Arbeta med data i ASP.NET Core Apps
Dricks
Det här innehållet är ett utdrag från eBook, Architect Modern Web Applications med ASP.NET Core och Azure, som finns på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

"Data är en värdefull sak och kommer att vara längre än själva systemen."
Tim Berners-Lee
Dataåtkomst är en viktig del av nästan alla program. ASP.NET Core har stöd för olika alternativ för dataåtkomst, inklusive Entity Framework Core (och Entity Framework 6) och kan fungera med alla .NET-dataåtkomstramverk. Valet av vilket dataåtkomstramverk som ska användas beror på programmets behov. Genom att abstrahera dessa val från ApplicationCore- och UI-projekten och kapsla in implementeringsinformation i infrastruktur kan du skapa löst kopplade och testbara program.
Entity Framework Core (för relationsdatabaser)
Om du skriver ett nytt ASP.NET Core-program som behöver arbeta med relationsdata är Entity Framework Core (EF Core) det rekommenderade sättet för ditt program att komma åt sina data. EF Core är en objektrelationsmappare (O/RM) som gör det möjligt för .NET-utvecklare att bevara objekt till och från en datakälla. Det eliminerar behovet för de flesta dataåtkomstkodutvecklare skulle vanligtvis behöva skriva. Precis som ASP.NET Core har EF Core skrivits om från grunden för att stödja modulära plattformsoberoende program. Du lägger till det i ditt program som ett NuGet-paket, konfigurerar det under appstarten och begär det via beroendeinmatning där du behöver det.
Om du vill använda EF Core med en SQL Server-databas kör du följande dotnet CLI-kommando:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Så här lägger du till stöd för en InMemory-datakälla för testning:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
The DbContext
För att arbeta med EF Core behöver du en underklass på DbContext. Den här klassen innehåller egenskaper som representerar samlingar av de entiteter som ditt program kommer att arbeta med. Exemplet eShopOnWeb innehåller en CatalogContext med samlingar för objekt, varumärken och typer:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext måste ha en konstruktor som accepterar DbContextOptions och skickar det här argumentet till baskonstruktorn DbContext . Om du bara har en DbContext i ditt program kan du skicka en instans av DbContextOptions, men om du har fler än en måste du använda den allmänna DbContextOptions<T> typen och skicka in din DbContext-typ som allmän parameter.
Konfigurera EF Core
I ditt ASP.NET Core-program konfigurerar du vanligtvis EF Core i Program.cs med programmets andra beroenden. EF Core använder en DbContextOptionsBuilder, som stöder flera användbara tilläggsmetoder för att effektivisera konfigurationen. Om du vill konfigurera CatalogContext att använda en SQL Server-databas med en anslutningssträng definierad i Konfiguration lägger du till följande kod:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Så här använder du den minnesinterna databasen:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
När du har installerat EF Core, skapat en underordnad DbContext-typ och lagt till typen i programmets tjänster är du redo att använda EF Core. Du kan begära en instans av din DbContext-typ i alla tjänster som behöver den och börja arbeta med dina beständiga entiteter med LINQ som om de bara fanns i en samling. EF Core utför arbetet med att översätta dina LINQ-uttryck till SQL-frågor för att lagra och hämta dina data.
Du kan se de frågor som EF Core kör genom att konfigurera en loggare och se till att dess nivå är inställd på minst Information, enligt bild 8–1.
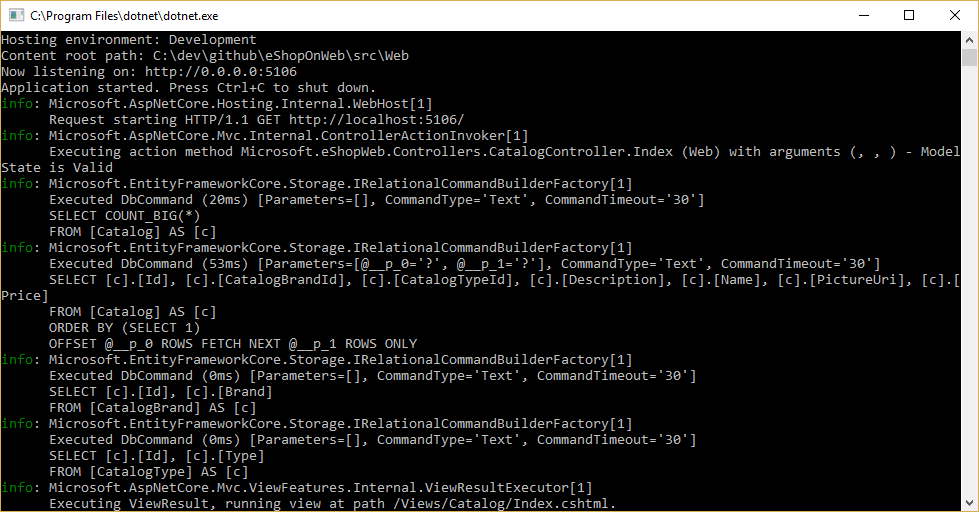
Bild 8-1. Logga EF Core-frågor till konsolen
Hämta och lagra data
Om du vill hämta data från EF Core får du åtkomst till lämplig egenskap och använder LINQ för att filtrera resultatet. Du kan också använda LINQ för att utföra projektion och transformera resultatet från en typ till en annan. Följande exempel hämtar CatalogBrands, sorterade efter namn, filtrerade efter egenskapen Enabled och projiceras på en SelectListItem typ:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
I exemplet ovan är det viktigt att lägga till anropet ToListAsync för att köra frågan omedelbart. Annars tilldelar instruktionen en IQueryable<SelectListItem> till brandItems, som inte körs förrän den räknas upp. Det finns för- och nackdelar med att IQueryable returnera resultat från metoder. Det gör att frågan EF Core kommer att konstrueras ytterligare, men kan också resultera i fel som endast inträffar vid körning, om åtgärder läggs till i frågan som EF Core inte kan översätta. Det är vanligtvis säkrare att skicka filter till metoden som utför dataåtkomsten och returnera en minnesintern samling (till exempel List<T>) som resultat.
