Vad är Model Builder och hur fungerar det?
ML.NET Model Builder är ett intuitivt grafiskt Visual Studio-tillägg för att skapa, träna och distribuera anpassade maskininlärningsmodeller. Den använder automatisk maskininlärning (AutoML) för att utforska olika maskininlärningsalgoritmer och inställningar som hjälper dig att hitta den som passar bäst för ditt scenario.
Du behöver inte maskininlärningsexpertis för att använda Model Builder. Allt du behöver är vissa data och ett problem att lösa. Model Builder genererar koden för att lägga till modellen i .NET-programmet.

Skapa ett Model Builder-projekt
När du först startar Model Builder uppmanas du att namnge projektet och skapar sedan en mbconfig konfigurationsfil i projektet. Filen mbconfig håller reda på allt du gör i Model Builder så att du kan öppna sessionen igen.
Efter träningen genereras tre filer under filen *.mbconfig:
- Model.consumption.cs: Den här filen innehåller scheman
ModelInputochModelOutputsamt denPredictfunktion som genereras för att använda modellen. - Model.training.cs: Den här filen innehåller träningspipelinen (datatransformeringar, algoritmer, algoritmhyperparametrar) som valts av Model Builder för att träna modellen. Du kan använda den här pipelinen för att träna om din modell.
- Model.zip: Det här är en serialiserad zip-fil som representerar din tränade ML.NET modell.
När du skapar mbconfig filen uppmanas du att ange ett namn. Det här namnet tillämpas på förbruknings-, tränings- och modellfilerna. I det här fallet är det namn som används modell.
Scenario
Du kan använda många olika scenarier i Model Builder för att generera en maskininlärningsmodell för ditt program.
Ett scenario är en beskrivning av vilken typ av förutsägelse du vill göra med hjälp av dina data. Till exempel:
- Förutsäga framtida produktförsäljningsvolym baserat på historiska försäljningsdata.
- Klassificera sentiment som positiva eller negativa baserat på kundrecensioner.
- Identifiera om en banktransaktion är bedräglig.
- Dirigera problem med kundfeedback till rätt team i ditt företag.
Varje scenario mappar till en annan maskininlärningsuppgift, som omfattar:
| Uppgift | Scenario |
|---|---|
| Binär klassificering | Dartaklassificering |
| Klassificering med flera klasser | Dartaklassificering |
| Bildklassificering | Bildklassificering |
| Textklassificering | Textklassificering |
| Regression | Värdeförutsägelse |
| Rekommendation | Rekommendation |
| Prognostisering | Prognostisering |
Scenariot med att klassificera sentiment som positiva eller negativa skulle till exempel omfattas av den binära klassificeringsaktiviteten.
Mer information om de olika ML-uppgifter som stöds av ML.NET finns i Maskininlärningsuppgifter i ML.NET.
Vilket maskininlärningsscenario passar mig bra?
I Model Builder måste du välja ett scenario. Typen av scenario beror på vilken typ av förutsägelse du försöker göra.
Tabell
Dartaklassificering
Klassificering används för att kategorisera data i kategorier.
Exempel på indata
Exempelutdata
| SepalLength | SepalWidth | Längd på kronblad | Kronbladsbredd | Arter |
|---|---|---|---|---|
| 5,1 | 3.5 | 1.4 | 0.2 | setosa |
| Förutsagda arter |
|---|
| setosa |
Värdeförutsägelse
Värdeförutsägelse, som faller under regressionsaktiviteten, används för att förutsäga tal.
Exempel på indata
Exempelutdata
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3,8 | CRD | 17.5 |
| Förutsagt pris |
|---|
| 4,5 |
Rekommendation
Rekommendationsscenariot förutsäger en lista över föreslagna objekt för en viss användare, baserat på hur lika deras gilla-markeringar och ogillanden är för andra användare.
Du kan använda rekommendationsscenariot när du har en uppsättning användare och en uppsättning "produkter", till exempel artiklar att köpa, filmer, böcker eller TV-program, tillsammans med en uppsättning användares "betyg" av dessa produkter.
