Självstudie: Automatiserad visuell inspektion med överföringsinlärning med API:et för ML.NET-bildklassificering
Lär dig hur du tränar en anpassad djupinlärningsmodell med hjälp av överföringsinlärning, en förtränad TensorFlow-modell och API:et för ML.NET bildklassificering för att klassificera bilder av betongytor som spruckna eller obeackade.
I den här guiden får du lära dig att:
- Förstå problemet
- Läs mer om ML.NET API för bildklassificering
- Förstå den förtränad modellen
- Använda överföringsinlärning för att träna en anpassad TensorFlow-bildklassificeringsmodell
- Klassificera bilder med den anpassade modellen
Krav
Översikt över utbildningsexempel för överföring av bildklassificering
Det här exemplet är ett C# .NET Core-konsolprogram som klassificerar bilder med hjälp av en förtränad TensorFlow-modell för djupinlärning. Koden för det här exemplet finns i exempelwebbläsaren.
Förstå problemet
Bildklassificering är ett problem med visuellt innehåll. Bildklassificering tar en bild som indata och kategoriserar den i en föreskriven klass. Bildklassificeringsmodeller tränas ofta med djupinlärning och neurala nätverk. Mer information finns i Djupinlärning jämfört med maskininlärning .
Några scenarier där bildklassificering är användbart är:
- Ansiktsigenkänning
- Känsloidentifiering
- Medicinsk diagnos
- Identifiering av landmärke
Den här självstudien tränar en anpassad bildklassificeringsmodell för att utföra automatiserad visuell inspektion av bryggdäck för att identifiera strukturer som skadas av sprickor.
ML.NET API för bildklassificering
ML.NET tillhandahåller olika sätt att utföra bildklassificering. Den här självstudien använder överföringsinlärning med hjälp av API:et för bildklassificering. API:et för bildklassificering använder TensorFlow.NET, ett bibliotek på låg nivå som tillhandahåller C#-bindningar för TensorFlow C++-API:et.
Vad är överföringsinlärning?
Överföringsinlärning tillämpar kunskap som erhållits från att lösa ett problem på ett annat relaterat problem.
