeras i klustret för att köra jobbet.
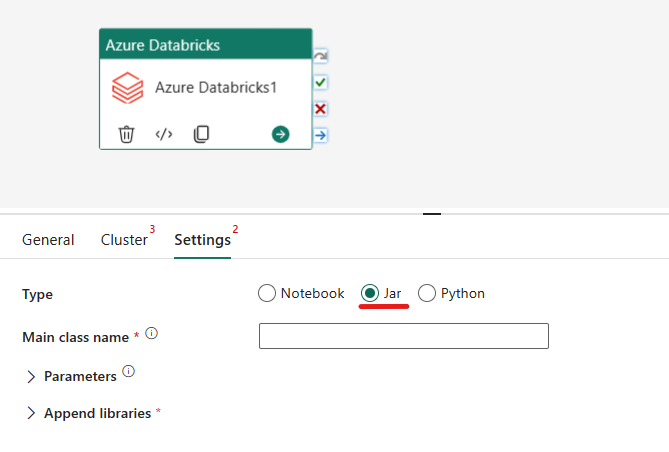
Samordna jar-typen i Azure Databricks-aktiviteten:
Under fliken Inställningar kan du välja knappen Jar-alternativ för att köra en Jar. Du måste ange klassnamnet som ska köras på Azure Databricks, valfria basparametrar som ska skickas till jar-filen och eventuella ytterligare bibliotek som ska installeras i klustret för att köra jobbet.
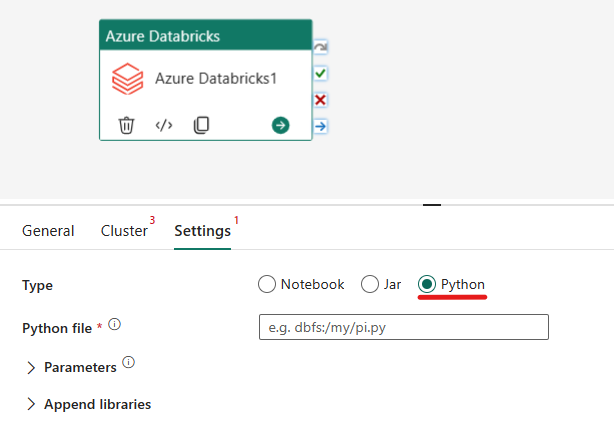
Orkestrera Python-typen i Azure Databricks-aktiviteten:
Under fliken Inställningar kan du välja knappen Python-alternativ för att köra en Python-fil. Du måste ange sökvägen i Azure Databricks till en Python-fil som ska köras, valfria basparametrar som ska skickas och eventuella ytterligare bibliotek som ska installeras i klustret för att köra jobbet.
Bibliotek som stöds för Azure Databricks-aktiviteten
I databricks-aktivitetsdefinitionen ovan kan du ange följande bibliotekstyper: jar, egg, whl, maven, pypi, cran.
Mer information finns i Databricks-dokumentationen för bibliotekstyper.
Skicka parametrar mellan Azure Databricks-aktivitet och pipelines
Du kan skicka parametrar till notebook-filer med hjälp av egenskapen baseParameters i databricks-aktiviteten.
I vissa fall kan du behöva skicka tillbaka vissa värden från notebook-filen till tjänsten, som kan användas för kontrollflöde (villkorsstyrda kontroller) i tjänsten eller användas av underordnade aktiviteter (storleksgränsen är 2 MB).
I notebook-filen kan du till exempel anropa dbutils.notebook.exit("returnValue") och motsvarande "returnValue" returneras till tjänsten.
Du kan använda utdata i tjänsten med hjälp av uttryck som
@{activity('databricks activity name').output.runOutput}.
Spara och köra eller schemalägga pipelinen
När du har konfigurerat andra aktiviteter som krävs för pipelinen växlar du till fliken Start överst i pipelineredigeraren och väljer knappen Spara för att spara pipelinen. Välj Kör för att köra den direkt eller Schemalägg för att schemalägga den. Du kan också visa körningshistoriken här eller konfigurera andra inställningar.
