DevOps
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Favoritmantrat av programvarukonsulter är att svara "Det beror" på alla frågor som ställs. Det beror inte på att programvarukonsulter är förtjusta i att inte ta en position. Det beror på att det inte finns något riktigt svar på några frågor i programvara. Det finns ingen absolut rätt och fel, utan snarare en balans mellan motsatser.
Ta till exempel de två stora skolorna för att utveckla webbprogram: enkelsidiga program (SPA) jämfört med program på serversidan. Å ena sidan tenderar användarupplevelsen att vara bättre med SPA och mängden trafik till webbservern kan minimeras, vilket gör det möjligt att vara värd för dem på något så enkelt som statisk värd. Å andra sidan tenderar SPA:er att vara långsammare att utveckla och svårare att testa. Vilket är rätt val? Det beror på din situation.
Molnbaserade program är inte immuna mot samma dikotomi. De har tydliga fördelar när det gäller snabb utveckling, stabilitet och skalbarhet, men det kan vara lite svårare att hantera dem.
För flera år sedan var det inte ovanligt att processen med att flytta ett program från utveckling till produktion tar en månad, eller ännu mer. Företag släppte programvara på en 6-månad eller till och med varje år kadens. Man behöver inte leta längre än Microsoft Windows för att få en uppfattning om den takt av utgåvor som var acceptabla före de ständigt gröna dagarna av Windows 10. Fem år gick mellan Windows XP och Vista, ytterligare tre mellan Vista och Windows 7.
Det är nu ganska väletablerat att kunna släppa programvara snabbt ger snabbrörliga företag en enorm marknadsfördel jämfört med sina mer sengångarliknande konkurrenter. Därför är viktiga uppdateringar av Windows 10 nu ungefär var sjätte månad.
De mönster och metoder som möjliggör snabbare och mer tillförlitliga versioner för att leverera värde till verksamheten kallas tillsammans DevOps. De består av en mängd olika idéer som sträcker sig över hela livscykeln för programvaruutveckling från att ange ett program hela vägen fram till att leverera och driva programmet.
DevOps uppstod före mikrotjänster och det är troligt att rörelsen mot mindre, mer ändamålsenliga tjänster inte hade varit möjlig utan DevOps för att göra det enklare att släppa och använda inte bara ett utan många program i produktion.
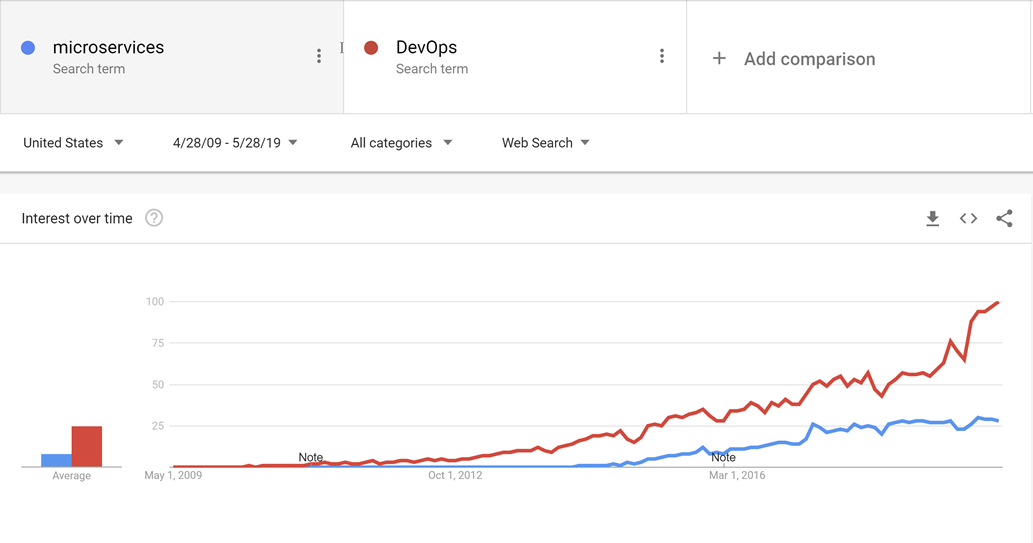
Bild 10–1 – DevOps och mikrotjänster.
Med bra DevOps-metoder kan du utnyttja fördelarna med molnbaserade program utan att kvävas under ett berg av arbete som faktiskt driver programmen.