Träning av en djupinlärningsmodell från grunden kräver att du anger flera parametrar, en stor mängd märkta träningsdata och en stor mängd beräkningsresurser (hundratals GPU-timmar). Genom att använda en förtränad modell tillsammans med överföringsinlärning kan du genväg till träningsprocessen.
Träningsprocess
API:et för bildklassificering startar träningsprocessen genom att läsa in en förtränad TensorFlow-modell. Träningsprocessen består av två steg:
- Flaskhalsfas
- Träningsfas
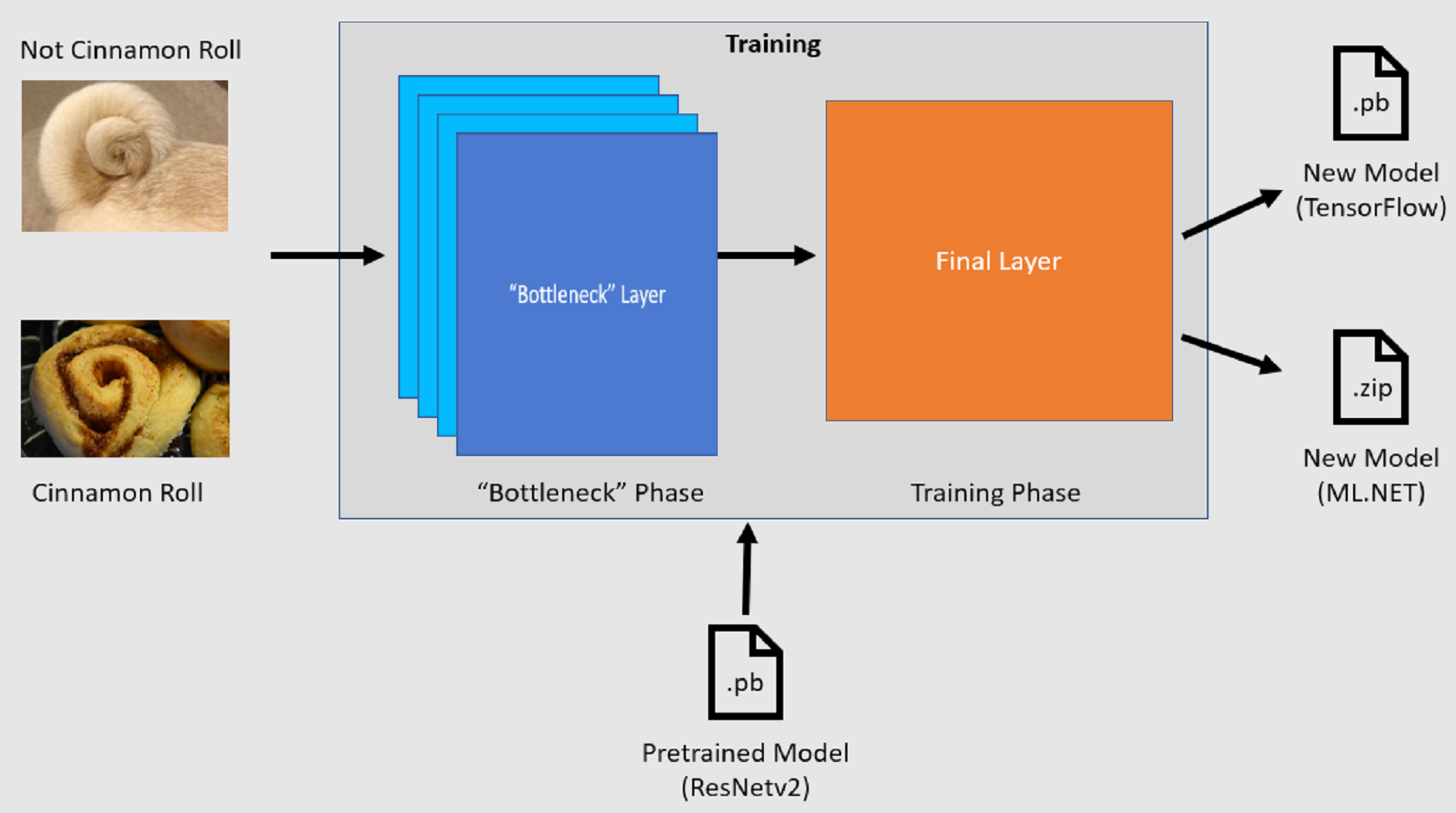
Flaskhalsfas
Under flaskhalsfasen läses uppsättningen träningsbilder in och pixelvärdena används som indata eller funktioner för de frysta lagren i den förtränad modellen. De frusna lagren innehåller alla lager i det neurala nätverket upp till det näst sista lagret, som informellt kallas flaskhalsskiktet. Dessa skikt kallas låsta eftersom ingen träning sker på dessa lager och åtgärderna är genomströmning. Det är i de här frusna lagren där mönster på lägre nivå som hjälper en modell att skilja mellan de olika klasserna beräknas. Ju större antal lager, desto mer beräkningsintensivt är det här steget. Eftersom det här är en engångsberäkning kan resultatet cachelagras och användas i senare körningar när du experimenterar med olika parametrar.
Träningsfas
När utdatavärdena från flaskhalsfasen har beräknats används de som indata för att träna om modellens sista lager. Den här processen är iterativ och körs för det antal gånger som anges av modellparametrar. Under varje körning utvärderas förlust och noggrannhet. Därefter görs lämpliga justeringar för att förbättra modellen med målet att minimera förlusten och maximera noggrannheten. När träningen är klar matas två modellformat ut. En av dem är .pb versionen av modellen och den andra är den .zip ML.NET serialiserade versionen av modellen. När du arbetar i miljöer som stöds av ML.NET rekommenderar vi att du använder .zip modellens version. Men i miljöer där ML.NET inte stöds kan du välja att .pb använda versionen.
