Analysera sentiment med hjälp av ML.NET CLI
Lär dig hur du använder ML.NET CLI för att automatiskt generera en ML.NET modell och underliggande C#-kod. Du anger din datauppsättning och den maskininlärningsuppgift som du vill implementera, och CLI använder AutoML-motorn för att skapa källkoden för modellgenerering och distribution samt klassificeringsmodellen.
I den här självstudien gör du följande:
- Förbereda dina data för den valda maskininlärningsuppgiften
- Kör kommandot "mlnet classification" från CLI
- Granska kvalitetsmåttresultaten
- Förstå den genererade C#-koden för att använda modellen i ditt program
- Utforska den genererade C#-koden som användes för att träna modellen
Anteckning
Det här avsnittet refererar till verktyget ML.NET CLI, som för närvarande finns i förhandsversion, och material kan komma att ändras. Mer information finns på sidan ML.NET .
ML.NET CLI är en del av ML.NET och huvudmålet är att "demokratisera" ML.NET för .NET-utvecklare när de lär sig ML.NET så att du inte behöver koda från grunden för att komma igång.
Du kan köra ML.NET CLI på valfri kommandotolk (Windows, Mac eller Linux) för att generera ML.NET modeller och källkod av god kvalitet baserat på träningsdatauppsättningar som du tillhandahåller.
Förutsättningar
- .NET Core 6 SDK eller senare
- (Valfritt) Visual Studio
- ML.NET CLI
Du kan antingen köra de genererade C#-kodprojekten från Visual Studio eller med dotnet run (.NET CLI).
Förbereda dina data
Vi ska använda en befintlig datauppsättning som används för ett scenario med attitydanalys, vilket är en maskininlärningsuppgift för binär klassificering. Du kan använda din egen datauppsättning på ett liknande sätt, och modellen och koden genereras åt dig.
Ladda ned zip-filen UCI Sentiment Labeled Sentences (se citat i följande anteckning) och packa upp den på valfri mapp.
Anteckning
Datauppsättningarna i den här självstudien använder en datauppsättning från "Från grupp till enskilda etiketter med hjälp av djupa funktioner", Kotzias et al,. KDD 2015 och värdhanteras på UCI Machine Learning Repository - Dua, D. och Karra Taniskidou, E. (2017). UCI Machine Learning-lagringsplats [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
yelp_labelled.txtKopiera filen till valfri mapp som du skapade tidigare (till exempel/cli-test).Öppna önskad kommandotolk och gå till mappen där du kopierade datauppsättningsfilen. Ett exempel:
cd /cli-testMed valfri textredigerare, till exempel Visual Studio Code, kan du öppna och utforska
yelp_labelled.txtdatamängdsfilen. Du kan se att strukturen är:Filen har inget sidhuvud. Du använder kolumnens index.
Det finns bara två kolumner:
Text (kolumnindex 0) Etikett (kolumnindex 1) Wow... Älskade det här stället. 1 Skorpan är inte bra. 0 Inte välsmakande och konsistensen var bara otäck. 0 ... MÅNGA FLER TEXTRADER... ... (1 eller 0)...
Se till att du stänger datamängdsfilen från redigeraren.
Nu är du redo att börja använda CLI för det här "Sentiment Analysis"-scenariot.
Anteckning
När du har slutfört den här självstudien kan du också prova med dina egna datauppsättningar så länge de är redo att användas för någon av de ML-uppgifter som för närvarande stöds av ML.NET CLI Preview som är "binär klassificering", "klassificering", "regression" och "rekommendation".