Det finns ingen gyllene hammare när det gäller DevOps. Ingen kan sälja en komplett och heltäckande lösning för att släppa och driva högkvalitativa program. Det beror på att varje program skiljer sig mycket från alla andra. Det finns dock verktyg som kan göra DevOps till ett mycket mindre skrämmande förslag. Ett av dessa verktyg kallas Azure DevOps.
Azure DevOps
Azure DevOps har en lång stamtavla. Den kan spåra sina rötter tillbaka till när Team Foundation Server först flyttade online och genom de olika namnändringarna: Visual Studio Online och Visual Studio Team Services. Genom åren har det dock blivit mycket mer än sina föregångare.
Azure DevOps är indelat i fem huvudkomponenter:

Bild 10–2 – Azure DevOps.
Azure Repos – Källkodshantering som stöder den ärevördiga Versionskontroll för Team Foundation (TFVC) och branschfavoriten Git. Pull-begäranden är ett sätt att aktivera social kodning genom att främja diskussioner om ändringar när de görs.
Azure Boards – Tillhandahåller ett verktyg för spårning av problem och arbetsobjekt som strävar efter att tillåta användare att välja de arbetsflöden som fungerar bäst för dem. Det levereras med ett antal förkonfigurerade mallar, inklusive mallar för att stödja SCRUM- och Kanban-utvecklingsstilar.
Azure Pipelines – ett bygg- och versionshanteringssystem som stöder nära integrering med Azure. Byggen kan köras på olika plattformar från Windows till Linux till macOS. Byggagenter kan etableras i molnet eller lokalt.
Azure-testplaner – Ingen QA-person lämnas kvar med testhantering och undersökande teststöd som erbjuds av funktionen Testplaner.
Azure Artifacts – ett artefaktflöde som gör det möjligt för företag att skapa egna, interna versioner av NuGet, npm och andra. Det tjänar ett dubbelt syfte att fungera som en cache med överordnade paket om det uppstår ett fel på en centraliserad lagringsplats.
Den översta organisationsenheten i Azure DevOps kallas för ett projekt. I varje projekt kan de olika komponenterna, till exempel Azure Artifacts, aktiveras och inaktiveras. Var och en av dessa komponenter ger olika fördelar för molnbaserade program. De tre mest användbara är lagringsplatser, tavlor och pipelines. Om användarna vill hantera sin källkod i en annan lagringsplatsstacken, till exempel GitHub, men ändå dra nytta av Azure Pipelines och andra komponenter, är det fullt möjligt.
Lyckligtvis har utvecklingsteam många alternativ när de väljer en lagringsplats. En av dem är GitHub.
GitHub Actions
GitHub grundades 2009 och är en allmänt populär webbaserad lagringsplats för värdprojekt, dokumentation och kod. Många stora teknikföretag som Apple, Amazon, Google och vanliga företag använder GitHub. GitHub använder det distribuerade versionskontrollsystemet med öppen källkod med namnet Git som grund. Överst lägger den sedan till en egen uppsättning funktioner, inklusive felspårning, funktions- och pull-begäranden, uppgiftshantering och wikis för varje kodbas.
Allt eftersom GitHub utvecklas läggs även DevOps-funktioner till. GitHub har till exempel en egen CI/CD-pipeline (continuous integration/continuous delivery), kallad GitHub Actions. GitHub Actions är ett verktyg för automatisering av arbetsflöden som drivs av communityn. Det gör att DevOps-team kan integreras med sina befintliga verktyg, blanda och matcha nya produkter och ansluta till sin programvarulivscykel, inklusive befintliga CI/CD-partner."
GitHub har över 40 miljoner användare, vilket gör det till världens största värd för källkod. I oktober 2018 köpte Microsoft GitHub. Microsoft har lovat att GitHub ska förbli en öppen plattform som alla utvecklare kan ansluta till och utöka. Det fortsätter att fungera som ett oberoende företag. GitHub erbjuder planer för företag, team, professionella och kostnadsfria konton.
Källkontroll
Det kan vara svårt att organisera koden för ett molnbaserat program. I stället för ett enda jätteprogram tenderar de molnbaserade programmen att bestå av en webb med mindre program som pratar med varandra. Precis som med allt inom databehandling är det bästa arrangemanget av kod fortfarande en öppen fråga. Det finns exempel på lyckade program som använder olika typer av layouter, men två varianter verkar ha störst popularitet.
