Schemalägga och köra en Apache Spark-jobbdefinition
Lär dig hur du kör en Microsoft Fabric Apache Spark-jobbdefinition och hittar status och information om jobbdefinitionen.
Förutsättningar
Innan du kommer igång måste du:
- Skapa ett Microsoft Fabric-klientkonto med en aktiv prenumeration. Skapa ett konto kostnadsfritt.
- Förstå Spark-jobbdefinitionen: se Vad är en Apache Spark-jobbdefinition?.
- Skapa en Spark-jobbdefinition: se Så här skapar du en Apache Spark-jobbdefinition i Fabric.
Så här kör du en Spark-jobbdefinition
Det finns två sätt att köra en Spark-jobbdefinition:
Kör en Spark-jobbdefinition manuellt genom att välja Kör från Definitionsobjektet för Spark-jobb i jobblistan.
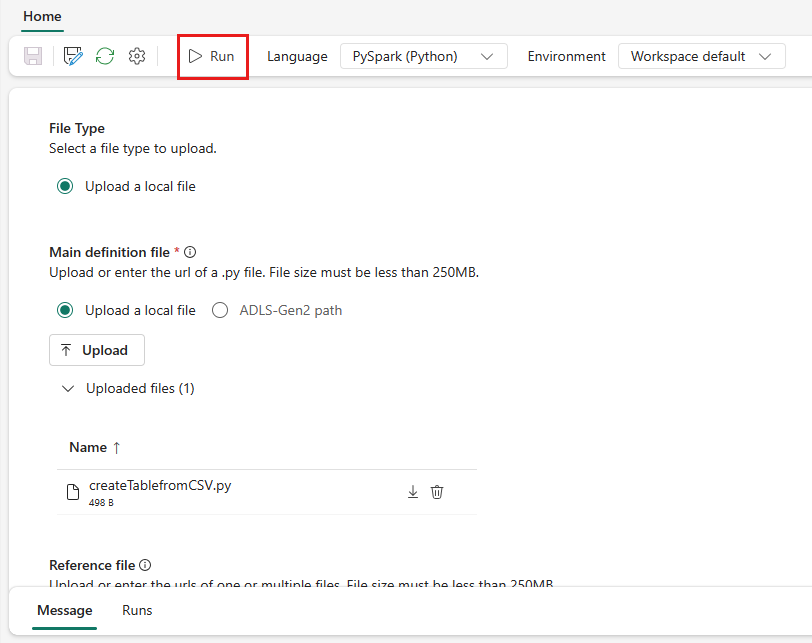
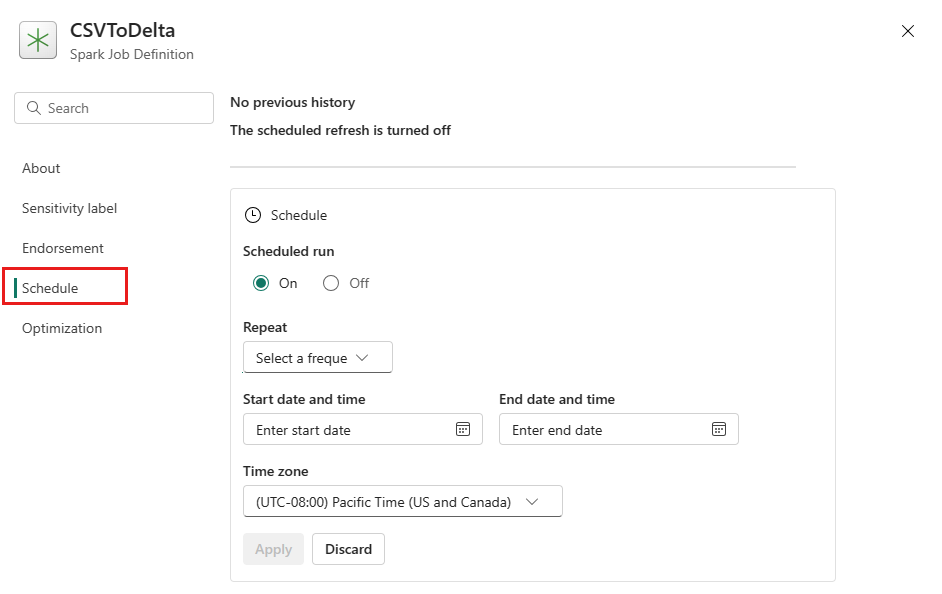
Schemalägg en Spark-jobbdefinition genom att konfigurera en schemaplan på fliken Inställningar. Välj Inställningar i verktygsfältet och välj sedan Schema.