EF Core spårar ändringar på entiteter som hämtas från beständighet. Om du vill spara ändringar i en spårad entitet anropar SaveChangesAsync du bara metoden i DbContext och ser till att det är samma DbContext-instans som användes för att hämta entiteten. Att lägga till och ta bort entiteter görs direkt på lämplig DbSet-egenskap, återigen med ett anrop till för att SaveChangesAsync köra databaskommandona. I följande exempel visas hur du lägger till, uppdaterar och tar bort entiteter från beständighet.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core stöder både synkrona och asynkrona metoder för att hämta och spara. I webbprogram rekommenderar vi att du använder mönstret async/await med asynkrona metoder, så att webbservertrådar inte blockeras i väntan på att dataåtkomståtgärderna ska slutföras.
Mer information finns i Buffring och direktuppspelning.
Hämtar relaterade data
När EF Core hämtar entiteter fylls alla egenskaper som lagras direkt med entiteten i databasen. Navigeringsegenskaper, till exempel listor över relaterade entiteter, fylls inte i och deras värde kan vara inställt på null. Den här processen säkerställer att EF Core inte hämtar mer data än vad som behövs, vilket är särskilt viktigt för webbprogram, som snabbt måste bearbeta begäranden och returnera svar på ett effektivt sätt. Om du vill inkludera relationer med en entitet med ivrig inläsning anger du egenskapen med hjälp av metoden Inkludera tillägg i frågan, enligt följande:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Du kan inkludera flera relationer och du kan även inkludera underrelationer med Hjälp av ThenInclude. EF Core kör en enda fråga för att hämta den resulterande uppsättningen entiteter. Alternativt kan du inkludera navigeringsegenskaper för navigeringsegenskaper genom att skicka ett .' -avgränsad sträng till .Include() tilläggsmetoden, så här:
.Include("Items.Products")
Förutom att kapsla in filtreringslogik kan en specifikation ange formen på de data som ska returneras, inklusive vilka egenskaper som ska fyllas i. eShopOnWeb-exemplet innehåller flera specifikationer som visar inkapsling av ivrig inläsningsinformation i specifikationen. Du kan se hur specifikationen används som en del av en fråga här:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Ett annat alternativ för att läsa in relaterade data är att använda explicit inläsning. Med explicit inläsning kan du läsa in ytterligare data till en entitet som redan har hämtats. Eftersom den här metoden omfattar en separat begäran till databasen rekommenderas den inte för webbprogram, vilket bör minimera antalet databasresor som görs per begäran.
Lat inläsning är en funktion som automatiskt läser in relaterade data som det refereras till av programmet. EF Core har lagt till stöd för lat inläsning i version 2.1. Lat inläsning är inte aktiverat som standard och kräver installation av Microsoft.EntityFrameworkCore.Proxies. Precis som med explicit inläsning bör lat inläsning vanligtvis inaktiveras för webbprogram, eftersom dess användning resulterar i att ytterligare databasfrågor görs i varje webbbegäran. Tyvärr går de kostnader som uppstår vid lat inläsning ofta obemärkt vid utvecklingstillfället, när svarstiden är liten och ofta är de datauppsättningar som används för testning små. Men i produktion, med fler användare, mer data och mer svarstid, kan de ytterligare databasbegäranden ofta resultera i dåliga prestanda för webbprogram som använder sig av lata inläsningar.
