Ta bort dubbletter i varje tabell för dataidentifiering
Deduplicering hittar och tar bort dubblettposter för en kund från en källtabell så att varje enskild kund representeras av en enda rad i respektive tabell. Varje tabell avgränsas separat med hjälp av regler för att identifiera posterna för en viss kund.
Varje dedupliceringsregel körs mot respektive rad. Om den första regeln matchar raderna 1 och 2, och regel 2 matchar raderna 2 och 3, matchas raderna 1, 2 och 3. När matchade rader hittas väljs en vinnarrad som representerar den kunden baserat på inställningarna för sammanslagning (Mest fyllda, Senaste eller Senaste). Använd alternativet Avancerat för att skapa en vinnarrad genom att välja fält från de olika matchade raderna, till exempel det senaste e-postmeddelandet, men den mest ifyllda adressen.
Customer Insights - Data utför automatiskt följande åtgärder:
- Ta bort dubbletter av poster med samma primärnyckelvärde och välj den första raden i datauppsättningen som vinnare.
- Ta bort dubbletter av poster med hjälp av de matchningsregler som definierats för tabellen vid matchning av rader mellan tabeller.
Definiera regler för deduplicering
En bra regel identifierar en unik kund. Tänk på dina uppgifter. Det kan räcka att identifiera kunder baserat på ett fält som e-post. Om du vill särskilja kunder som delar ett e-postmeddelande kan du välja att ha en regel med två villkor som matchar i E-post + FirstName. Mer information finns i Metodtips för deduplicering.
På sidan Dedupliceringsregler markerar du en tabell och väljer Lägg till regel för att definiera dubblettreglerna.
Dricks
Om du har förädlat tabeller på datakälla nivå för att förbättra resultaten markerar du Använd berikade tabeller längst upp på sidan. Mer information: Berikande för datakällor.
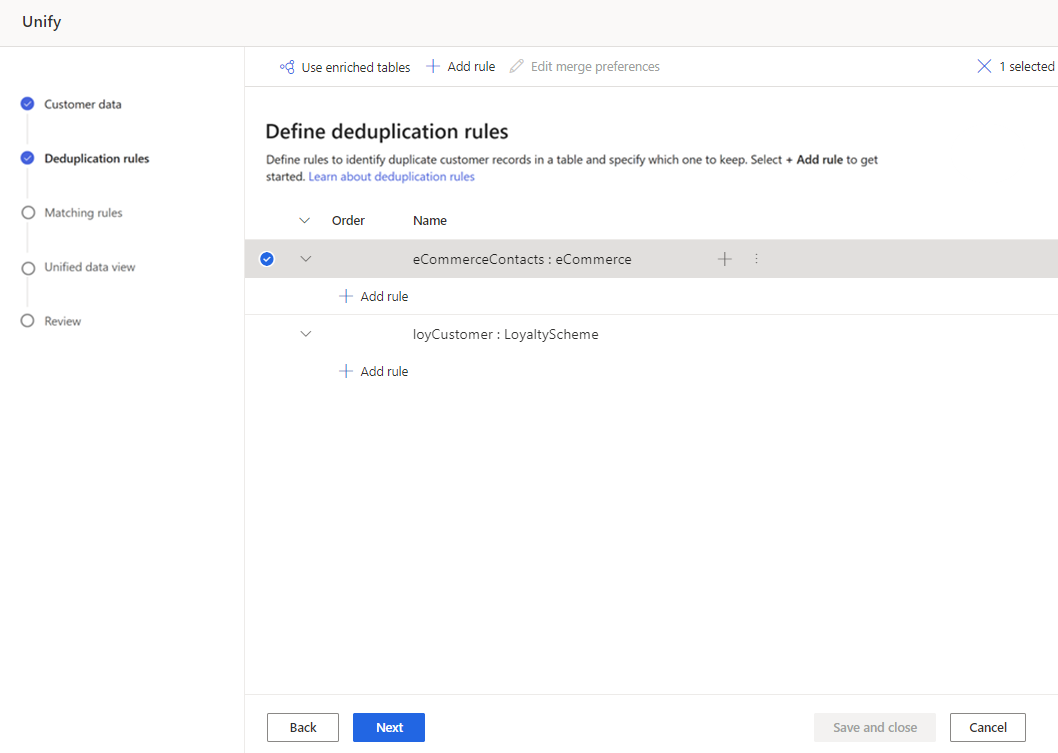
I fönstret Lägg till regel, ange följande information:
Välj fält: Välj i listan över tillgängliga fält från den tabell som du vill söka efter dubbletter i. Välj fält som troligen är unika för varje enskild kund. Till exempel en e-postadress eller kombinationen av namn, ort och telefonnummer.