Innan du börjar använda själva källkontrollen är det förmodligen värt att bestämma hur många projekt som är lämpliga. I ett enda projekt finns stöd för flera lagringsplatser och bygg-pipelines. Tavlor är lite mer komplicerade, men även där kan uppgifterna enkelt tilldelas till flera team i ett enda projekt. Det är möjligt att stödja hundratals, till och med tusentals utvecklare, från ett enda Azure DevOps-projekt. Att göra det är förmodligen den bästa metoden eftersom det ger en enda plats för alla utvecklare att arbeta sig ur och minskar förvirringen att hitta det programmet när utvecklare är osäkra på i vilket projekt det finns.
Det kan vara lite svårare att dela upp kod för mikrotjänster i Azure DevOps-projektet.
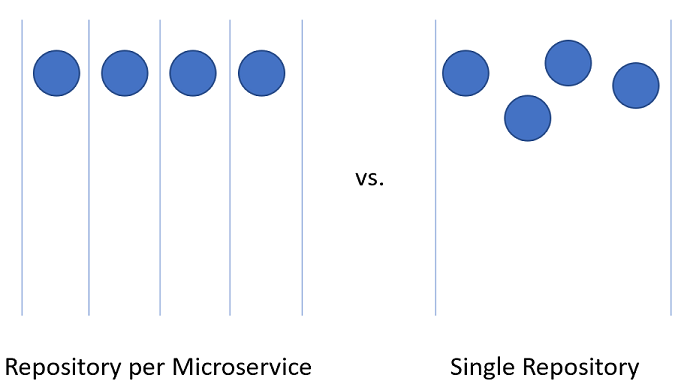
Bild 10–3 – En jämfört med många lagringsplatser.
Lagringsplats per mikrotjänst
Vid första anblicken verkar den här metoden vara den mest logiska metoden för att dela upp källkoden för mikrotjänster. Varje lagringsplats kan innehålla den kod som behövs för att skapa en mikrotjänst. Fördelarna med den här metoden är tydliga:
- Instruktioner för att skapa och underhålla programmet kan läggas till i en README-fil i roten på varje lagringsplats. När du bläddrar igenom lagringsplatserna är det enkelt att hitta dessa instruktioner, vilket minskar spin-up-tiden för utvecklare.
- Varje tjänst finns på en logisk plats, lätt att hitta genom att känna till namnet på tjänsten.
- Byggen kan enkelt konfigureras så att de bara utlöses när en ändring görs i den ägande lagringsplatsen.
- Antalet ändringar som kommer till en lagringsplats är begränsat till det lilla antal utvecklare som arbetar med projektet.
- Säkerhet är enkelt att konfigurera genom att begränsa de lagringsplatser som utvecklare har läs- och skrivbehörighet till.
- Inställningar på lagringsplatsnivå kan ändras av ägande teamet med ett minimum av diskussioner med andra.
En av de viktigaste idéerna bakom mikrotjänster är att tjänster ska siloed och separeras från varandra. När du använder domändriven design för att bestämma gränserna för tjänster fungerar tjänsterna som transaktionsgränser. Databasuppdateringar bör inte omfatta flera tjänster. Den här samlingen av relaterade data kallas för en begränsad kontext. Den här idén återspeglas av isoleringen av mikrotjänstdata till en databas som är separat och autonom från resten av tjänsterna. Det är mycket meningsfullt att bära denna idé hela vägen till källkoden.
Den här metoden är dock inte utan problem. Ett av vår tids mer gnarly utvecklingsproblem är att hantera beroenden. Överväg antalet filer som utgör den genomsnittliga node_modules katalogen. En ny installation av något liknande create-react-app kommer sannolikt att medföra tusentals paket. Frågan om hur man hanterar dessa beroenden är svår.
Om ett beroende uppdateras måste även underordnade paket uppdatera det här beroendet. Tyvärr kräver det utvecklingsarbete, så katalogen får alltid node_modules flera versioner av ett enda paket, var och en ett beroende av något annat paket som är versionshanterat i en något annorlunda takt. Vilken version av ett beroende ska användas när du distribuerar ett program? Vilken version är för närvarande i produktion? Den version som för närvarande finns i Beta men sannolikt kommer att vara i produktion när konsumenten tar sig till produktion? Svåra problem som inte löses genom att bara använda mikrotjänster.