Undvik lazy loading entiteter i webbprogram
Det är en bra idé att testa ditt program när du undersöker de faktiska databasfrågor som det gör. Under vissa omständigheter kan EF Core göra många fler frågor eller en dyrare fråga än vad som är optimalt för programmet. Ett sådant problem kallas en kartesisk explosion. EF Core-teamet gör metoden AsSplitQuery tillgänglig som ett av flera sätt att finjustera körningsbeteendet.
Kapsla in data
EF Core har stöd för flera funktioner som gör att din modell kan kapsla in dess tillstånd korrekt. Ett vanligt problem i domänmodeller är att de exponerar samlingsnavigeringsegenskaper som offentligt tillgängliga listtyper. Det här problemet gör att alla medarbetare kan ändra innehållet i dessa samlingstyper, vilket kan kringgå viktiga affärsregler som är relaterade till samlingen, vilket möjligen lämnar objektet i ett ogiltigt tillstånd. Lösningen på det här problemet är att exponera skrivskyddad åtkomst till relaterade samlingar och uttryckligen tillhandahålla metoder som definierar hur klienter kan manipulera dem, som i det här exemplet:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Den här entitetstypen exponerar inte en offentlig List egenskap eller ICollection egenskap, utan exponerar i stället en IReadOnlyCollection typ som omsluter den underliggande listtypen. När du använder det här mönstret kan du ange för Entity Framework Core att använda bakgrundsfältet så här:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Ett annat sätt att förbättra din domänmodell är att använda värdeobjekt för typer som saknar identitet och som bara särskiljs av deras egenskaper. Om du använder sådana typer som egenskaper för dina entiteter kan du hålla logiken specifik för det värdeobjekt där det hör hemma och kan undvika duplicerad logik mellan flera entiteter som använder samma koncept. I Entity Framework Core kan du spara värdeobjekt i samma tabell som deras ägande entitet genom att konfigurera typen som en ägd entitet, så här:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
I det här exemplet är egenskapen ShipToAddress av typen Address. Address är ett värdeobjekt med flera egenskaper som Street och City. EF Core mappar Order objektet till tabellen med en kolumn per Address egenskap och prefixar varje kolumnnamn med namnet på egenskapen. I det här exemplet skulle tabellen Order innehålla kolumner som ShipToAddress_Street och ShipToAddress_City. Det går också att lagra ägda typer i separata tabeller, om så önskas.
Läs mer om stöd för ägd entitet i EF Core.
Elastiska anslutningar
Externa resurser som SQL-databaser kan ibland vara otillgängliga. I fall av tillfällig otillgänglighet kan program använda omprövningslogik för att undvika att skapa ett undantag. Den här tekniken kallas ofta för anslutningsåterhämtning. Du kan implementera ditt eget återförsök med exponentiell backoff-teknik genom att försöka försöka igen med en exponentiellt ökande väntetid tills ett maximalt antal återförsök har uppnåtts. Den här tekniken omfattar det faktum att molnresurser tillfälligt kan vara otillgängliga under korta tidsperioder, vilket resulterar i att vissa begäranden misslyckas.
För Azure SQL DB tillhandahåller Entity Framework Core redan intern databasanslutningsåterhämtning och logik för återförsök. Men du måste aktivera Entity Framework-körningsstrategin för varje DbContext-anslutning om du vill ha motståndskraftiga EF Core-anslutningar.
Följande kod på EF Core-anslutningsnivån möjliggör till exempel elastiska SQL-anslutningar som görs om om anslutningen misslyckas.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Körningsstrategier och explicita transaktioner med BeginTransaction och flera DbContexts
När återförsök aktiveras i EF Core-anslutningar blir varje åtgärd som du utför med EF Core en egen återförsöksbar åtgärd. Varje fråga och varje anrop till SaveChangesAsync görs på nytt som en enhet om ett tillfälligt fel inträffar.
Men om koden initierar en transaktion med BeginTransaction definierar du din egen grupp med åtgärder som måste behandlas som en enhet. allt i transaktionen måste återställas om ett fel inträffar. Du ser ett undantag som följande om du försöker köra transaktionen när du använder en EF-körningsstrategi (återförsöksprincip) och du inkluderar flera SaveChangesAsync från flera DbContexts i den.
System.InvalidOperationException: Den konfigurerade körningsstrategin SqlServerRetryingExecutionStrategy stöder inte användarinitierade transaktioner. Använd körningsstrategin som returneras av DbContext.Database.CreateExecutionStrategy() för att köra alla åtgärder i transaktionen som en återförsöksbar enhet.
Lösningen är att manuellt anropa EF-körningsstrategin med ett ombud som representerar allt som behöver köras. Om det inträffar ett tillfälligt fel anropar körningsstrategin delegate igen. Följande kod visar hur du implementerar den här metoden:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
Den första DbContexten _catalogContext är och den andra DbContexten finns i _integrationEventLogService objektet. Slutligen skulle incheckningsåtgärden utföras flera DbContexts och använda en EF-körningsstrategi.