Kör kommandot mlnet classification
Kör följande kommando ML.NET CLI:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Det här kommandot kör
mlnet classificationkommandot:- för ML-klassificeringsuppgiften
- använder datauppsättningsfilen
yelp_labelled.txtsom tränings- och testdatauppsättning (internt använder CLI antingen korsvalidering eller delar upp den i två datauppsättningar, en för träning och en för testning) - där den mål-/målkolumn som du vill förutsäga (kallas ofta "etikett") är kolumnen med index 1 (det är den andra kolumnen, eftersom indexet är nollbaserat)
- använder inte en filrubrik med kolumnnamn eftersom den här datamängdsfilen inte har någon rubrik
- den riktade utforsknings-/tågtiden för experimentet är 10 sekunder
Du ser utdata från CLI, ungefär så här:
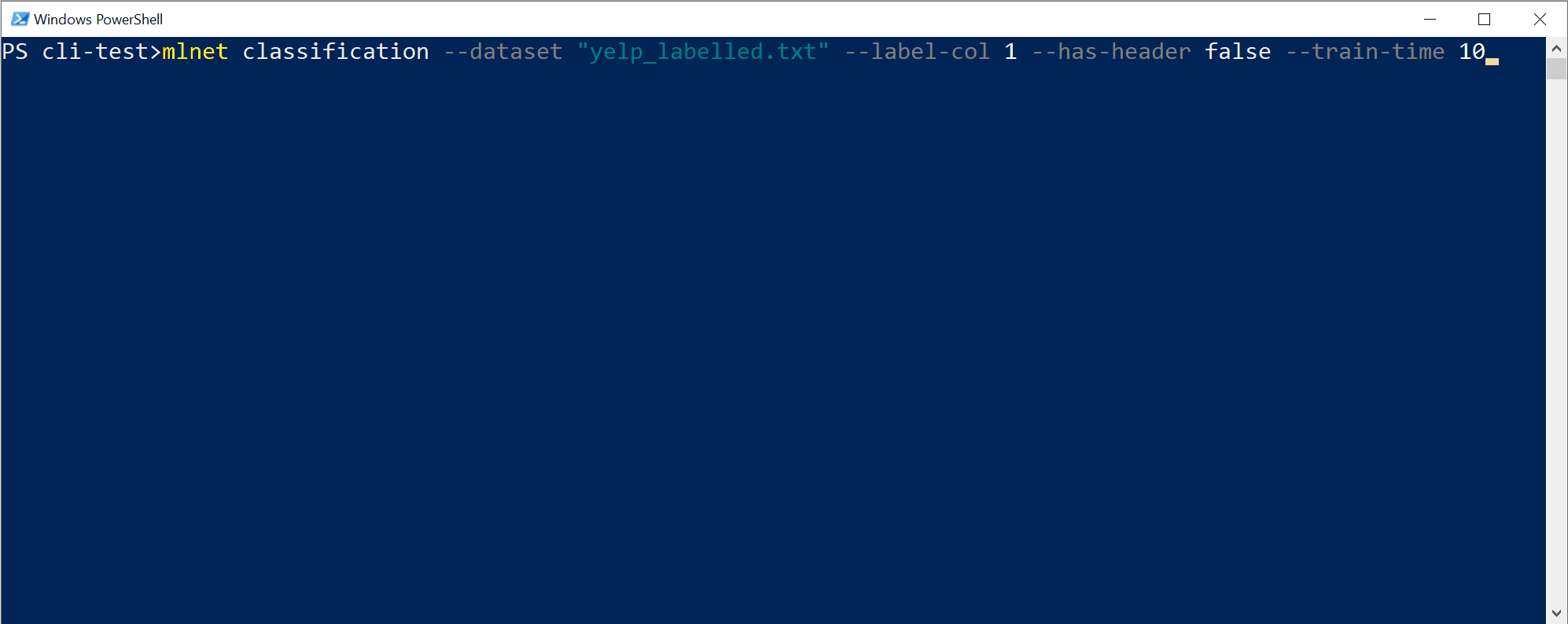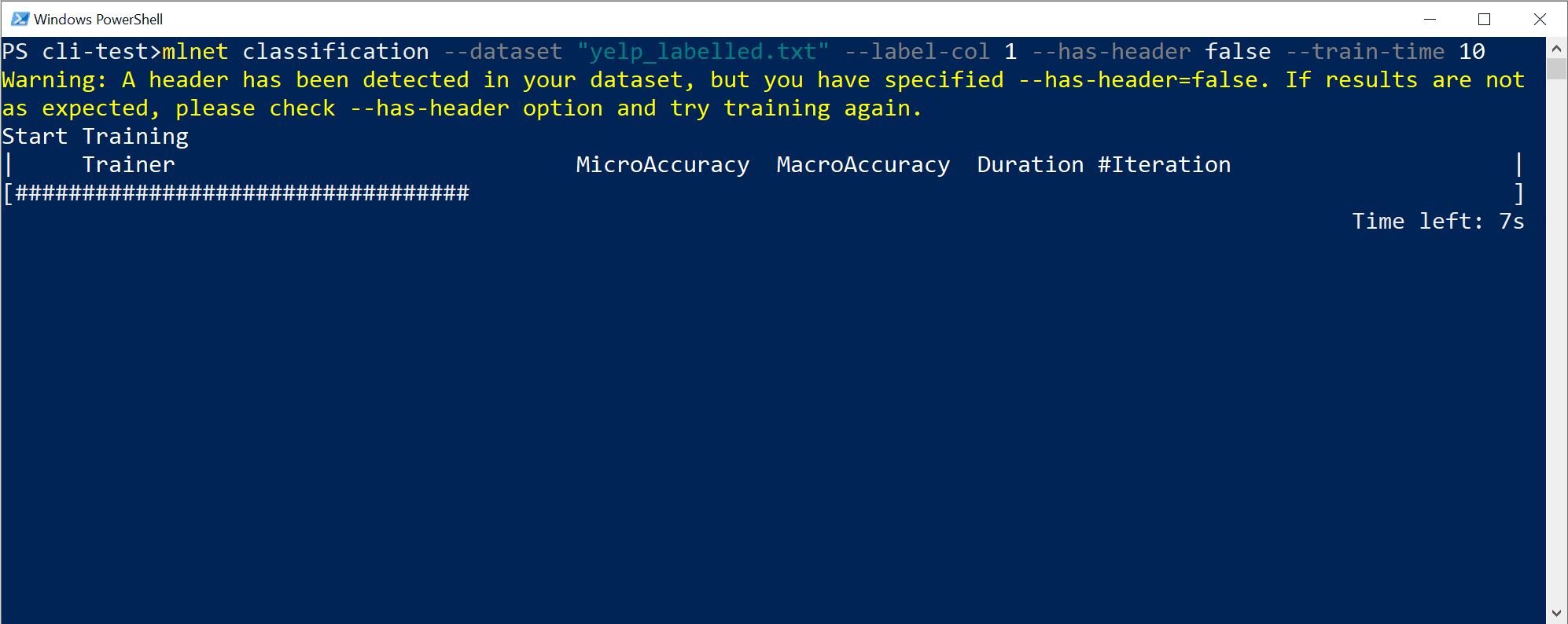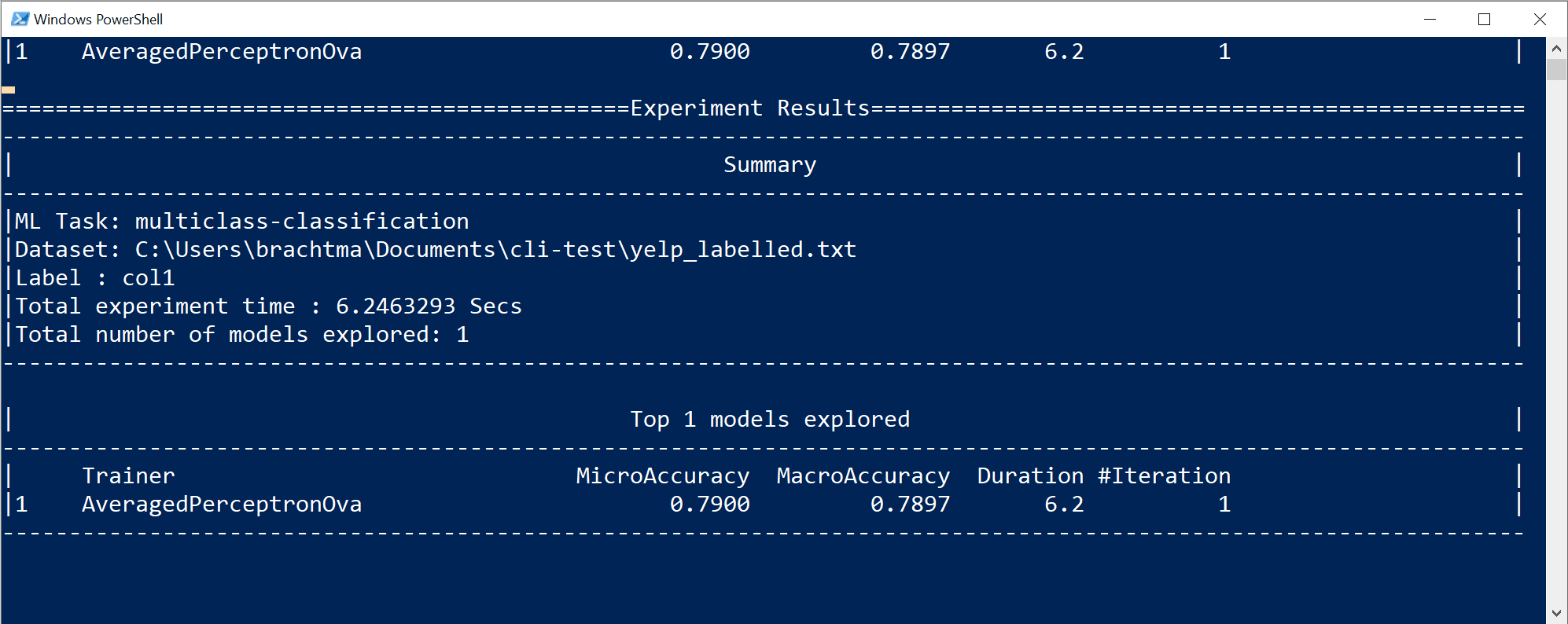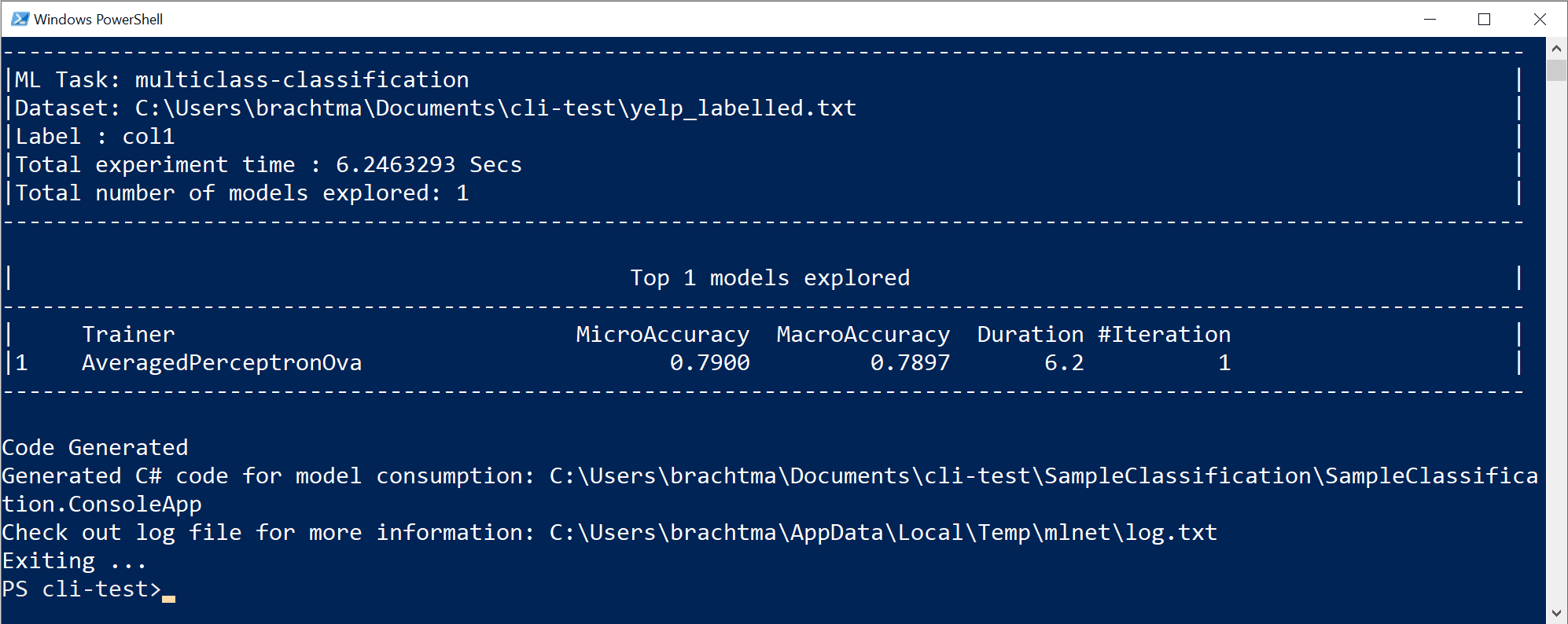
