Hantera partiellt fel
Dricks
Det här innehållet är ett utdrag från eBook, .NET Microservices Architecture for Containerized .NET Applications, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

I distribuerade system som mikrotjänstbaserade program finns det en ständigt närvarande risk för partiella fel. Till exempel kan en enskild mikrotjänst/container misslyckas eller kanske inte är tillgänglig för att svara under en kort tid, eller så kan en enskild virtuell dator eller server krascha. Eftersom klienter och tjänster är separata processer kanske en tjänst inte kan svara i tid på en klients begäran. Tjänsten kan vara överbelastad och svara mycket långsamt på begäranden eller kanske inte är tillgänglig under en kort tid på grund av nätverksproblem.
Överväg till exempel sidan Orderinformation från exempelprogrammet eShopOnContainers. Om beställningsmikrotjänsten inte svarar när användaren försöker skicka en beställning skulle en felaktig implementering av klientprocessen (MVC-webbprogrammet) – till exempel om klientkoden skulle använda synkrona RPC:er utan tidsgräns – blockera trådar på obestämd tid i väntan på ett svar. Förutom att skapa en dålig användarupplevelse förbrukar eller blockerar varje svarsvänte en tråd, och trådar är mycket värdefulla i mycket skalbara program. Om det finns många blockerade trådar kan programmets körning så småningom ta slut på trådar. I så fall kan programmet bli globalt svarar inte i stället för bara delvis svarar, som visas i bild 8-1.
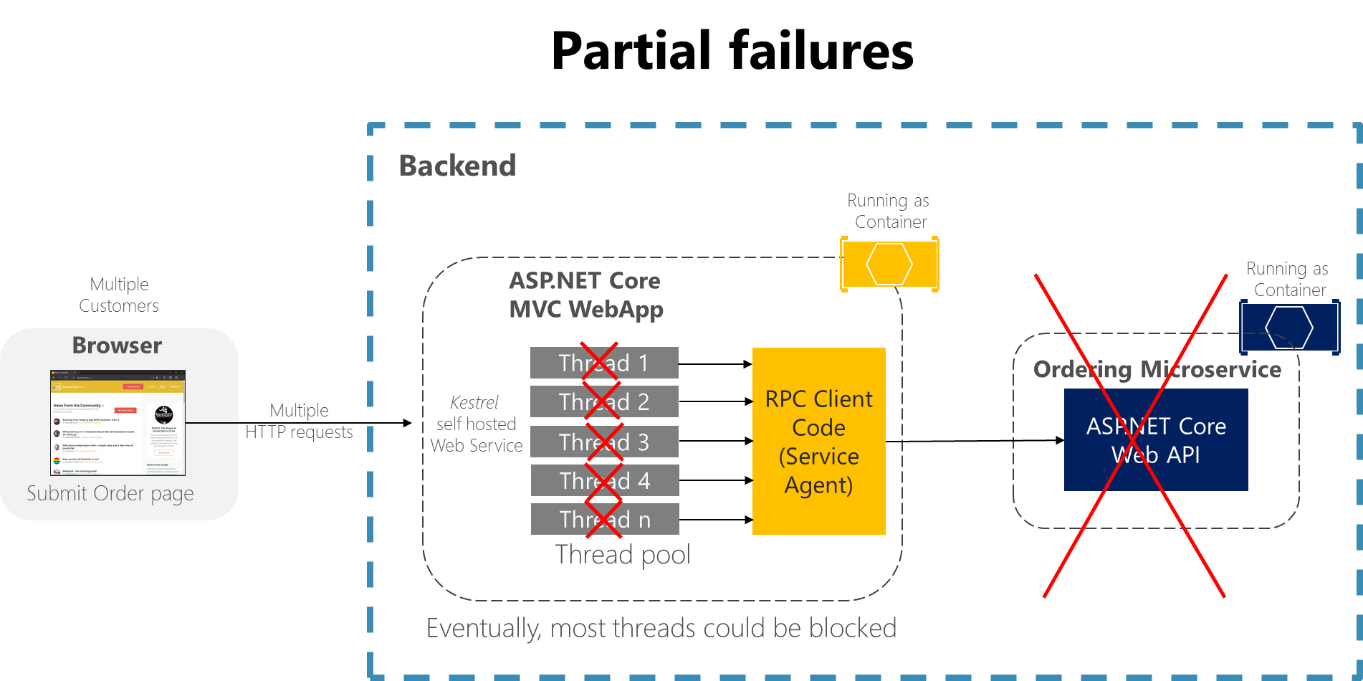
Bild 8-1. Partiella fel på grund av beroenden som påverkar tjänstens trådtillgänglighet
I ett stort mikrotjänstbaserat program kan eventuella partiella fel förstärkas, särskilt om de flesta interna mikrotjänstinteraktioner baseras på synkrona HTTP-anrop (vilket anses vara ett antimönster). Tänk på ett system som tar emot miljontals inkommande samtal per dag. Om systemet har en dålig design som baseras på långa kedjor av synkrona HTTP-anrop kan dessa inkommande anrop resultera i många fler miljoner utgående anrop (anta att ett förhållande på 1:4) till dussintals interna mikrotjänster som synkrona beroenden. Den här situationen visas i bild 8-2, särskilt beroende nr 3, som startar en kedja som anropar beroende nr 4, som sedan anropar #5.