Referenser – Entity Framework Core
- EF Core Docshttps://learn.microsoft.com/ef/
- EF Core: Relaterade datahttps://learn.microsoft.com/ef/core/querying/related-data
- Undvik lazy loading entiteter i ASPNET-programhttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core eller micro-ORM?
Även om EF Core är ett bra val för att hantera beständighet, och för det mesta kapslar in databasinformation från programutvecklare, är det inte det enda valet. Ett annat populärt alternativ med öppen källkod är Dapper, en så kallad mikro-ORM. En mikro-ORM är ett enkelt, mindre komplett verktyg för att mappa objekt till datastrukturer. När det gäller Dapper fokuserar designmålen på prestanda i stället för att helt kapsla in de underliggande frågor som används för att hämta och uppdatera data. Eftersom den inte abstraherar SQL från utvecklaren är Dapper "närmare metallen" och låter utvecklare skriva exakt de frågor som de vill använda för en viss dataåtkomståtgärd.
EF Core har två viktiga funktioner som skiljer den från Dapper men också lägger till prestandakostnaderna. Den första är översättningen från LINQ-uttryck till SQL. Dessa översättningar cachelagras, men det finns även omkostnader för att utföra dem första gången. Den andra är ändringsspårning för entiteter (så att effektiva uppdateringsinstruktioner kan genereras). Det här beteendet kan inaktiveras för specifika frågor med hjälp AsNoTracking av tillägget. EF Core genererar också SQL-frågor som vanligtvis är mycket effektiva och i alla fall helt godtagbara ur prestandasynpunkt, men om du behöver fin kontroll över den exakta frågan som ska köras kan du även skicka in anpassad SQL (eller köra en lagrad procedur) med EF Core. I det här fallet överträffar Dapper fortfarande EF Core, men bara mycket något. Aktuella prestandamåttdata för en mängd olika dataåtkomstmetoder finns på Dapper-webbplatsen.
Om du vill se hur syntaxen för Dapper varierar från EF Core kan du överväga dessa två versioner av samma metod för att hämta en lista med objekt:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Om du behöver skapa mer komplexa objektdiagram med Dapper måste du skriva de associerade frågorna själv (i stället för att lägga till en Inkludera som du skulle göra i EF Core). Den här funktionen stöds via olika syntaxer, inklusive en funktion som kallas multimappning som gör att du kan mappa enskilda rader till flera mappade objekt. Med ett klassinlägg med en egenskapsägare av typen Användare returnerar till exempel följande SQL alla nödvändiga data:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Varje returnerad rad innehåller både användar- och postdata. Eftersom användardata ska kopplas till Post-data via egenskapen Ägare används följande funktion:
(post, user) => { post.Owner = user; return post; }
Den fullständiga kodlistan för att returnera en samling inlägg med egenskapen Ägare ifylld med associerade användardata är:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Eftersom det ger mindre inkapsling kräver Dapper att utvecklare vet mer om hur deras data lagras, hur de frågar effektivt och skriver mer kod för att hämta dem. När modellen ändras, i stället för att bara skapa en ny migrering (en annan EF Core-funktion) och/eller uppdatera mappningsinformation på en plats i en DbContext, måste varje fråga som påverkas uppdateras. Dessa frågor har inga kompileringstidsgarantier, så de kan brytas vid körning som svar på ändringar i modellen eller databasen, vilket gör fel svårare att identifiera snabbt. I utbyte mot dessa kompromisser erbjuder Dapper extremt snabba prestanda.
För de flesta program, och de flesta delar av nästan alla program, erbjuder EF Core acceptabel prestanda. Produktivitetsfördelarna för utvecklare kommer därför sannolikt att uppväga prestandakostnaderna. För frågor som kan dra nytta av cachelagring kan den faktiska frågan bara köras en liten procentandel av tiden, vilket gör att relativt små frågeprestandaskillnader diskuteras.
SQL eller NoSQL
Traditionellt har relationsdatabaser som SQL Server dominerat marknadsplatsen för beständig datalagring, men de är inte den enda tillgängliga lösningen. NoSQL-databaser som MongoDB erbjuder en annan metod för att lagra objekt. I stället för att mappa objekt till tabeller och rader är ett annat alternativ att serialisera hela objektdiagrammet och lagra resultatet. Fördelarna med den här metoden, åtminstone från början, är enkelhet och prestanda. Det är enklare att lagra ett enda serialiserat objekt med en nyckel än att dela upp objektet i många tabeller med relationer och uppdatera rader som kan ha ändrats sedan objektet senast hämtades från databasen. På samma sätt är hämtning och deserialisering av ett enskilt objekt från ett nyckelbaserat arkiv vanligtvis mycket snabbare och enklare än komplexa kopplingar eller flera databasfrågor som krävs för att helt skriva samma objekt från en relationsdatabas. Bristen på lås eller transaktioner eller ett fast schema gör också att NoSQL-databaser kan skalas över många datorer, vilket stöder mycket stora datamängder.
