Använda en notebook-fil för att läsa in data i ditt lakehouse
I den här självstudien får du lära dig hur du läser/skriver data i fabric lakehouse med en notebook-fil. Fabric stöder Spark API och Pandas API för att uppnå det här målet.
Läsa in data med ett Apache Spark-API
I kodcellen i notebook-filen använder du följande kodexempel för att läsa in data från källan och läsa in dem i Filer, Tabeller eller båda delarna av ditt lakehouse.
Om du vill ange den plats som ska läsas från kan du använda den relativa sökvägen om data kommer från standard lakehouse för din aktuella notebook-fil. Eller om data kommer från ett annat lakehouse kan du använda den absoluta ABFS-sökvägen (Azure Blob File System). Kopiera den här sökvägen från snabbmenyn för data.
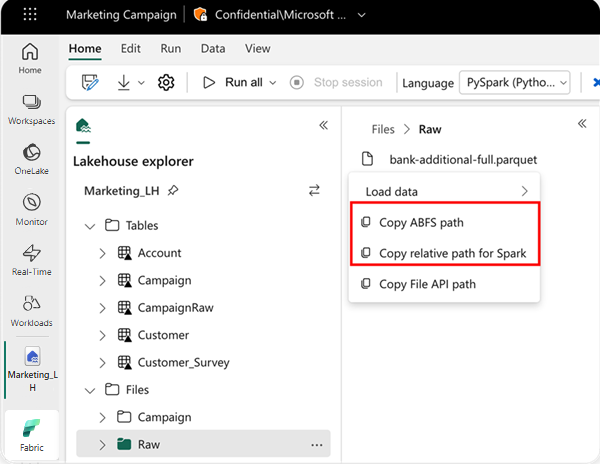
Kopiera ABFS-sökväg: Det här alternativet returnerar filens absoluta sökväg.
Kopiera relativ sökväg för Spark: Det här alternativet returnerar filens relativa sökväg i ditt standardsjöhus.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Läsa in data med Pandas API
För att stödja Pandas-API:et monteras standard lakehouse automatiskt i notebook-filen. Monteringspunkten är "/lakehouse/default/". Du kan använda den här monteringspunkten för att läsa/skriva data från/till standard lakehouse. Alternativet "Kopiera api-sökväg för fil" från snabbmenyn returnerar sökvägen till fil-API:et från monteringspunkten. Sökvägen som returneras från alternativet Kopiera ABFS-sökväg fungerar också för Pandas API.
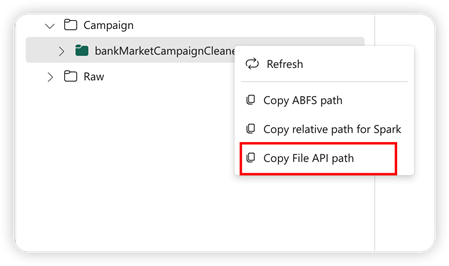
Sökväg för api för kopieringsfil: Det här alternativet returnerar sökvägen under monteringspunkten för standard lakehouse.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Dricks
För Spark API använder du alternativet Kopiera ABFS-sökväg eller Kopiera relativ sökväg för Spark för att hämta sökvägen till filen. För Pandas API använder du alternativet Kopiera ABFS-sökväg eller Sökväg för api för kopieringsfil för att hämta sökvägen till filen.
Det snabbaste sättet att få koden att fungera med Spark API eller Pandas API är att använda alternativet Läs in data och välja det API som du vill använda. Koden genereras automatiskt i en ny kodcell i notebook-filen.