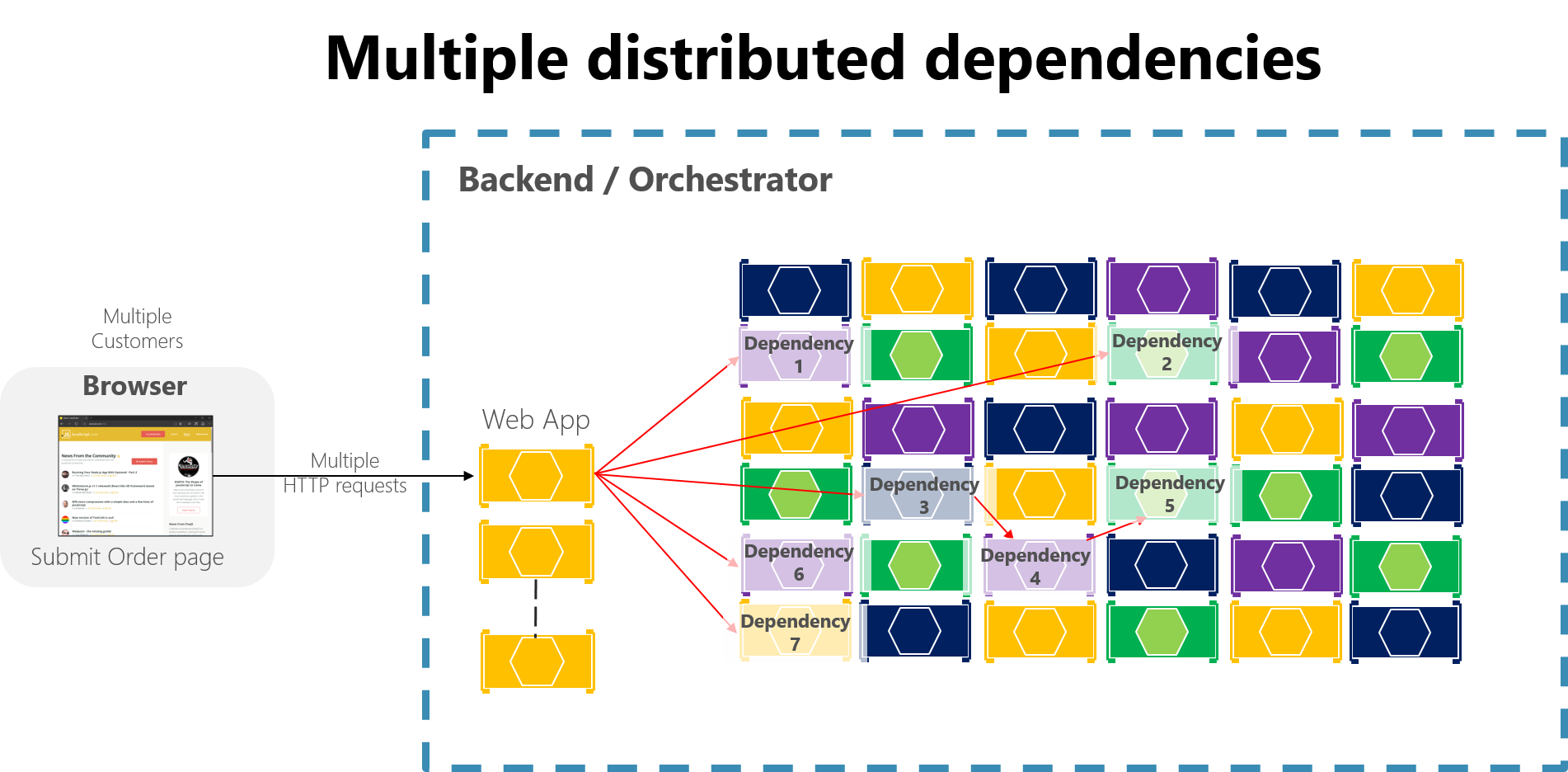
Bild 8-2. Effekten av att ha en felaktig design med långa kedjor av HTTP-begäranden
Tillfälliga fel garanteras i ett distribuerat och molnbaserat system, även om varje beroende i sig har utmärkt tillgänglighet. Det är ett faktum du måste tänka på.