Å andra sidan har NoSQL-databaser (som de vanligtvis kallas) sina nackdelar. Relationsdatabaser använder normalisering för att framtvinga konsekvens och undvika duplicering av data. Den här metoden minskar databasens totala storlek och säkerställer att uppdateringar av delade data är tillgängliga omedelbart i hela databasen. I en relationsdatabas kan en adresstabell referera till en landstabell efter ID, så att om namnet på ett land/en region ändrades skulle adressposterna ha nytta av uppdateringen utan att själva behöva uppdateras. Men i en NoSQL-databas kan adress och dess associerade land serialiseras som en del av många lagrade objekt. En uppdatering av ett lands-/regionnamn kräver att alla sådana objekt uppdateras i stället för en enskild rad. Relationsdatabaser kan också säkerställa relationsintegritet genom att framtvinga regler som sekundärnycklar. NoSQL-databaser erbjuder vanligtvis inte sådana begränsningar för sina data.
En annan komplexitet som NoSQL-databaser måste hantera är versionshantering. När ett objekts egenskaper ändras kanske det inte kan deserialiseras från tidigare versioner som har lagrats. Därför måste alla befintliga objekt som har en serialiserad (tidigare) version av objektet uppdateras för att överensstämma med det nya schemat. Den här metoden skiljer sig inte konceptuellt från en relationsdatabas, där schemaändringar ibland kräver uppdateringsskript eller mappningsuppdateringar. Antalet poster som måste ändras är dock ofta mycket större i NoSQL-metoden, eftersom det finns mer duplicering av data.
Det är möjligt i NoSQL-databaser att lagra flera versioner av objekt, något som fasta schemarelationsdatabaser vanligtvis inte stöder. I det här fallet måste dock programkoden ta hänsyn till förekomsten av tidigare versioner av objekt, vilket ökar komplexiteten.
NoSQL-databaser tillämpar vanligtvis inte ACID, vilket innebär att de har både prestanda- och skalbarhetsfördelar jämfört med relationsdatabaser. De passar bra för extremt stora datamängder och objekt som inte passar bra för lagring i normaliserade tabellstrukturer. Det finns ingen anledning till varför ett enda program inte kan dra nytta av både relationsdatabaser och NoSQL-databaser, med var och en där det passar bäst.
Azure Cosmos DB
Azure Cosmos DB är en fullständigt hanterad NoSQL-databastjänst som erbjuder molnbaserad schemafri datalagring. Azure Cosmos DB är byggt för snabba och förutsägbara prestanda, hög tillgänglighet, elastisk skalning och global distribution. Trots att det är en NoSQL-databas kan utvecklare använda omfattande och välbekanta SQL-frågefunktioner på JSON-data. Alla resurser i Azure Cosmos DB lagras som JSON-dokument. Resurser hanteras som objekt, som är dokument som innehåller metadata och feeds, som är samlingar med objekt. Bild 8–2 visar relationen mellan olika Azure Cosmos DB-resurser.
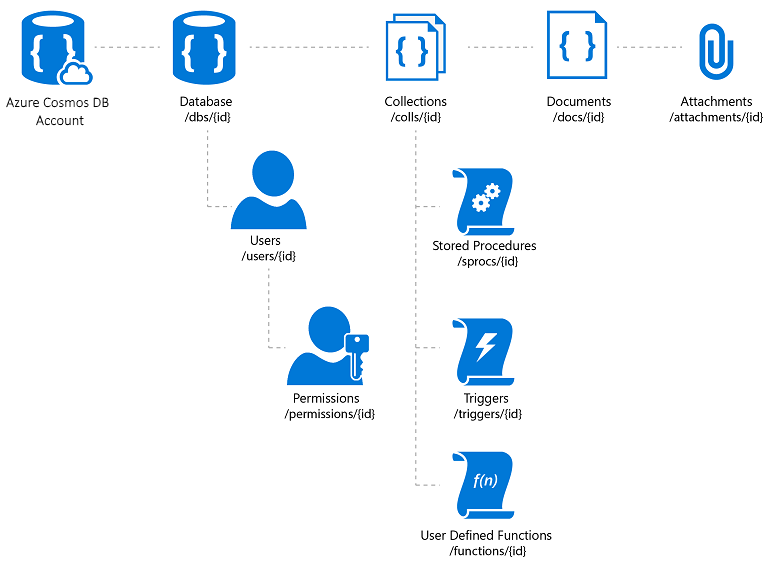
Bild 8-2. Azure Cosmos DB-resursorganisation.