Förstå den förtränad modellen
Den förtränade modellen som används i den här självstudien är varianten på 101 lager av modellen Residual Network (ResNet) v2. Den ursprungliga modellen tränas att klassificera bilder i tusen kategorier. Modellen tar som indata en bild med storleken 224 x 224 och matar ut klassannolikheterna för var och en av de klasser som den tränas på. En del av den här modellen används för att träna en ny modell med hjälp av anpassade bilder för att göra förutsägelser mellan två klasser.
Skapa konsolprogram
Nu när du har en allmän förståelse för överföringsinlärning och API:et för bildklassificering är det dags att skapa programmet.
Skapa ett C# -konsolprogram med namnet "DeepLearning_ImageClassification_Binary". Klicka på knappen Nästa.
Välj .NET 6 som ramverk att använda. Klicka på knappen Skapa.
Installera Microsoft.ML NuGet-paketet:
Anteckning
I det här exemplet används den senaste stabila versionen av De NuGet-paket som nämns om inget annat anges.
- I Solution Explorer högerklickar du på projektet och väljer Hantera NuGet-paket.
- Välj "nuget.org" som paketkälla.
- Välj fliken Bläddra.
- Markera kryssrutan Inkludera förhandsversion .
- Sök efter Microsoft.ML.
- Välj knappen Installera .
- Välj knappen OK i dialogrutan Förhandsgranska ändringar och välj sedan knappen Jag accepterar i dialogrutan Godkännande av licens om du godkänner licensvillkoren för de paket som anges.
- Upprepa de här stegen för NuGet-paketen Microsoft.ML.Vision, SciSharp.TensorFlow.Redist version 2.3.1 och Microsoft.ML.ImageAnalytics .
Förbereda och förstå data
Anteckning
Datauppsättningarna för den här självstudien kommer från Maguire, Marc; Dorafshan, Sattar; och Thomas, Robert J., "SDNET2018: A concrete crack image dataset for machine learning applications" (2018). Bläddra bland alla datauppsättningar. Papper 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 är en bilddatamängd som innehåller anteckningar för spruckna och icke-spruckna betongstrukturer (brodäck, väggar och trottoarer).

Data är ordnade i tre underkataloger:
- D innehåller bryggdäcksbilder
- P innehåller trottoarbilder
- W innehåller väggbilder
Var och en av dessa underkataloger innehåller ytterligare två prefixunderkataloger:
- C är det prefix som används för spruckna ytor
- U är det prefix som används för obeackade ytor
I den här självstudien används endast bryggdäcksbilder.
- Ladda ned datauppsättningen och packa upp.
- Skapa en katalog med namnet "assets" i projektet för att spara datamängdsfilerna.
- Kopiera CD- och UD-underkatalogerna från den nyligen uppackade katalogen till katalogen assets.
Skapa indata- och utdataklasser
Öppna filen Program.cs och ersätt de befintliga
using-instruktionerna överst i filen med följande:using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision;ProgramUnder klassen i Program.cs skapar du en klass med namnetImageData. Den här klassen används för att representera initialt inlästa data.class ImageData { public string ImagePath { get; set; } public string Label { get; set; } }ImageDatainnehåller följande egenskaper:ImagePathär den fullständigt kvalificerade sökvägen där avbildningen lagras.Labelär den kategori som bilden tillhör. Det här är det värde som ska förutsägas.
Skapa klasser för dina indata och utdata
ImageDataUnder klassen definierar du schemat för dina indata i en ny klass med namnetModelInput.class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } }ModelInputinnehåller följande egenskaper:Imageär bildensbyte[]representation. Modellen förväntar sig att bilddata ska vara av den här typen för träning.LabelAsKeyär den numeriska representationen avLabel.ImagePathär den fullständigt kvalificerade sökvägen där avbildningen lagras.Labelär den kategori som bilden tillhör. Det här är det värde som ska förutsägas.
Endast
ImageochLabelAsKeyanvänds för att träna modellen och göra förutsägelser. EgenskapernaImagePathochLabelbehålls för att underlätta åtkomsten till det ursprungliga bildfilnamnet och -kategorin.ModelInputUnder klassen definierar du sedan schemat för dina utdata i en ny klass med namnetModelOutput.class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } }ModelOutputinnehåller följande egenskaper:ImagePathär den fullständigt kvalificerade sökvägen där avbildningen lagras.Labelär den ursprungliga kategorin som bilden tillhör. Det här är det värde som ska förutsägas.PredictedLabelär det värde som förutsägs av modellen.