Viktig
För att kunna köras måste en Spark-jobbdefinition ha en huvuddefinitionsfil och en standardkontext för lakehouse.
Tips
För en manuell körning används kontot för den för närvarande inloggade användaren för att skicka jobbet. För en körning som utlöses av ett schema används kontot för den användare som skapade schemaplanen för att skicka jobbet.
Tre till fem sekunder efter att du har skickat körningen visas en ny rad under fliken Körningar. Raden visar information om din nya körning. Kolumnen Status visar jobbets nästan realtidsstatus och kolumnen Kör typ visar om jobbet är manuellt eller schemalagt.
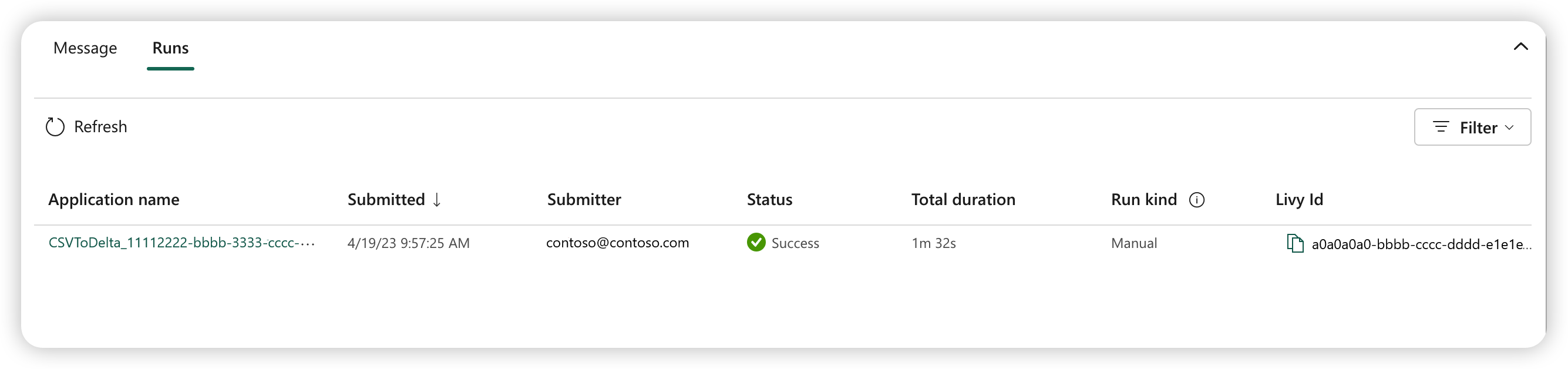
Mer information om hur du övervakar ett jobb finns i Övervaka din Apache Spark-jobbdefinition.
Avbryta ett körande jobb
När jobbet har skickats kan du avbryta jobbet genom att välja Avbryt aktiv körning från Definitionsobjektet för Spark-jobb i jobblistan.