Azure Cosmos DB-frågespråket är ett enkelt men kraftfullt gränssnitt för att köra frågor mot JSON-dokument. Språket har stöd för en delmängd av ANSI SQL-grammatiken och dessutom djupgående integration av objekt, matriser, objektkonstruktion och funktionsanrop i JavaScript.
Referenser – Azure Cosmos DB
- Introduktion till Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Andra alternativ för beständighet
Förutom relations- och NoSQL-lagringsalternativ kan ASP.NET Core-program använda Azure Storage för att lagra olika dataformat och filer på ett molnbaserat och skalbart sätt. Azure Storage är mycket skalbart, så du kan börja lagra små mängder data och skala upp till att lagra hundratals eller terabyte om programmet kräver det. Azure Storage stöder fyra typer av data:
Blob Storage för ostrukturerad text eller binär lagring, även kallat objektlagring.
Table Storage för strukturerade datauppsättningar som är tillgängliga via radnycklar.
Queue Storage för tillförlitliga köbaserade meddelanden.
File Storage för delad filåtkomst mellan virtuella Azure-datorer och lokala program.
Referenser – Azure Storage
- Introduktion till Azure Storage https://learn.microsoft.com/azure/storage/common/storage-introduction
Cachelagring
I webbprogram bör varje webbbegäran slutföras på kortast möjliga tid. Ett sätt att uppnå den här funktionen är att begränsa antalet externa anrop som servern måste göra för att slutföra begäran. Cachelagring innebär att en kopia av data lagras på servern (eller ett annat datalager som är enklare att fråga än datakällan). Webbprogram, och särskilt icke-SPA traditionella webbprogram, måste skapa hela användargränssnittet med varje begäran. Den här metoden omfattar ofta att göra många av samma databasfrågor upprepade gånger från en användarbegäran till en annan. I de flesta fall ändras dessa data sällan, så det finns ingen anledning att ständigt begära dem från databasen. ASP.NET Core stöder cachelagring av svar, cachelagring av hela sidor och cachelagring av data, vilket stöder mer detaljerad cachelagring.
När du implementerar cachelagring är det viktigt att tänka på att ta hänsyn till problem. Undvik att implementera cachelagringslogik i dataåtkomstlogik eller i användargränssnittet. Kapsla i stället in cachelagring i sina egna klasser och använd konfigurationen för att hantera dess beteende. Den här metoden följer principerna för öppet/stängt och enskilt ansvar och gör det enklare för dig att hantera hur du använder cachelagring i ditt program när det växer.
cachelagring av ASP.NET Core-svar
ASP.NET Core stöder två nivåer av cachelagring av svar. Den första nivån cachelagrar ingenting på servern, men lägger till HTTP-huvuden som instruerar klienter och proxyservrar att cachelagrar svar. Den här funktionen implementeras genom att lägga till attributet ResponseCache till enskilda kontrollanter eller åtgärder:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
Föregående exempel resulterar i att följande rubrik läggs till i svaret, vilket instruerar klienterna att cachelagrar resultatet i upp till 60 sekunder.
Cache-Control: public,max-age=60
För att kunna lägga till minnesintern cachelagring på serversidan i programmet måste du referera till Microsoft.AspNetCore.ResponseCaching NuGet-paketet och sedan lägga till mellanprogrammet Svarscachelagring. Det här mellanprogrammet konfigureras med tjänster och mellanprogram under appstarten:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
Svarscachelagringsmellanprogram cachelagrar automatiskt svar baserat på en uppsättning villkor som du kan anpassa. Som standard cachelagras endast 200 (OK) svar som begärs via GET- eller HEAD-metoder. Dessutom måste begäranden ha ett svar med en cachekontroll: offentlig rubrik och kan inte innehålla rubriker för auktorisering eller Set-Cookie. Se en fullständig lista över de cachelagringsvillkor som används av mellanprogrammet för cachelagring av svar.
Cachelagring av data
I stället för (eller utöver) cachelagring av fullständiga webbsvar kan du cachelagra resultatet av enskilda datafrågor. För den här funktionen kan du använda i minnescachelagring på webbservern eller använda en distribuerad cache. Det här avsnittet visar hur du implementerar i minnescachelagring.
Lägg till stöd för minnescachelagring (eller distribuerad) cachelagring med följande kod:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Se även till att lägga till Microsoft.Extensions.Caching.Memory NuGet-paketet.
När du har lagt till tjänsten begär IMemoryCache du via beroendeinmatning där du behöver komma åt cachen. I det här exemplet CachedCatalogService använder designmönstret Proxy (eller Dekoratör) genom att tillhandahålla en alternativ implementering av ICatalogService som styr åtkomsten till (eller lägger till beteende i) den underliggande CatalogService implementeringen.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Om du vill konfigurera programmet att använda den cachelagrade versionen av tjänsten, men ändå låta tjänsten hämta den instans av CatalogService som behövs i konstruktorn, lägger du till följande rader i Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Med den här koden på plats görs databasanropen för att hämta katalogdata bara en gång per minut, i stället för på varje begäran. Beroende på trafiken till webbplatsen kan detta ha en betydande inverkan på antalet frågor som görs i databasen och den genomsnittliga sidinläsningstiden för startsidan som för närvarande är beroende av alla tre frågor som exponeras av den här tjänsten.