Det finns bibliotek som är beroende av en mängd olika projekt. Genom att dela upp mikrotjänsterna med en på varje lagringsplats kan de interna beroendena bäst lösas med hjälp av den interna lagringsplatsen Azure Artifacts. Versioner för bibliotek skickar sina senaste versioner till Azure Artifacts för intern förbrukning. Det underordnade projektet måste fortfarande uppdateras manuellt för att kunna vara beroende av de nyligen uppdaterade paketen.
En annan nackdel är att flytta kod mellan tjänster. Även om det skulle vara trevligt att tro att den första uppdelningen av ett program i mikrotjänster är 100% korrekt, är verkligheten att vi sällan är så förutseende att vi inte gör några misstag i tjänstdivisionen. Därför måste funktioner och den kod som kör den flyttas från tjänst till tjänst: lagringsplats till lagringsplats. När du hoppar från en lagringsplats till en annan förlorar koden sin historik. Det finns många fall, särskilt i händelse av en granskning, där det är ovärderligt att ha fullständig historik på en koddel.
Den sista och viktigaste nackdelen är att samordna förändringar. I ett sant mikrotjänstprogram bör det inte finnas några distributionsberoenden mellan tjänster. Det bör vara möjligt att distribuera tjänster A, B och C i valfri ordning eftersom de har lös koppling. I verkligheten finns det dock tillfällen då det är önskvärt att göra en ändring som korsar flera lagringsplatser samtidigt. Några exempel är att uppdatera ett bibliotek för att stänga ett säkerhetshål eller ändra ett kommunikationsprotokoll som används av alla tjänster.
För att göra en ändring mellan lagringsplatser krävs en incheckning till varje lagringsplats i följd. Varje ändring i varje lagringsplats måste hämtas och granskas separat. Den här aktiviteten kan vara svår att samordna.
Ett alternativ till att använda många lagringsplatser är att sätta ihop all källkod i en gigantisk, allvetande, enskild lagringsplats.
Enkel lagringsplats
I den här metoden, som ibland kallas monodatabas, placeras all källkod för varje tjänst på samma lagringsplats. Till en början verkar detta tillvägagångssätt vara en fruktansvärd idé som sannolikt kommer att göra det otympligt att hantera källkod. Det finns dock vissa tydliga fördelar med att arbeta på det här sättet.
Den första fördelen är att det är enklare att hantera beroenden mellan projekt. I stället för att förlita sig på någon extern artefaktfeed kan projekt importera varandra direkt. Det innebär att uppdateringarna är omedelbara och att motstridiga versioner sannolikt kommer att hittas vid kompileringstillfället på utvecklarens arbetsstation. I själva verket skiftar en del av integreringstestningen kvar.
När du flyttar kod mellan projekt är det nu enklare att bevara historiken eftersom filerna har flyttats i stället för att skrivas om.
En annan fördel är att omfattande ändringar som korsar tjänstgränser kan göras i en enda incheckning. Den här aktiviteten minskar kostnaderna för att ha potentiellt dussintals ändringar att granska individuellt.
Det finns många verktyg som kan utföra statisk analys av kod för att identifiera osäkra programmeringsmetoder eller problematisk användning av API:er. I en värld med flera lagringsplatser måste varje lagringsplats itereras över för att hitta problemen i dem. Med den enda lagringsplatsen kan du köra analysen på ett och samma ställe.
Det finns också många nackdelar med metoden för enkel lagringsplats. En av de mest oroande är att en enda lagringsplats ger upphov till säkerhetsproblem. Om innehållet i en lagringsplats läcker ut på en lagringsplats per tjänstmodell är mängden förlorad kod minimal. Med en enda lagringsplats kan allt företaget äger gå förlorat. Det har funnits många exempel tidigare på att detta händer och spåra ur hela spelutvecklingsarbetet. Att ha flera lagringsplatser exponerar mindre yta, vilket är ett önskvärt drag i de flesta säkerhetsrutiner.
Storleken på den enskilda lagringsplatsen kommer sannolikt att bli ohanterlig snabbt. Detta ger några intressanta prestandakonsekvenser. Det kan bli nödvändigt att använda specialiserade verktyg som Virtual File System för Git, som ursprungligen utformades för att förbättra upplevelsen för utvecklare i Windows-teamet.