Exempel på indata
Exempelutdata
| AnvändarID | Produkt-ID | Klassificering |
|---|---|---|
| 1 | 2 | 4.2 |
| Förutsagt omdöme |
|---|
| 4,5 |
Prognostisering
Prognosscenariot använder historiska data med en tidsserie eller säsongskomponent till den.
Du kan använda prognosscenariot för att prognostisera efterfrågan eller försäljning för en produkt.
Exempel på indata
Exempelutdata
| Datum | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| 3 dagars prognos |
|---|
| [1000,1001,1002] |
Visuellt innehåll
Bildklassificering
Bildklassificering används för att identifiera bilder av olika kategorier. Till exempel olika typer av terräng eller djur eller tillverkningsfel.
Du kan använda bildklassificeringsscenariot om du har en uppsättning bilder och vill klassificera bilderna i olika kategorier.
Exempel på indata
Exempelutdata

| Förutsagd etikett |
|---|
| Hund |
Objektidentifiering
Objektidentifiering används för att hitta och kategorisera entiteter i bilder. Till exempel att hitta och identifiera bilar och personer i en bild.
Du kan använda objektidentifiering när bilder innehåller flera objekt av olika typer.
Exempel på indata
Exempelutdata

Bearbetning av naturligt språk
Textklassificering
Textklassificering kategoriserar råa textindata.
Du kan använda textklassificeringsscenariot om du har en uppsättning dokument eller kommentarer och vill klassificera dem i olika kategorier.
Exempel på indata
Exempel på utdata
| Granskning |
|---|
| Jag gillar verkligen den här biffen! |
| Sentiment |
|---|
| Positiv |
Environment
Du kan träna din maskininlärningsmodell lokalt på din dator eller i molnet på Azure, beroende på scenariot.
När du tränar lokalt arbetar du inom begränsningarna för dina datorresurser (CPU, minne och disk). När du tränar i molnet kan du skala upp dina resurser för att uppfylla kraven i ditt scenario, särskilt för stora datamängder.
| Scenario | Lokal PROCESSOR | Lokal GPU | Azure |
|---|---|---|---|
| Dartaklassificering | ✔️ | ❌ | ❌ |
| Värdeförutsägelse | ✔️ | ❌ | ❌ |
| Rekommendation | ✔️ | ❌ | ❌ |
| Prognostisering | ✔️ | ❌ | ❌ |
| Bildklassificering | ✔️ | ✔️ | ✔️ |
| Objektidentifiering | ❌ | ❌ | ✔️ |
| Textklassificering | ✔️ | ✔️ | ❌ |
Data
När du har valt ditt scenario ber Model Builder dig att ange en datauppsättning. Data används för att träna, utvärdera och välja den bästa modellen för ditt scenario.
Model Builder stöder datauppsättningar i .tsv-, .csv-, .txt- och SQL-databasformat. Om du har en .txt fil ska kolumnerna avgränsas med ,, ;eller \t.
Om datauppsättningen består av bilder är .jpg de filtyper som stöds och .png.
Mer information finns i Läsa in träningsdata i Model Builder.