I det här fallet, på bara 10 sekunder och med den lilla datauppsättningen som tillhandahålls, kunde CLI-verktyget köra ganska många iterationer, vilket innebär träning flera gånger baserat på olika kombinationer av algoritmer/konfiguration med olika interna datatransformationer och algoritmens hyperparametrar.
Slutligen är modellen med "bästa kvalitet" på 10 sekunder en modell som använder en viss tränare/algoritm med en specifik konfiguration. Beroende på utforskningstiden kan kommandot generera ett annat resultat. Markeringen baseras på de flera mått som visas, till exempel
Accuracy.Förstå modellens kvalitetsmått
Det första och enklaste måttet för att utvärdera en modell för binär klassificering är noggrannheten, som är enkel att förstå. "Noggrannhet är andelen korrekta förutsägelser med en testdatauppsättning.". Desto närmare 100 % (1,00) desto bättre.
Det finns dock fall där det inte räcker att bara mäta med måttet Noggrannhet, särskilt när etiketten (0 och 1 i det här fallet) är obalanserad i testdatauppsättningen.
Ytterligare mått och mer detaljerad information om mått som Noggrannhet, AUC, AUCPR och F1-poäng som används för att utvärdera de olika modellerna finns i Förstå ML.NET mått.
Anteckning
Du kan prova samma datauppsättning och ange några minuter för
--max-exploration-time(till exempel tre minuter så att du anger 180 sekunder) som hittar en bättre "bästa modell" för dig med en annan träningspipelinekonfiguration för den här datauppsättningen (som är ganska liten, 1 000 rader).För att hitta en "bästa/bra kvalitet"-modell som är en "produktionsklar modell" för större datamängder bör du göra experiment med CLI som vanligtvis anger mycket mer utforskningstid beroende på datauppsättningens storlek. I många fall kan du kräva flera timmars utforskningstid, särskilt om datauppsättningen är stor på rader och kolumner.
Den tidigare kommandokörningen har genererat följande tillgångar:
- En serialiserad modell .zip ("bästa modell") som är redo att användas.
- C#-kod för att köra/poängsätta den genererade modellen (För att göra förutsägelser i dina slutanvändarappar med den modellen).
- C#-träningskod som används för att generera den modellen (utbildningsändamål).
- En loggfil med alla iterationer utforskade med specifik detaljerad information om varje algoritm som provas med sin kombination av hyperparametrar och datatransformeringar.
De två första tillgångarna (.ZIP filmodell och C#-kod för att köra modellen) kan användas direkt i dina slutanvändarappar (ASP.NET Core webbapp, tjänster, skrivbordsapp osv.) för att göra förutsägelser med den genererade ML-modellen.