ModelInputPå liknande sätt krävs baraPredictedLabelför att göra förutsägelser eftersom den innehåller den förutsägelse som gjorts av modellen. EgenskapernaImagePathochLabelbehålls för att underlätta åtkomsten till det ursprungliga bildfilnamnet och -kategorin.
Skapa arbetsytekatalog
När tränings- och valideringsdata inte ändras ofta är det bra att cachelagras de beräknade flaskhalsvärdena för ytterligare körningar.
- I projektet skapar du en ny katalog med namnet workspace för att lagra de beräknade flaskhalsvärdena och
.pbversionen av modellen.
Definiera sökvägar och initiera variabler
Under using-instruktionerna definierar du platsen för dina tillgångar, beräknade flaskhalsvärden och
.pbmodellens version.var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets");Initiera variabeln
mlContextmed en ny instans av MLContext.MLContext mlContext = new MLContext();MLContext-klassen är en startpunkt för alla ML.NET åtgärder, och när mlContext initieras skapas en ny ML.NET miljö som kan delas mellan arbetsflödesobjekten för modellskapande. Det liknar begreppsmässigt
DbContexti Entity Framework.
Läsa in data
Skapa datainläsningsverktygsmetod
Bilderna lagras i två underkataloger. Innan data läses in måste de formateras i en lista med ImageData objekt. Skapa metoden för att göra det LoadImagesFromDirectory .
IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
}
LoadImagesFromDirectoryI lägger du till följande kod för att hämta alla filsökvägar från underkatalogerna:var files = Directory.GetFiles(folder, "*", searchOption: SearchOption.AllDirectories);Iterera sedan igenom var och en av filerna med hjälp av en
foreach-instruktion.foreach (var file in files) { }Kontrollera att filnamnstilläggen stöds i -instruktionen
foreach. API:et för bildklassificering stöder JPEG- och PNG-format.if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png")) continue;Hämta sedan filens etikett. Om parametern
useFolderNameAsLabelär inställdtruepå används den överordnade katalogen där filen sparas som etikett. Annars förväntar den sig att etiketten ska vara ett prefix för filnamnet eller själva filnamnet.var label = Path.GetFileName(file); if (useFolderNameAsLabel) label = Directory.GetParent(file).Name; else { for (int index = 0; index < label.Length; index++) { if (!char.IsLetter(label[index])) { label = label.Substring(0, index); break; } } }Skapa slutligen en ny instans av
ModelInput.yield return new ImageData() { ImagePath = file, Label = label };
Förbereda data
LoadImagesFromDirectoryAnropa verktygsmetoden för att hämta listan över bilder som används för träning efter att variabeln har initieratsmlContext.IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);Läs sedan in bilderna i en
IDataViewmed hjälp avLoadFromEnumerablemetoden .IDataView imageData = mlContext.Data.LoadFromEnumerable(images);Data läses in i den ordning de lästes från katalogerna. Du balanserar data genom att blanda dem med hjälp av
ShuffleRowsmetoden .IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);Maskininlärningsmodeller förväntar sig att indata ska vara i numeriskt format. Därför måste viss förbearbetning göras på data före träningen. Skapa en
EstimatorChainsom består avMapValueToKeytransformeringar ochLoadRawImageBytes. TransformeringenMapValueToKeytar det kategoriska värdet iLabelkolumnen, konverterar det till ett numerisktKeyTypevärde och lagrar det i en ny kolumn med namnetLabelAsKey.LoadImagestar värdena frånImagePathkolumnen tillsammans med parameternimageFolderför att läsa in bilder för träning.var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes( outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath"));FitAnvänd metoden för att tillämpa data påpreprocessingPipelineEstimatorChainföljt avTransformmetoden , som returnerar enIDataViewsom innehåller förbearbetade data.IDataView preProcessedData = preprocessingPipeline .Fit(shuffledData) .Transform(shuffledData);För att träna en modell är det viktigt att ha en träningsdatauppsättning samt en valideringsdatauppsättning. Modellen tränas på träningsuppsättningen. Hur bra den gör förutsägelser på osedda data mäts av prestandan mot valideringsuppsättningen. Baserat på resultatet av den prestandan gör modellen justeringar i vad den har lärt sig i ett försök att förbättra. Valideringsuppsättningen kan antingen komma från att dela upp den ursprungliga datauppsättningen eller från en annan källa som redan har avsatts för detta ändamål. I det här fallet delas den förbearbetade datamängden upp i tränings-, validerings- och testuppsättningar.