Ett problem som uppstår när cachelagring implementeras är inaktuella data , det vill ex. data som har ändrats vid källan men en inaktuell version finns kvar i cacheminnet. Ett enkelt sätt att åtgärda det här problemet är att använda små cachevaraktigheter, eftersom det för ett upptaget program finns en begränsad ytterligare fördel med att utöka längden på data cachelagras. Tänk dig till exempel en sida som gör en enskild databasfråga och som begärs 10 gånger per sekund. Om den här sidan cachelagras i en minut resulterar det i att antalet databasfrågor som görs per minut sjunker från 600 till 1, en minskning med 99,8 %. Om cachevaraktigheten i stället gjordes en timme skulle den totala minskningen vara 99,997 %, men nu ökar både sannolikheten och den potentiella åldern för inaktuella data dramatiskt.
En annan metod är att proaktivt ta bort cacheposter när de data de innehåller uppdateras. En enskild post kan tas bort om dess nyckel är känd:
_cache.Remove(cacheKey);
Om ditt program exponerar funktioner för att uppdatera poster som det cachelagrar kan du ta bort motsvarande cacheposter i koden som utför uppdateringarna. Ibland kan det finnas många olika poster som är beroende av en viss uppsättning data. I så fall kan det vara användbart att skapa beroenden mellan cacheposter med hjälp av en CancellationChangeToken. Med en CancellationChangeToken kan du förfalla flera cacheposter samtidigt genom att avbryta token.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
Cachelagring kan avsevärt förbättra prestandan för webbsidor som upprepade gånger begär samma värden från databasen. Se till att mäta dataåtkomst och sidprestanda innan du tillämpar cachelagring och använd endast cachelagring där du ser ett behov av förbättringar. Cachelagring förbrukar webbserverminnesresurser och ökar programmets komplexitet, så det är viktigt att du inte optimerar i förtid med den här tekniken.
Hämta data till BlazorWebAssembly appar
Om du skapar appar som använder Blazor Server kan du använda Entity Framework och andra tekniker för direkt dataåtkomst som de har diskuterats hittills i det här kapitlet. Men när du skapar BlazorWebAssembly appar, som andra SPA-ramverk, behöver du en annan strategi för dataåtkomst. Dessa program kommer vanligtvis åt data och interagerar med servern via webb-API-slutpunkter.
Om de data eller åtgärder som utförs är känsliga bör du granska avsnittet om säkerhet i föregående kapitel och skydda dina API:er mot obehörig åtkomst.
Du hittar ett exempel på en BlazorWebAssembly app i referensprogrammet eShopOnWeb i BlazorAdmin-projektet. Det här projektet finns i eShopOnWeb-webbprojektet och tillåter användare i gruppen Administratörer att hantera objekten i butiken. Du kan se en skärmbild av programmet i bild 8–3.