Välj de utdata som ska förutsägas (etikett)
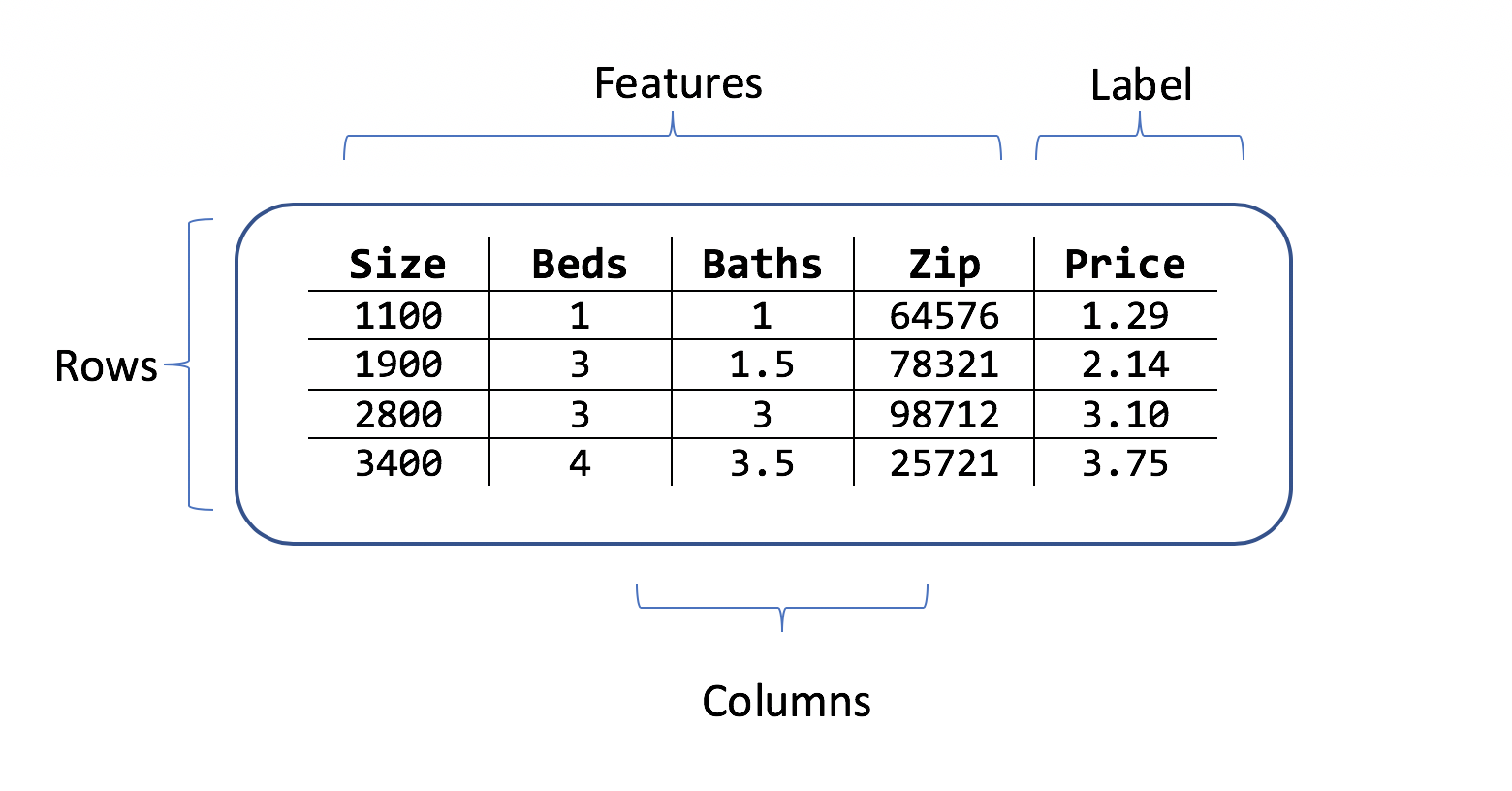
En datauppsättning är en tabell med rader med träningsexempel och kolumner med attribut. Varje rad har:
- en etikett (attributet som du vill förutsäga)
- funktioner (attribut som används som indata för att förutsäga etiketten)
För scenariot med förutsägelse av huspris kan funktionerna vara:
- Kvadratbilderna av huset.
- Antalet sovrum och badrum.
- Postnumret.
Etiketten är det historiska huspriset för den raden med kvadratmeter, sovrum och badrumsvärden och postnummer.