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);Kodexemplet ovan utför två delningar. Först delas förbearbetade data och 70 % används för träning medan de återstående 30 % används för validering. Sedan delas verifieringsuppsättningen på 30 % upp i validerings- och testuppsättningar där 90 % används för validering och 10 % används för testning.
Ett sätt att tänka på syftet med dessa datapartitioner är att göra en undersökning. När du studerar för ett prov granskar du dina anteckningar, böcker eller andra resurser för att få en uppfattning om de begrepp som finns på provet. Det här är vad tåguppsättningen är till för. Sedan kan du göra en simulerad examen för att verifiera dina kunskaper. Det är här valideringsuppsättningen är praktisk. Du vill kontrollera om du har ett bra grepp om begreppen innan du tar det faktiska provet. Baserat på dessa resultat noterar du vad du har fel eller inte förstod väl och införlivar dina ändringar när du granskar för det verkliga provet. Slutligen tar du provet. Det här är vad testuppsättningen används för. Du har aldrig sett de frågor som finns på provet och använder nu det du har lärt dig från träning och validering för att tillämpa dina kunskaper på den aktuella uppgiften.
Tilldela partitionerna sina respektive värden för tränings-, validerings- och testdata.
IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = validationTestSplit.TrainSet; IDataView testSet = validationTestSplit.TestSet;
Definiera träningspipelinen
Modellträning består av ett par steg. Först används API för bildklassificering för att träna modellen. Sedan konverteras de kodade etiketterna PredictedLabel i kolumnen tillbaka till sitt ursprungliga kategoriska värde med transformeringen MapKeyToValue .
Skapa en ny variabel för att lagra en uppsättning obligatoriska och valfria parametrar för en ImageClassificationTrainer.
var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true };En ImageClassificationTrainer tar flera valfria parametrar:
FeatureColumnNameär den kolumn som används som indata för modellen.LabelColumnNameär kolumnen för det värde som ska förutsägas.ValidationSetär denIDataViewsom innehåller valideringsdata.Archdefinierar vilken av de förtränad modellarkitekturer som ska användas. I den här självstudien används varianten på 101 lager av ResNetv2-modellen.MetricsCallbackbinder en funktion för att spåra förloppet under träningen.TestOnTrainSetinstruerar modellen att mäta prestanda mot träningsuppsättningen när det inte finns någon verifieringsuppsättning.ReuseTrainSetBottleneckCachedValuestalar om för modellen om de cachelagrade värdena ska användas från flaskhalsfasen i efterföljande körningar. Flaskhalsfasen är en engångsberäkning som är beräkningsintensiv första gången den utförs. Om träningsdata inte ändras och du vill experimentera med ett annat antal epoker eller batchstorlekar minskar användningen av de cachelagrade värdena avsevärt den tid som krävs för att träna en modell.ReuseValidationSetBottleneckCachedValuesliknarReuseTrainSetBottleneckCachedValuesbara det som i det här fallet är för datauppsättningen för validering.WorkspacePathdefinierar katalogen där värdena för den beräknade flaskhalsen och.pbversionen av modellen ska lagras.
Definiera träningspipelinen
EstimatorChainsom består av bådemapLabelEstimatoroch ImageClassificationTrainer.var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));FitAnvänd metoden för att träna din modell.ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Använda modellen
Nu när du har tränat din modell är det dags att använda den för att klassificera bilder.