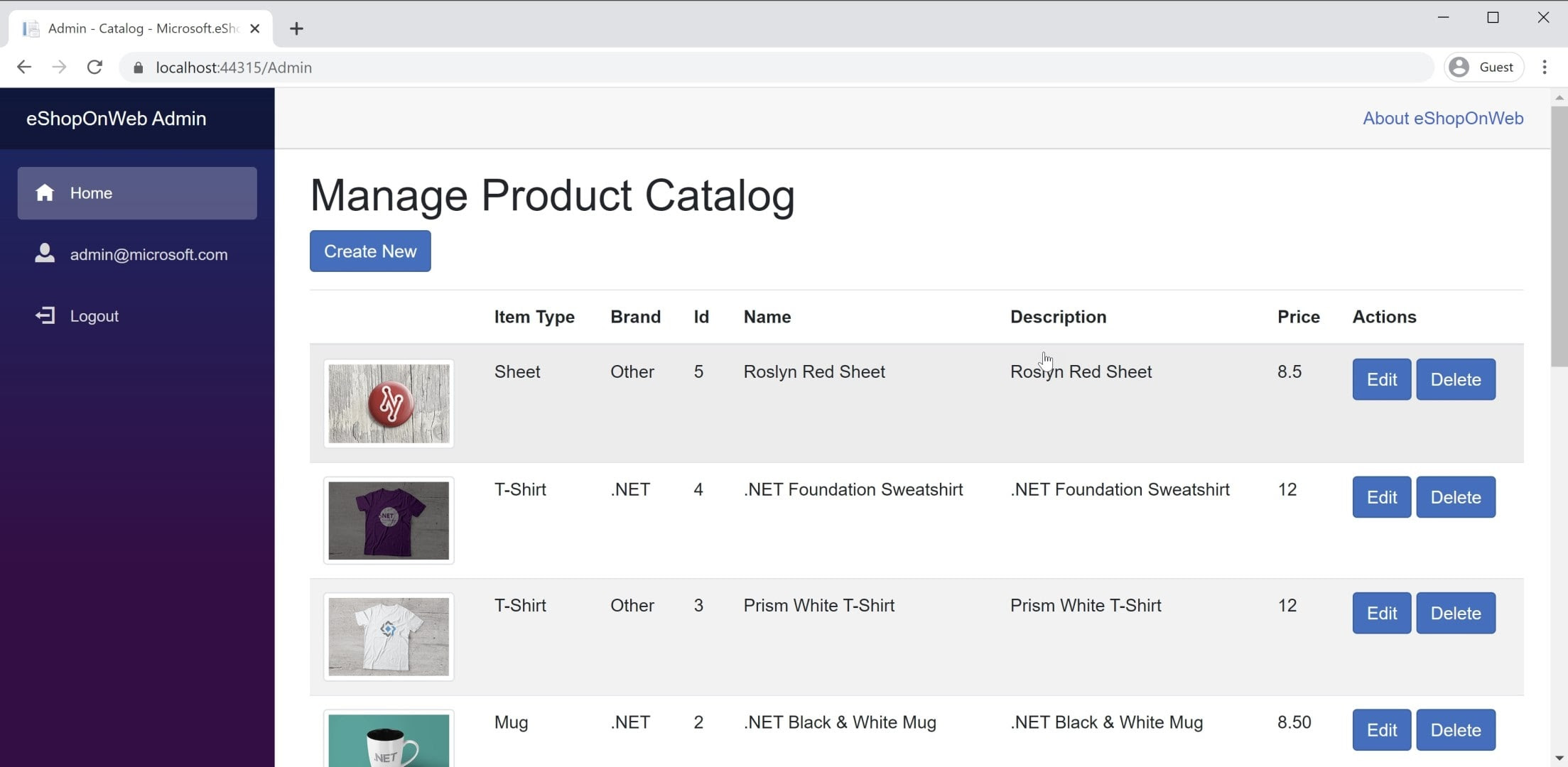
Bild 8-3. Skärmbild av eShopOnWeb-katalogadministratör.
När du hämtar data från webb-API:er i en BlazorWebAssembly app använder du bara en instans av HttpClient som i alla .NET-program. De grundläggande stegen är att skapa begäran att skicka (om det behövs, vanligtvis för POST- eller PUT-begäranden), invänta själva begäran, verifiera statuskoden och deserialisera svaret. Om du ska göra många förfrågningar till en viss uppsättning API:er är det en bra idé att kapsla in dina API:er och konfigurera basadressen HttpClient centralt. På så sätt kan du göra ändringarna på bara ett ställe om du behöver justera någon av dessa inställningar mellan miljöer. Du bör lägga till stöd för den här tjänsten i :Program.Main
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Om du behöver komma åt tjänster på ett säkert sätt bör du komma åt en säker token och konfigurera HttpClient för att skicka denna token som en autentiseringsrubrik med varje begäran:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Den här aktiviteten kan utföras från alla komponenter som har matats HttpClient in i den, förutsatt att HttpClient den inte har lagts till i programmets tjänster med en Transient livslängd. Varje referens till i programmet refererar till HttpClient samma instans, så ändringar i den i en komponent flödar genom hela programmet. Ett bra ställe att utföra den här autentiseringskontrollen (följt av att ange token) finns i en delad komponent som huvudnavigeringen för webbplatsen. Läs mer om den BlazorAdmin här metoden i projektet i referensprogrammet eShopOnWeb.
En fördel BlazorWebAssembly med över traditionella JavaScript-SPA:er är att du inte behöver synkronisera kopior av dina dataöverföringsobjekt (DTU:er). Både ditt BlazorWebAssembly projekt och ditt webb-API-projekt kan dela samma DTU:er i ett gemensamt delat projekt. Den här metoden eliminerar en del av friktionen i utvecklingen av SPA: er.
Om du snabbt vill hämta data från en API-slutpunkt kan du använda den inbyggda hjälpmetoden . GetFromJsonAsync Det finns liknande metoder för POST, PUT osv. Följande visar hur du hämtar en CatalogItem från en API-slutpunkt med hjälp av en konfigurerad HttpClient i en BlazorWebAssembly app:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
När du har de data du behöver spårar du vanligtvis ändringar lokalt. När du vill göra uppdateringar av serverdelsdatalagret anropar du ytterligare webb-API:er för detta ändamål.
Referenser – Blazor data
- Anropa ett webb-API från ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api