Den tredje tillgången, träningskoden, visar vilka ML.NET API-kod som användes av CLI för att träna den genererade modellen, så att du kan undersöka vilken specifik tränare/algoritm och hyperparametrar som har valts av CLI.
Dessa uppräknade tillgångar förklaras i följande steg i självstudien.
Utforska den genererade C#-koden som ska användas för att köra modellen för att göra förutsägelser
I Visual Studio öppnar du lösningen som genererades i mappen med namnet
SampleClassificationi den ursprungliga målmappen (den namngavs/cli-testi självstudien). Du bör se en lösning som liknar:
Anteckning
I självstudien föreslår vi att du använder Visual Studio, men du kan också utforska den genererade C#-koden (två projekt) med valfri textredigerare och köra den genererade konsolappen
dotnet CLImed på en macOS-, Linux- eller Windows-dator.- Den genererade konsolappen innehåller körningskod som du måste granska och sedan återanvänder du vanligtvis "bedömningskoden" (kod som kör ML-modellen för att göra förutsägelser) genom att flytta den enkla koden (bara några rader) till ditt slutanvändarprogram där du vill göra förutsägelserna.
- Den genererade mbconfig-filen är en konfigurationsfil som kan användas för att träna om din modell, antingen via CLI eller via Model Builder. Detta har också två kodfiler som är associerade med den och en zip-fil.
- Träningsfilen innehåller koden för att skapa modellpipelinen med hjälp av ML.NET-API:et.
- Förbrukningsfilen innehåller koden för att använda modellen.
- Zip-filen som är den genererade modellen från CLI.
Öppna filen SampleClassification.consumption.cs i mbconfig-filen . Du ser att det finns indata- och utdataklasser. Det här är dataklasser, eller POCO-klasser, som används för att lagra data. Klasserna innehåller exempelkod som är användbar om din datauppsättning har tiotals eller till och med hundratals kolumner.
- Klassen
ModelInputanvänds när du läser data från datauppsättningen. - Klassen
ModelOutputanvänds för att hämta förutsägelseresultatet (förutsägelsedata).
- Klassen
Öppna filen Program.cs och utforska koden. På bara några rader kan du köra modellen och göra en exempelförutsägelse.
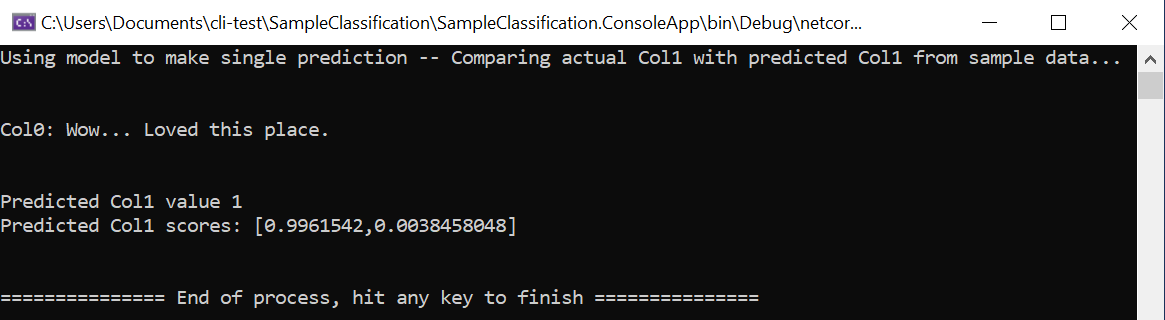
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }De första kodraderna skapar en enda exempeldata, i det här fallet baserat på den första raden i datauppsättningen som ska användas för förutsägelsen. Du kan också skapa egna "hårdkodade" data genom att uppdatera koden:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };Nästa kodrad använder
SampleClassification.Predict()metoden på angivna indata för att göra en förutsägelse och returnera resultatet (baserat på schemat ModelOutput.cs).De sista kodraderna skriver ut egenskaperna för exempeldata (i det här fallet kommentaren) samt attitydförutsägelse och motsvarande poäng för positiv attityd (1) och negativ attityd (2).