Skapa en ny verktygsmetod med namnet OutputPrediction för att visa förutsägelseinformation i -konsolen.
private static void OutputPrediction(ModelOutput prediction)
{
string imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Klassificera en enskild bild
Skapa en ny metod med namnet
ClassifySingleImageför att göra och mata ut en enda bildförutsägelse.void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Skapa en
PredictionEngineinutiClassifySingleImagemetoden .PredictionEngineär ett bekvämlighets-API som gör att du kan skicka in och sedan utföra en förutsägelse på en enda instans av data.PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);Om du vill komma åt en enda
ModelInputinstans konverterarIDataViewdatadu till enIEnumerablemed hjälp avCreateEnumerablemetoden och får sedan den första observationen.ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data,reuseRowObject:true).First();PredictAnvänd metoden för att klassificera bilden.ModelOutput prediction = predictionEngine.Predict(image);Mata ut förutsägelsen till konsolen med
OutputPredictionmetoden .Console.WriteLine("Classifying single image"); OutputPrediction(prediction);Anropa
ClassifySingleImagenedan och anropaFitmetoden med hjälp av testuppsättningen med bilder.ClassifySingleImage(mlContext, testSet, trainedModel);
Klassificera flera bilder
Lägg till en ny metod med namnet
ClassifyImagesunderClassifySingleImagemetoden för att göra och mata ut flera bildförutsägelser.void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Skapa en
IDataViewsom innehåller förutsägelsernaTransformmed hjälp av metoden . Lägg till följande kod iClassifyImagesmetoden .IDataView predictionData = trainedModel.Transform(data);För att iterera över förutsägelserna konverterar
predictionDataIDataViewdu till enIEnumerablemed hjälp avCreateEnumerablemetoden och får sedan de första 10 observationerna.IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10);Iterera och mata ut de ursprungliga och förutsagda etiketterna för förutsägelserna.
Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); }Anropa slutligen
ClassifyImagesunderClassifySingleImage()metoden med hjälp av testuppsättningen med bilder.ClassifyImages(mlContext, testSet, trainedModel);
Kör programmet
Kör konsolappen. Utdata bör likna dem nedan. Du kan se varningar eller bearbeta meddelanden, men dessa meddelanden har tagits bort från följande resultat för tydlighetens skull. Av utrymmesskäl har utdata kondenserats.
Flaskhalsfas
Inget värde skrivs ut för bildnamnet eftersom bilderna läses in som ett byte[] och därför finns det inget bildnamn att visa.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Träningsfas
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Klassificera bilders utdata
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Vid inspektion av 7001-220.jpg bild, kan du se att det i själva verket inte är sprucken.

Grattis! Nu har du skapat en djupinlärningsmodell för att klassificera bilder.
Förbättra modellen
Om du inte är nöjd med resultatet av din modell kan du försöka förbättra dess prestanda genom att prova några av följande metoder:
- Mer data: Ju fler exempel en modell lär sig av, desto bättre presterar den. Ladda ned den fullständiga SDNET2018-datauppsättningen och använd den för att träna.
- Utöka data: En vanlig teknik för att lägga till variation i data är att utöka data genom att ta en bild och tillämpa olika transformeringar (rotera, vända, skifta, beskära). Detta lägger till mer varierande exempel som modellen kan lära sig av.
- Träna under en längre tid: Ju längre du tränar, desto mer finjusterad blir modellen. Om du ökar antalet epoker kan modellens prestanda förbättras.
- Experimentera med hyperparametrarna: Förutom de parametrar som används i den här självstudien kan andra parametrar justeras för att förbättra prestandan. Om du ändrar inlärningstakten, vilket avgör storleken på uppdateringar som görs i modellen efter varje epok, kan prestandan förbättras.
- Använd en annan modellarkitektur: Beroende på hur dina data ser ut kan den modell som bäst kan lära sig dess funktioner skilja sig åt. Om du inte är nöjd med modellens prestanda kan du prova att ändra arkitekturen.
Nästa steg
I den här självstudien har du lärt dig hur du skapar en anpassad djupinlärningsmodell med hjälp av överföringsinlärning, en förtränad TensorFlow-modell för bildklassificering och api:et för ML.NET bildklassificering för att klassificera bilder av betongytor som spruckna eller obeackade.
Gå vidare till nästa självstudie om du vill veta mer.