Om du inte utformar och implementerar tekniker för att säkerställa feltolerans kan även små stilleståndstider förstärkas. Till exempel skulle 50 beroenden var och en med 99,99 % av tillgängligheten resultera i flera timmars stilleståndstid varje månad på grund av den här krusningseffekten. När ett mikrotjänstberoende misslyckas vid hantering av en stor mängd begäranden kan felet snabbt mätta alla tillgängliga begärandetrådar i varje tjänst och krascha hela programmet.
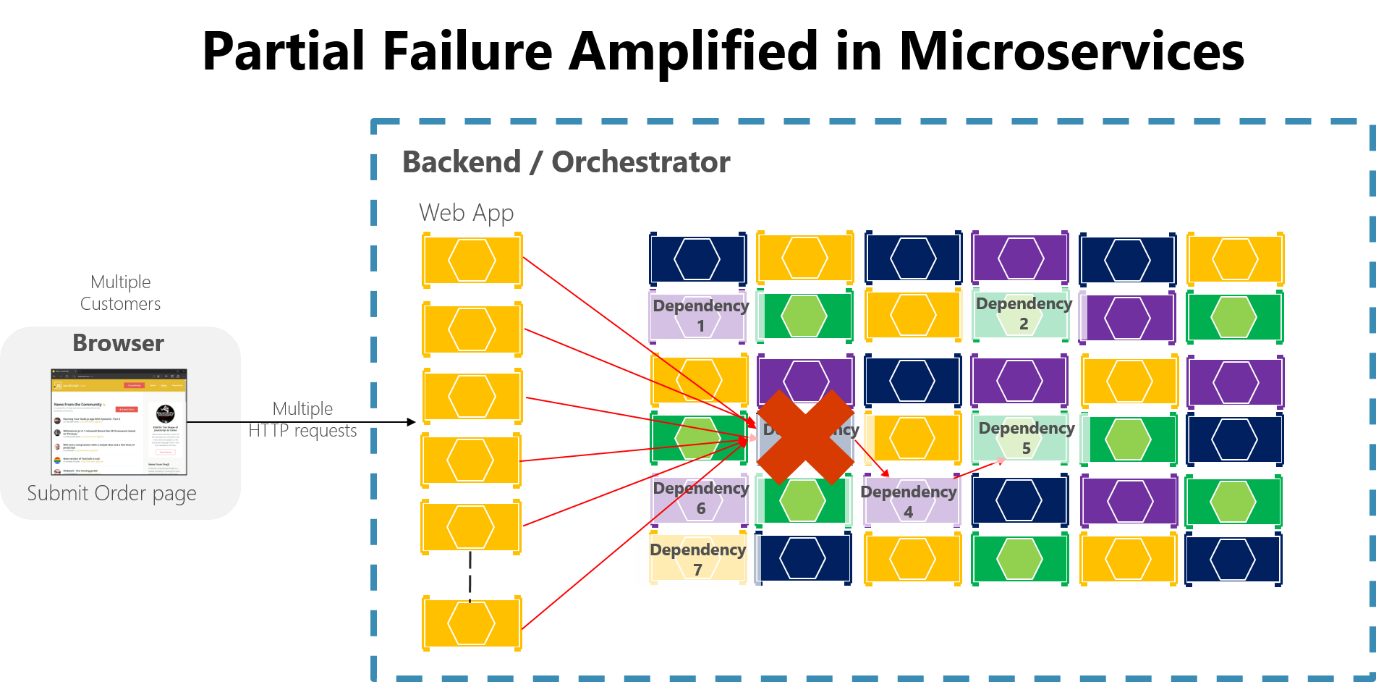
Bild 8-3. Partiellt fel som förstärks av mikrotjänster med långa kedjor av synkrona HTTP-anrop
För att minimera det här problemet rekommenderar den här guiden att du använder asynkron kommunikation mellan de interna mikrotjänsterna i avsnittet Asynkron mikrotjänstintegrering.
Dessutom är det viktigt att du utformar dina mikrotjänster och klientprogram för att hantera partiella fel– det vill vill s.v.s. skapa motståndskraftiga mikrotjänster och klientprogram.