Datasuveränitet per mikrotjänst
Dricks
Det här innehållet är ett utdrag från eBook, .NET Microservices Architecture for Containerized .NET Applications, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

En viktig regel för mikrotjänstarkitektur är att varje mikrotjänst måste äga sina domändata och sin logik. Precis som ett fullständigt program äger sin logik och sina data måste varje mikrotjänst äga sin logik och sina data under en autonom livscykel, med oberoende distribution per mikrotjänst.
Det innebär att domänens konceptuella modell skiljer sig mellan undersystem eller mikrotjänster. Överväg företagsprogram, där CRM-program (customer relationship management), undersystem för transaktionsköp och undersystem för kundsupport anropar varje anrop på unika kundentitetsattribut och data, och där var och en använder en annan begränsad kontext (BC).
Den här principen är liknande i domändriven design (DDD) där varje begränsad kontext eller autonomt undersystem eller tjänst måste äga sin domänmodell (data plus logik och beteende). Varje DDD-begränsad kontext korrelerar med en affärsmikrotjänst (en eller flera tjänster). Den här punkten om mönstret Begränsad kontext expanderas i nästa avsnitt.
Å andra sidan är den traditionella metoden (monolitiska data) som används i många program att ha en enda centraliserad databas eller bara några få databaser. Detta är ofta en normaliserad SQL-databas som används för hela programmet och alla dess interna undersystem, enligt bild 4–7.
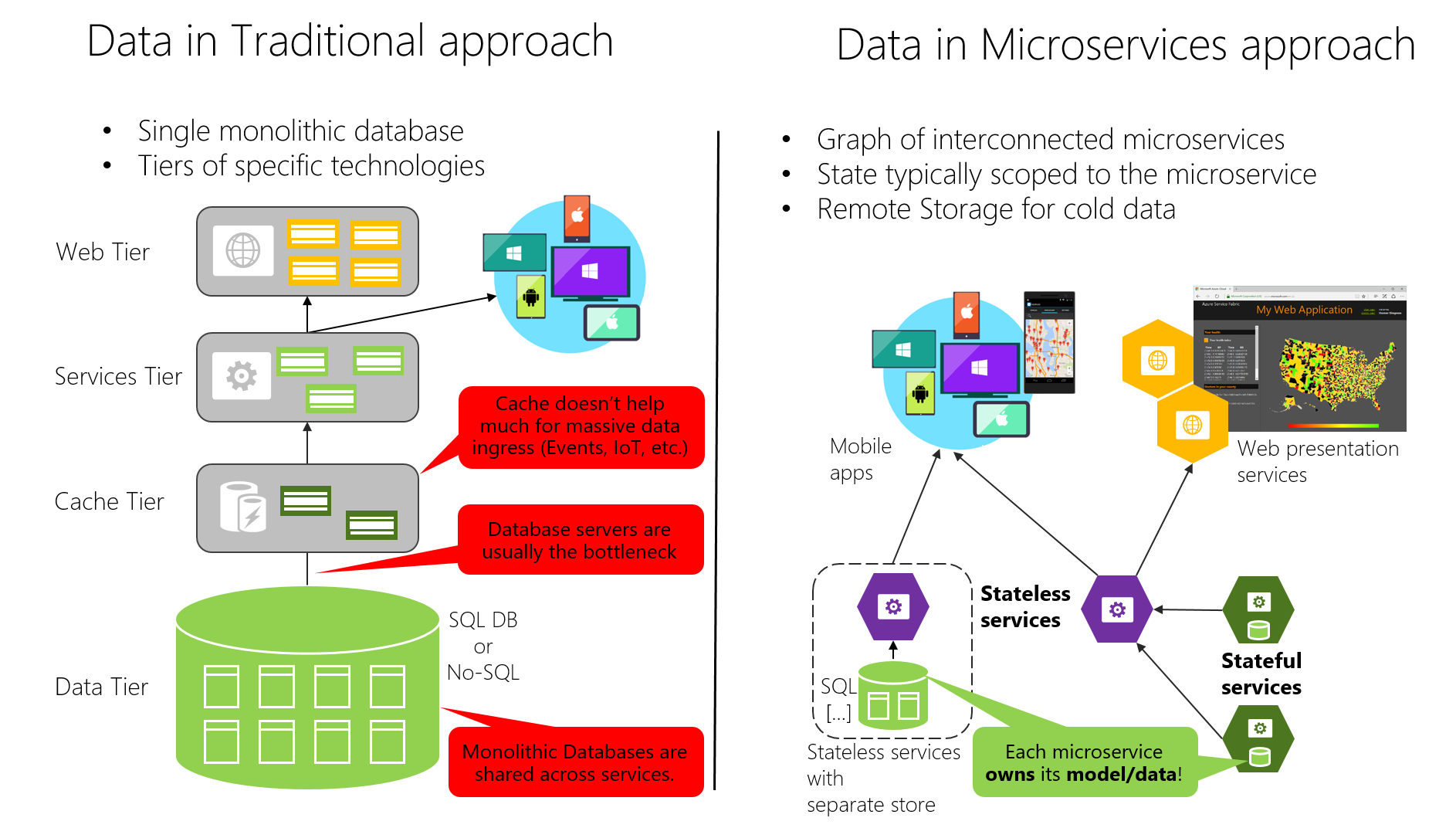
Bild 4-7. Jämförelse av datasuveränitet: monolitisk databas jämfört med mikrotjänster
I den traditionella metoden finns det en enkel databas som delas mellan alla tjänster, vanligtvis i en nivåindelad arkitektur. I mikrotjänstmetoden äger varje mikrotjänst sin modell/sina data. Den centraliserade databasmetoden ser inledningsvis enklare ut och verkar möjliggöra återanvändning av entiteter i olika undersystem för att göra allt konsekvent. Men verkligheten är att du får enorma tabeller som betjänar många olika undersystem och som innehåller attribut och kolumner som inte behövs i de flesta fall. Det är som att försöka använda samma fysiska karta för att vandra en kort stig, ta en dags lång biltur och lära sig geografi.
