Loggning med elastisk stack
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Det finns många bra centraliserade loggningsverktyg och de varierar i kostnad från att vara kostnadsfria verktyg med öppen källkod till dyrare alternativ. I många fall är de kostnadsfria verktygen lika bra som eller bättre än de betalda erbjudandena. Ett sådant verktyg är en kombination av tre komponenter med öppen källkod: Elasticsearch, Logstash och Kibana.
Tillsammans kallas dessa verktyg för Elastic Stack eller ELK-stacken.
Elastisk stack
Elastic Stack är ett kraftfullt alternativ för att samla in information från ett Kubernetes-kluster. Kubernetes har stöd för att skicka loggar till en Elasticsearch-slutpunkt, och för det mesta behöver du bara komma igång med att ange miljövariablerna enligt bild 7–5:
KUBE_LOGGING_DESTINATION=elasticsearch
KUBE_ENABLE_NODE_LOGGING=true
Bild 7-5. Konfigurationsvariabler för Kubernetes
Det här steget installerar Elasticsearch på klustret och målet skickar alla klusterloggar till det.
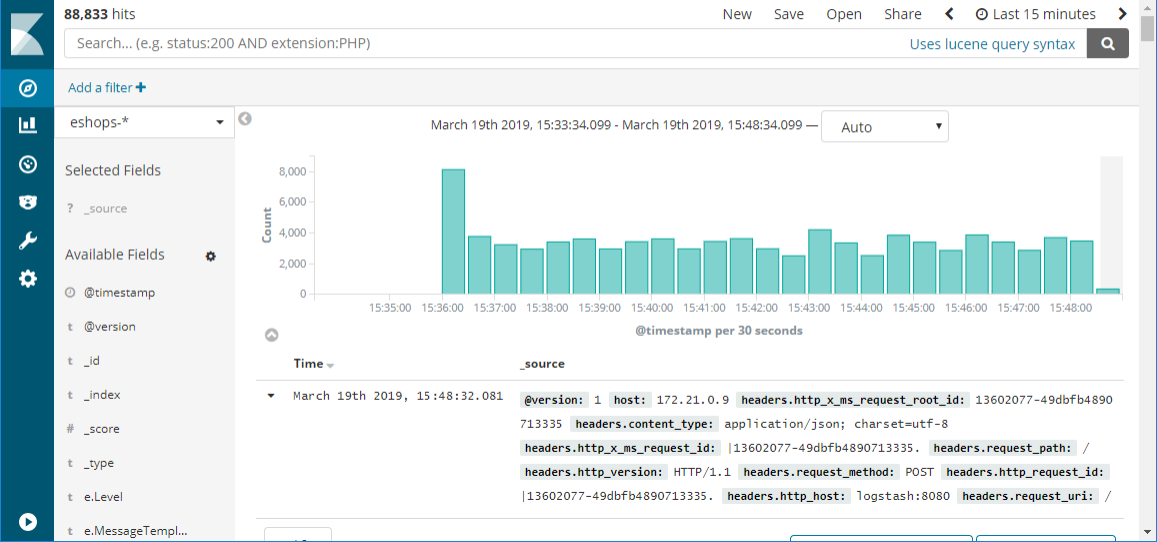 Bild 7-6. Ett exempel på en Kibana-instrumentpanel som visar resultatet av en fråga mot loggar som matas in från Kubernetes
Bild 7-6. Ett exempel på en Kibana-instrumentpanel som visar resultatet av en fråga mot loggar som matas in från Kubernetes
Vilka är fördelarna med Elastic Stack?
Elastic Stack tillhandahåller centraliserad loggning på ett billigt, skalbart och molnvänligt sätt. Användargränssnittet effektiviserar dataanalysen så att du kan ägna tid åt att samla in insikter från dina data i stället för att slåss med ett klumpigt gränssnitt. Det har stöd för en mängd olika indata, så eftersom ditt distribuerade program sträcker sig över fler och olika typer av tjänster kan du förvänta dig att fortsätta att kunna mata in logg- och måttdata i systemet. Elastic Stack har också stöd för snabba sökningar även i stora datamängder, vilket gör det möjligt även för stora program att logga detaljerade data och ändå kunna få insyn i dem på ett högpresterande sätt.
