Använd Azure Machine Learning-baserade modeller
Enhetliga data i Dynamics 365 Customer Insights – data är en källa för maskininlärningsmodeller som kan generera ytterligare affärsinsikter. Customer Insights - Data integreras med Azure Machine Learning för att använda dina egna anpassade modeller.
Förutsättningar
- Åtkomst till Customer Insights - Data
- Aktiv prenumeration på Azure Enterprise
- Enhetliga kundprofiler
- Tabellexport till Azure Blob Storage konfigurerad
Konfigurera arbetsytan Azure Machine Learning
Se skapa en Azure Machine Learning-arbetsyta för olika alternativ för att skapa arbetsytan. För bästa prestanda skapar du arbetsytan i en Azure-region som är geografiskt närmast din Customer Insights-miljö.
Få åtkomst till din arbetsyta via Azure Machine Learning Studio. Du kan interagera med arbetsytan på flera olika sätt.
Arbeta med Azure Machine Learning-designer
Azure Machine Learning designer är en visuell designdesigner där du kan dra och släppa datauppsättningar och moduler. En batch-pipeline som skapats från designern kan integreras i Customer Insights - Data om de konfigureras i enlighet med detta.
Arbeta med Azure Machine Learning SDK
Dataforskare och AI-utvecklare använder Azure Machine Learning SDK för att bygga maskininlärningsarbetsflöden. För närvarande kan modeller som utbildats med hjälp av SDK inte integreras direkt. En batchinferenspipeline som förbrukar den modellen krävs för integration med Customer Insights - Data.
Krav på batch-pipeline för att integrera med Customer Insights - Data
Konfiguration av datauppsättning
Skapa datauppsättningar för att använda tabelldata från Customer Insights till din batchinferenspipeline. Registrera datauppsättningar på arbetsytan. För närvarande stöder vi bara tabelldatauppsättningar i .csv-format. Parametrisera datauppsättningarna som motsvarar tabelldata en pipeline-parameter.
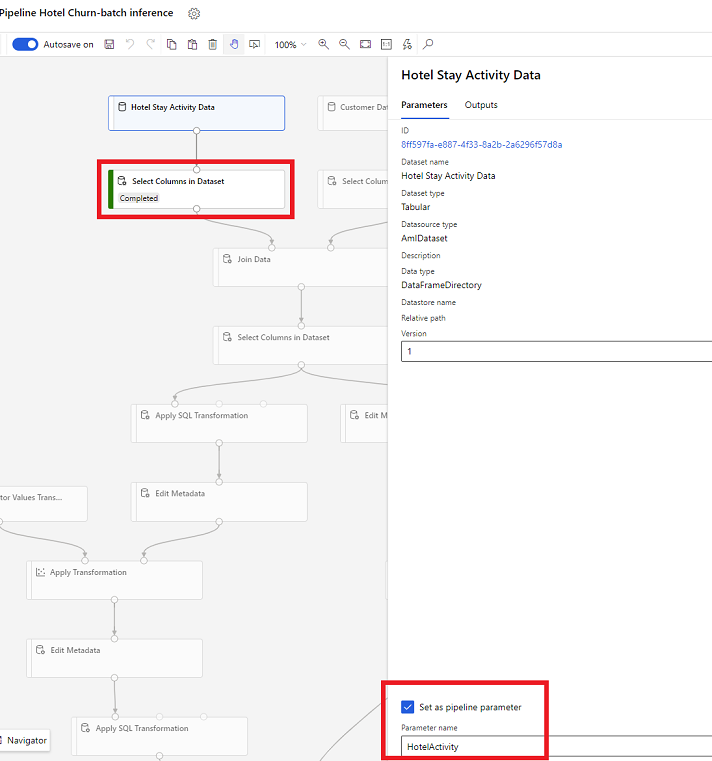
Datauppsättningsparametrar i Designer
I designern öppnar du Välj kolumner i datauppsättning och välj Ställ in som pipeline-parameter där du anger ett namn på parametern.
Datauppsättningsparameter i SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Batchinferenspipeline
I designern kan en utbildningspipeline användas för att skapa eller uppdatera en inferenspipeline. För närvarande stöds endast batchinferenspipelines.
Med hjälp av SDK kan du publicera pipelinen till en slutpunkt. För närvarande integreras Customer Insights - Data med standardpipelinen i en batchpipelines slutpunkt i Machine Learning-arbetsytan.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Importera pipelinedata
Designern tillhandahåller modulen Exportera data som gör att utdata från en pipeline kan exporteras till Azure Storage. För närvarande måste modulen använda datalagringstypen Azure Blob Storage and parameterisera Datalagring och relativ Sökväg. Systemet båda dessa parametrar under pipelinekörning med en datalagring och sökväg som är åtkomlig för appen.
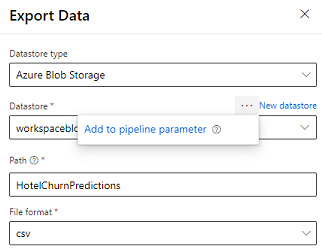
När du skriver inferensutdata med hjälp av kod kan du ladda upp utdata till en sökväg inom en registrerad datalagring på arbetsytan. Om sökvägen och datalagringen är parameteriserade i pipelinen, kommer Customer insights att kunna läsa och importera inferensutdata. För närvarande stöds en enda tabellutdata i CSV-format. Sökvägen måste innehålla katalogen och filnamnet.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name