Kör projektet, antingen med hjälp av de ursprungliga exempeldata som lästes in från den första raden i datamängden eller genom att tillhandahålla dina egna anpassade hårdkodade exempeldata. Du bör få en förutsägelse som är jämförbar med:
 )
)
- Prova att ändra hårdkodade exempeldata till andra meningar med olika attityd och se hur modellen förutsäger positiv eller negativ attityd.
Infuse your end-user applications with ML model predictions (Använd dina slutanvändarprogram med ML-modellförutsägelser)
Du kan använda liknande "ML-modellbedömningskod" för att köra modellen i ditt slutanvändarprogram och göra förutsägelser.
Du kan till exempel flytta koden direkt till alla Windows-skrivbordsprogram som WPF och WinForms och köra modellen på samma sätt som den gjordes i konsolappen.
Hur du implementerar dessa kodrader för att köra en ML-modell bör dock optimeras (d.v.s. cachelagrar modellen .zip filen och läser in den en gång) och har singleton-objekt i stället för att skapa dem på varje begäran, särskilt om ditt program behöver vara skalbart, till exempel ett webbprogram eller en distribuerad tjänst, enligt beskrivningen i följande avsnitt.
Köra ML.NET modeller i skalbara ASP.NET Core webbappar och tjänster (flertrådade appar)
Skapandet av modellobjektet (ITransformer som läses in från en modells .zip fil) och PredictionEngine objektet bör optimeras, särskilt när det körs på skalbara webbappar och distribuerade tjänster. För det första är modellobjektet (ITransformer) optimeringen enkel. Eftersom objektet ITransformer är trådsäkert kan du cachelagrat objektet som ett singleton- eller statiskt objekt så att du läser in modellen en gång.
För det andra objektet, PredictionEngine objektet, är det inte så enkelt eftersom PredictionEngine objektet inte är trådsäkert, därför kan du inte instansiera det här objektet som singleton- eller statiskt objekt i en ASP.NET Core app. Det här trådsäkra och skalbara problemet beskrivs djupt i det här blogginlägget.
Men det blev mycket enklare för dig än vad som förklaras i det blogginlägget. Vi har arbetat med en enklare metod åt dig och har skapat ett trevligt .NET Core-integreringspaket som du enkelt kan använda i dina ASP.NET Core appar och tjänster genom att registrera det i programmets DI-tjänster (dependency injection services) och sedan direkt använda det från din kod. Kontrollera följande självstudie och exempel för att göra det:
- Självstudie: Köra ML.NET modeller på skalbara ASP.NET Core webbappar och WebAPIs
- Exempel: Skalbar ML.NET modell på ASP.NET Core WebAPI
Utforska den genererade C#-koden som användes för att träna modellen med "bästa kvalitet"
I mer avancerade utbildningssyften kan du även utforska den genererade C#-kod som användes av CLI-verktyget för att träna den genererade modellen.
Träningsmodellkoden genereras i filen med namnet SampleClassification.training.cs, så att du kan undersöka träningskoden.
Ännu viktigare är att för det här specifika scenariot (attitydanalysmodell) kan du också jämföra den genererade träningskoden med koden som förklaras i följande självstudie:
Det är intressant att jämföra den valda algoritmen och pipelinekonfigurationen i självstudien med koden som genereras av CLI-verktyget. Beroende på hur mycket tid du ägnar åt att iterera och söka efter bättre modeller kan den valda algoritmen skilja sig åt tillsammans med dess specifika hyperparametrar och pipelinekonfiguration.
I den här självstudiekursen lärde du dig att:
- Förbereda dina data för den valda ML-uppgiften (problem att lösa)
- Kör kommandot "mlnet classification" i CLI-verktyget
- Granska kvalitetsmåttresultaten
- Förstå den genererade C#-koden för att köra modellen (kod som ska användas i din slutanvändarapp)
- Utforska den genererade C#-koden som användes för att träna modellen med "bästa kvalitet" (vinstsyften)