Exempeldatauppsättningar
Om du inte har egna data ännu kan du prova någon av dessa datauppsättningar:
| Scenario | Exempel | Data | Etikett | Funktioner |
|---|---|---|---|---|
| Klassificering | Förutsäga försäljningsavvikelser | produktförsäljningsdata | Produktförsäljning | Månad |
| Förutsäga attityd för webbplatskommenteringar | webbplatskommentardata | Etikett (1 när negativ attityd, 0 när den är positiv) | Kommentar, år | |
| Förutsäga bedrägliga kreditkortstransaktioner | kreditkortsdata | Klass (1 när bedrägligt, 0 annars) | Amount, V1-V28 (anonymiserade funktioner) | |
| Förutsäga typen av problem på en GitHub-lagringsplats | GitHub-problemdata | Ytdiagram | Rubrik, beskrivning | |
| Värdeförutsägelse | Förutsäga priset för taxipriser | taxi fare data | Biljettpris | Restid, avstånd |
| Bildklassificering | Förutsäga kategorin för en blomma | blombilder | Typ av blomma: tusensköna, maskros, rosor, solrosor, tulpaner | Själva bilddata |
| Rekommendation | Förutsäga filmer som någon kommer att gilla | filmklassificeringar | Användare, filmer | Bedömningar |
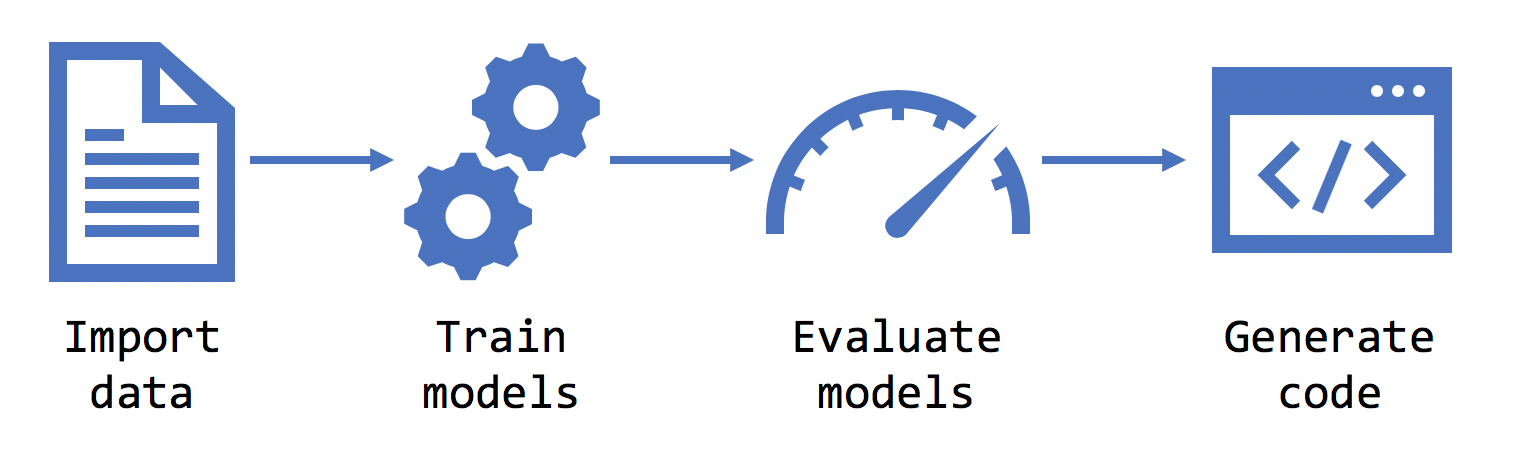
Utbilda
När du har valt scenario, miljö, data och etikett tränar Model Builder modellen.
Vad är träning?
Träning är en automatisk process där Model Builder lär din modell hur du besvarar frågor för ditt scenario. När modellen har tränats kan den göra förutsägelser med indata som den inte har sett tidigare. Om du till exempel förutspår huspriser och ett nytt hus kommer ut på marknaden kan du förutsäga försäljningspriset.
Eftersom Model Builder använder automatisk maskininlärning (AutoML) kräver det inga indata eller justering från dig under träningen.
Hur länge ska jag träna?
Model Builder använder AutoML för att utforska flera modeller för att hitta den modell som fungerar bäst.
Med längre träningsperioder kan AutoML utforska fler modeller med ett bredare utbud av inställningar.
Tabellen nedan sammanfattar den genomsnittliga tid det tar att få bra prestanda för en uppsättning exempeldatauppsättningar på en lokal dator.
| Datamängdens storlek | Genomsnittlig tid att träna |
|---|---|
| 0–10 MB | 10 sek |
| 10–100 MB | 10 min |
| 100–500 MB | 30 min |
| 500–1 GB | 60 min |
| 1 GB+ | 3+ timmar |
Dessa siffror är endast en guide. Den exakta längden på träningen är beroende av:
- Antalet funktioner (kolumner) som används som indata till modellen.
- Typ av kolumner.
- ML-aktiviteten.
- Processor-, disk- och minnesprestanda för den dator som används för träning.