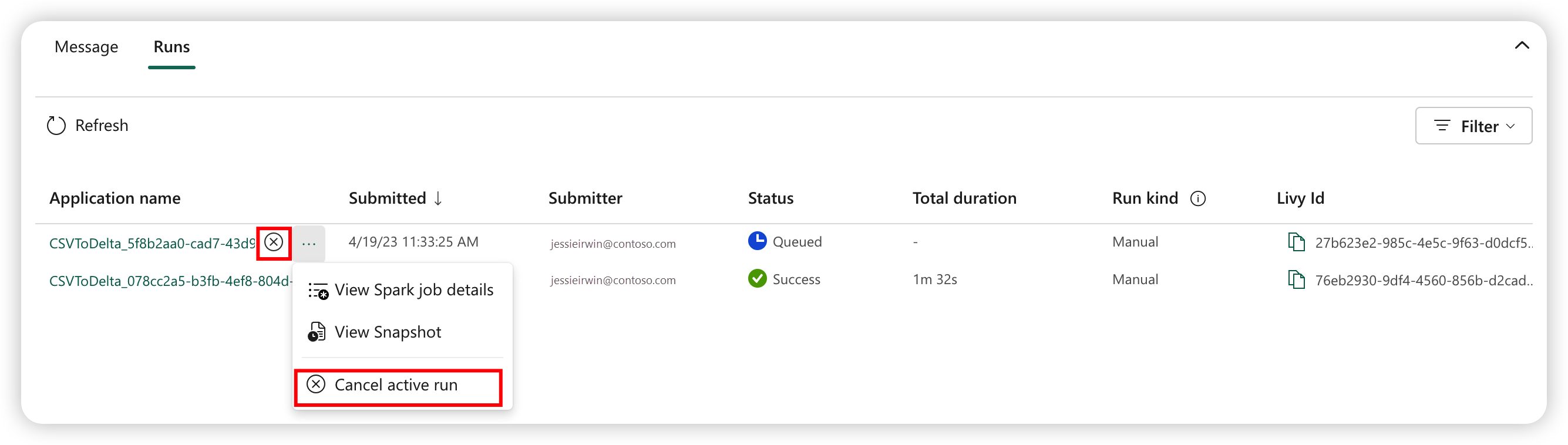
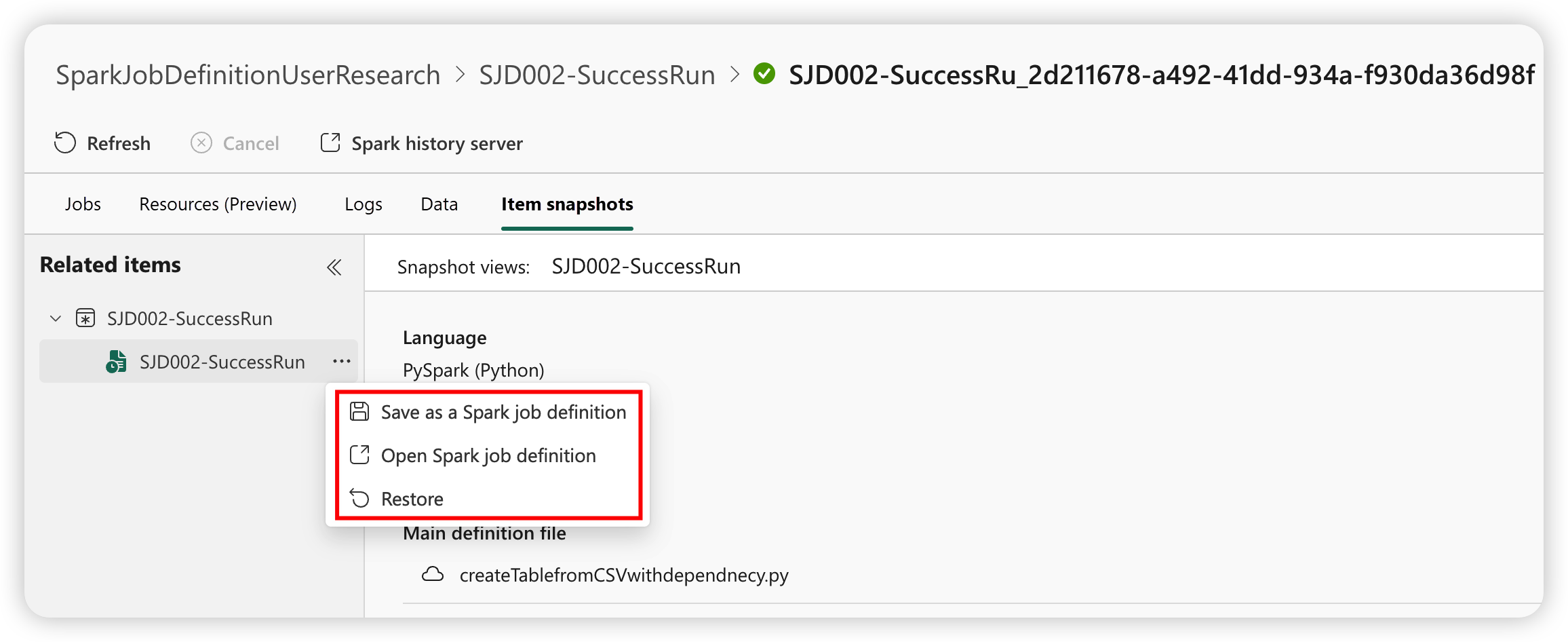
Ögonblicksbild av Spark-jobbdefinition
Spark-jobbdefinitionen lagrar sitt senaste tillstånd. För att visa en ögonblicksbild av historikkörningen väljer du Visa snapshot från definitionsobjektet för Spark-jobb i jobblistan. Ögonblicksbilden visar tillståndet för jobbdefinitionen när jobbet skickas, inklusive huvuddefinitionsfilen, referensfilen, kommandoradsargumenten, det refererade lakehouse-objektet och Spark-egenskaperna.