Normalisera: Välj normaliseringsalternativ för kolumn. Normaliseringen påverkar endast det matchande steget och data ändras inte.
Normalisering Exempel Siffror Konverterar många Unicode-symboler som representerar tal till enkla tal.
Exempel: ❽ och Ⅷ är båda normaliserade till talet 8.
Obs! Symbolerna måste kodas i Unicode Point Format.Symboler Tar bort alla symboler och specialtecken.
Exempel: !?”#$%&'( )+,.-/:;<=>@^~{}`[ ]Text till gemener Konverterar versaler till gemener.
Exempel: ”DETTA Är Ett exEMpel” konverteras till ”detta är ett exempel”Typ – Telefon Konverterar telefoner i olika format till siffror och tar hänsyn till variationer i hur landskoder och anknytningar presenteras. Symboler och blanksteg ignoreras. Inledande 0-siffror i landskoder ignoreras och matchar +1 och +01. Tillägg som betecknas med ett bokstavsprefix ignoreras (X 123). Den normaliserade landskoden är betydande, så en telefon med en landskod matchar inte en telefon utan landskod.
Exempel: +01 425.555.1212 matchar 1 (425) 555-1212
+01 425.555.1212 matchar inte (425) 555-1212Typ – Namn Konverterar över 500 vanliga namnvarianter och titlar.
Exempel: ”debby” -> ”deborah” ”prof” och ”professor” -> ”Prof.”Typ – Adress Konverterar vanliga adressdelar
Exempel: ”street” -> ”st” och ”northwest” -> ”nw”Typ – Organisation Tar bort cirka 50 ”brusord” i företagsnamn, som ”co”, ”corp”, ”corporation” och ”ltd.” Unicode till ASCII Konverterar Unicode-tecken till deras ASCII-motsvarighet i bokstäver
Exempel: Tecknen à, á, â, À, Á, Â, Ã, Ä, Ⓐ och A konverteras till ”a”.Tomt utrymme Tar bort alla blanksteg Aliasmappning Gör att du kan ladda upp en anpassad lista med strängpar som sedan kan användas för att ange strängar som alltid ska betraktas som en exakt matchning.
Använd aliasmapping när du har specifika dataexempel som du tycker borde matcha och som inte matchas med något av de andra normaliseringsmönstren.
Exempel: Scott och Scooter, eller MSFT och Microsoft.Anpassad överhoppning Gör att du kan ladda upp en anpassad lista med strängar som sedan kan användas för att ange strängar som aldrig ska matchas.
Anpassad överhoppning är användbart när du har data med vanliga värden som ska ignoreras, till exempel ett dummy-telefonnummer eller ett dummy-e-postmeddelande.
Exempel: Matcha aldrig telefonnumret 555-1212 eller test@contoso.com
Precision: Ställ in precisionsnivån. Precision används för exakt matchning och fuzzy-matchning och avgör hur lika två strängar måste vara för att betraktas som en matchning.
- Grundläggande: Välj mellan Låg (30 %), Medel (60 %), Hög (80 %) och Exakt (100 %). Välj Exakt om du endast vill matcha poster som matchar 100 procent.
- Anpassad: Ange en procentandel som posterna måste matcha. Systemet matchar endast poster som passerar tröskelvärdet.
Namn: Namn för regeln.