Ett monolitiskt program med vanligtvis en enda relationsdatabas har två viktiga fördelar: ACID-transaktioner och SQL-språket, som båda fungerar i alla tabeller och data som är relaterade till ditt program. Med den här metoden kan du enkelt skriva en fråga som kombinerar data från flera tabeller.
Dataåtkomst blir dock mycket mer komplicerat när du övergår till en arkitektur för mikrotjänster. Även när du använder ACID-transaktioner inom en mikrotjänst eller begränsad kontext är det viktigt att tänka på att de data som ägs av varje mikrotjänst är privata för den mikrotjänsten och endast ska nås synkront via dess API-slutpunkter (REST, gRPC, SOAP osv.) eller asynkront via meddelanden (AMQP eller liknande).
Genom att kapsla in data ser du till att mikrotjänsterna är löst kopplade och kan utvecklas oberoende av varandra. Om flera tjänster hade åtkomst till samma data skulle schemauppdateringar kräva samordnade uppdateringar av alla tjänster. Detta skulle bryta mikrotjänstlivscykelns autonomi. Men distribuerade datastrukturer innebär att du inte kan göra en enda ACID-transaktion mellan mikrotjänster. Detta innebär i sin tur att du måste använda slutlig konsekvens när en affärsprocess omfattar flera mikrotjänster. Det här är mycket svårare att implementera än enkla SQL-kopplingar eftersom du inte kan skapa integritetsbegränsningar eller använda distribuerade transaktioner mellan separata databaser, vilket vi kommer att förklara senare. På samma sätt är många andra relationsdatabasfunktioner inte tillgängliga för flera mikrotjänster.
Om du går ännu längre använder olika mikrotjänster ofta olika typer av databaser. Moderna program lagrar och bearbetar olika typer av data, och en relationsdatabas är inte alltid det bästa valet. För vissa användningsfall kan en NoSQL-databas som Azure CosmosDB eller MongoDB ha en bekvämare datamodell och erbjuda bättre prestanda och skalbarhet än en SQL-databas som SQL Server eller Azure SQL Database. I andra fall är en relationsdatabas fortfarande den bästa metoden. Därför använder mikrotjänstbaserade program ofta en blandning av SQL- och NoSQL-databaser, som ibland kallas för flerspråkig beständighet .
En partitionerad, flerspråkig arkitektur för datalagring har många fördelar. Dessa omfattar löst kopplade tjänster och bättre prestanda, skalbarhet, kostnader och hanterbarhet. Den kan dock introducera vissa utmaningar för distribuerad datahantering, som beskrivs i "Identifiera domänmodellgränser" senare i det här kapitlet.
Relationen mellan mikrotjänster och mönstret Begränsad kontext
Begreppet mikrotjänst härleds från mönstret Begränsad kontext (BC) i domändriven design (DDD). DDD hanterar stora modeller genom att dela upp dem i flera BCs och vara explicita om sina gränser. Varje BC måste ha en egen modell och databas. på samma sätt äger varje mikrotjänst sina relaterade data. Dessutom har varje BC vanligtvis sitt eget allestädes närvarande språk för att hjälpa kommunikationen mellan programvaruutvecklare och domänexperter.
Dessa termer (främst domänentiteter) på det allestädes närvarande språket kan ha olika namn i olika avgränsade kontexter, även om olika domänentiteter delar samma identitet (dvs. det unika ID som används för att läsa entiteten från lagring). I en användarprofil avgränsad kontext kan till exempel entiteten Användardomän dela identitet med domänen Buyer i den avgränsade kontexten.
En mikrotjänst är därför som en begränsad kontext, men den anger också att det är en distribuerad tjänst. Den skapas som en separat process för varje begränsad kontext och måste använda de distribuerade protokoll som antecknades tidigare, till exempel HTTP/HTTPS, WebSockets eller AMQP. Mönstret Begränsad kontext anger dock inte om den avgränsade kontexten är en distribuerad tjänst eller om det bara är en logisk gräns (till exempel ett allmänt undersystem) i ett monolitiskt distributionsprogram.
Det är viktigt att markera att det är bra att definiera en tjänst för varje begränsad kontext. Men du behöver inte begränsa din design till den. Ibland måste du utforma en begränsad kontext eller affärsmikrotjänst som består av flera fysiska tjänster. Men i slutändan är båda mönstren – Begränsad kontext och mikrotjänst – nära relaterade.
DDD drar nytta av mikrotjänster genom att få verkliga gränser i form av distribuerade mikrotjänster. Men idéer som att inte dela modellen mellan mikrotjänster är vad du också vill ha i en begränsad kontext.
Ytterligare resurser
Chris Richardson. Mönster: Databas per tjänst
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Strategisk domändriven design med kontextmappning
https://www.infoq.com/articles/ddd-contextmapping