Det rekommenderas vanligtvis att du använder mer än 100 rader som datauppsättningar med mindre än så kanske inte ger några resultat.
Utvärdera
Utvärdering är en process för att mäta hur bra din modell är. Model Builder använder den tränade modellen för att göra förutsägelser med nya testdata och mäter sedan hur bra förutsägelserna är.
Model Builder delar upp träningsdata i en träningsuppsättning och en testuppsättning. Träningsdata (80 %) används för att träna din modell och testdata (20 %) hålls tillbaka för att utvärdera din modell.
Hur gör jag för att förstå min modellprestanda?
Ett scenario mappar till en maskininlärningsuppgift. Varje ML-uppgift har en egen uppsättning utvärderingsmått.
Värdeförutsägelse
Standardmåttet för problem med värdeförutsägelse är RSquared, värdet för RSquared-intervall mellan 0 och 1. 1 är det bästa möjliga värdet eller med andra ord desto närmare RSquared till 1 desto bättre fungerar din modell.
Andra mått som rapporteras som absolut förlust, kvadratförlust och RMS-förlust är ytterligare mått, som kan användas för att förstå hur din modell presterar och jämföra den med andra modeller för värdeförutsägelse.
Klassificering (2 kategorier)
Standardmåttet för klassificeringsproblem är noggrannhet. Noggrannhet definierar andelen korrekta förutsägelser som din modell gör över testdatauppsättningen. Ju närmare 100% eller 1,0 desto bättre är det.
Andra mått som rapporteras, till exempel AUC (område under kurvan), som mäter den sanna positiva frekvensen jämfört med den falska positiva frekvensen bör vara större än 0,50 för att modeller ska vara acceptabla.
Ytterligare mått som F1-poäng kan användas för att styra balansen mellan Precision och Recall.
Klassificering (3+ kategorier)
Standardmåttet för klassificering av flera klasser är Mikronoggrannhet. Ju närmare mikronoggrannheten är 100 % eller 1,0 desto bättre är den.
Ett annat viktigt mått för klassificering med flera klasser är makronoggrannhet, ungefär som mikronoggrannhet ju närmare 1,0 desto bättre är det. Ett bra sätt att tänka på dessa två typer av noggrannhet är:
- Mikronoggrannhet: Hur ofta klassificeras en inkommande biljett till rätt team?
- Makronoggrannhet: För ett genomsnittligt team, hur ofta är en inkommande biljett korrekt för deras team?
Mer information om utvärderingsmått
Mer information finns i mått för modellutvärdering.
Förbättra
Om modellens prestandapoäng inte är så bra som du vill att den ska vara kan du:
Träna under en längre tid. Med mer tid experimenterar den automatiserade maskininlärningsmotorn med fler algoritmer och inställningar.
Lägg till mer data. Ibland räcker inte mängden data för att träna en maskininlärningsmodell av hög kvalitet. Detta gäller särskilt för datauppsättningar som har ett litet antal exempel.
Balansera dina data. För klassificeringsuppgifter kontrollerar du att träningsuppsättningen är balanserad mellan kategorierna. Om du till exempel har fyra klasser för 100 träningsexempel och de två första klasserna (tag1 och tag2) används för 90 poster, men de andra två (tag3 och tag4) endast används på de återstående 10 posterna, kan bristen på balanserade data göra att din modell har svårt att förutsäga tagg3 eller tagg4 korrekt.
Förbruka
Efter utvärderingsfasen matar Model Builder ut en modellfil och kod som du kan använda för att lägga till modellen i ditt program. ML.NET modeller sparas som en zip-fil. Koden för att läsa in och använda din modell läggs till som ett nytt projekt i din lösning. Model Builder lägger också till en exempelkonsolapp som du kan köra för att se din modell i praktiken.
Dessutom ger Model Builder dig möjlighet att skapa projekt som använder din modell. För närvarande skapar Model Builder följande projekt:
- Konsolapp: Skapar ett .NET-konsolprogram för att göra förutsägelser från din modell.
- Webb-API: Skapar ett ASP.NET Core-webb-API som gör att du kan använda din modell via Internet.
Vad händer härnäst?
Installera Tillägget Model Builder Visual Studio.