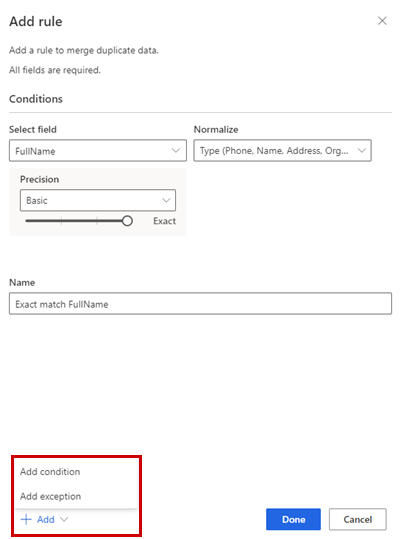
Alternativt väljer du Lägg till>Lägg till villkor om du vill lägga till fler villkor i regeln. Villkoren är kopplade till en logisk OCH-operator och körs därför endast om alla villkor uppfylls.
Alternativt Lägg till>Lägg till undantag till lägga till undantag till regeln. Undantag används för att hantera få fall av falskt positiva och falskt negativa.
Välj Klar för att skapa regeln.
Alternativt kan du lägga till fler regler.

Välj kopplingsinställningar
När regler körs och dubblettposter identifieras för en kund väljs en ”vinnarrad” baserat på sammanfogningsprincipen. Vinnarraden representerar kunden i nästa föreningssteg som matchar poster mellan tabeller. Data på raderna för icke-vinnare (”alternativ”) används i steget Sammanslagning av matchningsregler för att matcha poster från andra tabeller till vinnarraden. Den här metoden förbättrar matchningsresultaten genom att tillåta information som tidigare telefonnummer för att identifiera matchande poster. Vinnarraden kan konfigureras så att den är den mest fyllda, senaste eller senaste av de dubblettposter som hittas.
Välj en tabellen och redigera inställningarna för kopplade dokument. Rutan Kopplingsinställningar visas.
Välj ett av tre alternativ för att avgöra vilken post som ska behållas om en dubblett påträffas:
- Mest ifylld: Identifierar posten med flest befolkade kolumner som vinnarpost. Det här är standardalternativet för sammanfogning.
- Senaste: Identifierar vinnarpost baserat på aktualitet. Kräver ett datum eller ett numeriskt fält för att definiera aktualitet.
- Minst aktuell: Identifierar vinnarpost baserat på lägsta aktualitet. Kräver ett datum eller ett numeriskt fält för att definiera aktualitet.
Vid händelse av en händelse är posten den med MAX(PK) eller det större primärnyckelns värde.
Om du vill definiera kopplingsinställningar för enskilda kolumner för en tabell väljer du Avancerat längst ned i fönstret. Du kan till exempel välja att behålla den senaste e-postadressen OCH den mest fullständiga adressen från olika poster. Expandera tabellen för att se alla dess kolumner och definiera vilket alternativ som ska användas för enskilda kolumner. Om du väljer ett recency-baserat alternativ måste du också ange ett datum- och tidsfält som definierar recency.
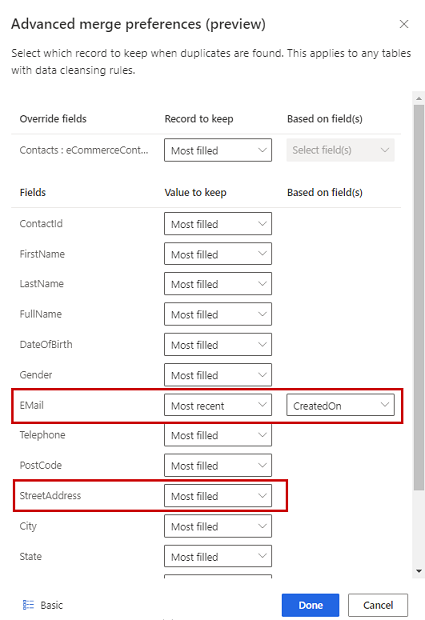
Välj Klart för att tillämpa kopplingsinställningar.
När du har definierat dedupliceringsreglerna och sammanslagningsinställningarna väljer du Nästa.