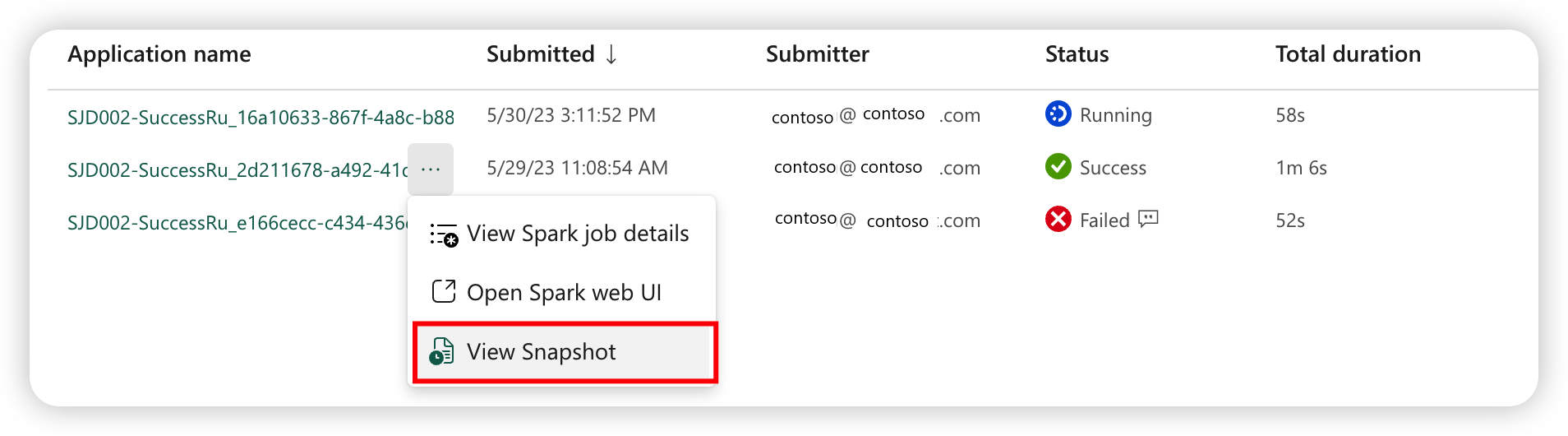
Från en ögonblicksbild kan du vidta tre åtgärder:
- Spara som en Spark-jobbdefinition: Spara ögonblicksbilden som en ny Spark-jobbdefinition.
- Öppna Spark-jobbdefinitionen: Öppna den aktuella Spark-jobbdefinitionen.
- Återställ: Återställ jobbdefinitionen med ögonblicksbilden. Jobbdefinitionen återställs till tillståndet när jobbet skickades.