Logstash
Den första komponenten är Logstash. Det här verktyget används för att samla in logginformation från en mängd olika källor. Logstash kan till exempel läsa loggar från disken och även ta emot meddelanden från loggningsbibliotek som Serilog. Logstash kan utföra viss grundläggande filtrering och expansion i loggarna när de anländer. Om loggarna till exempel innehåller IP-adresser kan Logstash konfigureras för att göra en geografisk sökning och hämta ett land/en region eller till och med ursprungsort för meddelandet.
Serilog är ett loggningsbibliotek för .NET-språk, vilket möjliggör parametriserad loggning. I stället för att generera ett textloggmeddelande som bäddar in fält hålls parametrarna separata. Det här biblioteket möjliggör mer intelligent filtrering och sökning. En Serilog-exempelkonfiguration för skrivning till Logstash visas i bild 7–7.
var log = new LoggerConfiguration()
.WriteTo.Http("http://localhost:8080")
.CreateLogger();
Bild 7-7. Serilog-konfiguration för att skriva logginformation direkt till logstash via HTTP
Logstash skulle använda en konfiguration som den som visas i bild 7-8.
input {
http {
#default host 0.0.0.0:8080
codec => json
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
index=>"sales-%{+xxxx.ww}"
}
}
Bild 7-8. En Logstash-konfiguration för användning av loggar från Serilog
För scenarier där omfattande loggmanipulering inte behövs finns det ett alternativ till Logstash som kallas Beats. Beats är en uppsättning verktyg som kan samla in en mängd olika data från loggar till nätverksdata och information om drifttid. Många program använder både Logstash och Beats.
När loggarna har samlats in av Logstash måste de placeras någonstans. Logstash stöder många olika utdata, men en av de mer spännande är Elasticsearch.
Elasticsearch
Elasticsearch är en kraftfull sökmotor som kan indexeras när loggarna tas emot. Det gör det snabbt att köra frågor mot loggarna. Elasticsearch kan hantera stora mängder loggar och kan i extrema fall skalas ut över många noder.
Loggmeddelanden som har skapats för att innehålla parametrar eller som har fått parametrar uppdelade från dem via Logstash-bearbetning, kan frågas direkt eftersom Elasticsearch bevarar den här informationen.
En fråga som söker efter de 10 bästa sidorna som besöks av jill@example.comvisas i bild 7–9.
"query": {
"match": {
"user": "jill@example.com"
}
},
"aggregations": {
"top_10_pages": {
"terms": {
"field": "page",
"size": 10
}
}
}
Bild 7-9. En Elasticsearch-fråga för att hitta de 10 bästa sidorna som besöks av en användare
Visualisera information med Kibana-webbinstrumentpaneler
Den sista komponenten i stacken är Kibana. Det här verktyget används för att tillhandahålla interaktiva visualiseringar på en webbinstrumentpanel. Instrumentpaneler kan skapas även av användare som inte är tekniska. De flesta data som finns i Elasticsearch-indexet kan ingå i Kibana-instrumentpanelerna. Enskilda användare kan ha olika önskemål på instrumentpanelen och Kibana möjliggör den här anpassningen genom att tillåta användarspecifika instrumentpaneler.
Installera Elastic Stack på Azure
Den elastiska stacken kan installeras på Azure på många sätt. Som alltid är det möjligt att etablera virtuella datorer och installera Elastic Stack på dem direkt. Det här alternativet är att föredra av vissa erfarna användare eftersom det erbjuder högsta grad av anpassningsbarhet. Distribution av infrastruktur som en tjänst medför betydande hanteringskostnader som tvingar dem som tar den vägen att ta ansvar för alla uppgifter som är associerade med infrastruktur som en tjänst, till exempel att skydda datorerna och hålla sig uppdaterade med korrigeringar.
Ett alternativ med mindre omkostnader är att använda en av de många Docker-containrar där Elastic Stack redan har konfigurerats. Dessa containrar kan släppas till ett befintligt Kubernetes-kluster och köras tillsammans med programkod. Sebp /elk-containern är en väldokumenterad och testad Elastic Stack-container.
Ett annat alternativ är ett nyligen tillkännagivit ELK-as-a-service-erbjudande.