Ofta handlar argumentet för att använda en enda lagringsplats ner till ett argument som Facebook eller Google använder den här metoden för källkodsarrangemang. Om metoden är tillräckligt bra för dessa företag är det säkert rätt metod för alla företag. Sanningen är att få företag verkar på något liknande skalan av Facebook eller Google. De problem som uppstår i dessa skalor skiljer sig från de flesta utvecklare kommer att stöta på. Det som är bra för gåsen kanske inte är bra för gander.
I slutändan kan någon av lösningarna användas som värd för källkoden för mikrotjänster. I de flesta fall är dock hanterings- och teknikkostnaderna för att arbeta på en enda lagringsplats inte värda de magera fördelarna. Att dela upp kod över flera lagringsplatser uppmuntrar till bättre uppdelning av problem och uppmuntrar självbestämmande mellan utvecklingsteam.
Standardkatalogstruktur
Oavsett vilken enskild eller flera lagringsplatser debatten varje tjänst kommer att ha sin egen katalog. En av de bästa optimeringarna för att göra det möjligt för utvecklare att snabbt korsa mellan projekt är att upprätthålla en standardkatalogstruktur.
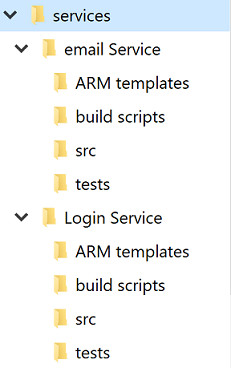
Bild 10–4 – Standardkatalogstruktur.
När ett nytt projekt skapas ska en mall som placerar rätt struktur användas. Den här mallen kan också innehålla sådana användbara objekt som en README-fil och en azure-pipelines.yml. I alla mikrotjänstarkitekturer gör en hög grad av varians mellan projekt massåtgärder mot tjänsterna svårare.
Det finns många verktyg som kan tillhandahålla mallar för en hel katalog som innehåller flera källkodskataloger. Yeoman är populärt i JavaScript-världen och GitHub har nyligen släppt lagringsplatsmallar, som ger mycket av samma funktioner.
Uppgiftshantering
Det kan vara svårt att hantera uppgifter i alla projekt. Det finns otaliga frågor att besvara om vilken typ av arbetsflöden som ska konfigureras för att säkerställa optimal produktivitet för utvecklare.
Molnbaserade program tenderar att vara mindre än traditionella programvaruprodukter eller åtminstone är de indelade i mindre tjänster. Spårning av problem eller uppgifter som rör dessa tjänster är fortfarande lika viktigt som med andra programvaruprojekt. Ingen vill förlora reda på något arbetsobjekt eller förklara för en kund att deras problem inte loggades korrekt. Tavlor konfigureras på projektnivå, men inom varje projekt kan områden definieras. Dessa gör det möjligt att dela upp problem mellan flera komponenter. Fördelen med att behålla allt arbete för hela programmet på ett ställe är att det är enkelt att flytta arbetsobjekt från ett team till ett annat eftersom de förstås bättre.
Azure DevOps levereras med ett antal populära mallar som är förkonfigurerade. I den mest grundläggande konfigurationen är allt som behövs för att veta vad som finns i kvarvarande uppgifter, vad människor arbetar med och vad som görs. Det är viktigt att ha den här insynen i processen för att skapa programvara, så att arbetet kan prioriteras och slutföras uppgifter som rapporteras till kunden. Naturligtvis är det få programvaruprojekt som håller sig till en så enkel process som to do, doingoch done. Det tar inte lång tid för personer att börja lägga till steg som QA eller Detailed Specification i processen.
En av de viktigaste delarna av agila metoder är självtrospektion med jämna mellanrum. Dessa granskningar är avsedda att ge insikt i vilka problem teamet står inför och hur de kan förbättras. Ofta innebär detta att ändra flödet av problem och funktioner genom utvecklingsprocessen. Därför är det helt felfritt att utöka layouterna för tavlorna med ytterligare steg.
Stegen i tavlorna är inte det enda organisationsverktyget. Beroende på styrelsens konfiguration finns det en hierarki med arbetsobjekt. Det mest detaljerade objektet som kan visas på en tavla är en uppgift. I rutan innehåller en aktivitet fält för en rubrik, beskrivning, en prioritet, en uppskattning av mängden arbete som återstår och möjligheten att länka till andra arbetsobjekt eller utvecklingsobjekt (grenar, incheckningar, pull-begäranden, byggen och så vidare). Arbetsobjekt kan klassificeras i olika delar av programmet och olika iterationer (sprintar) för att göra det enklare att hitta dem.
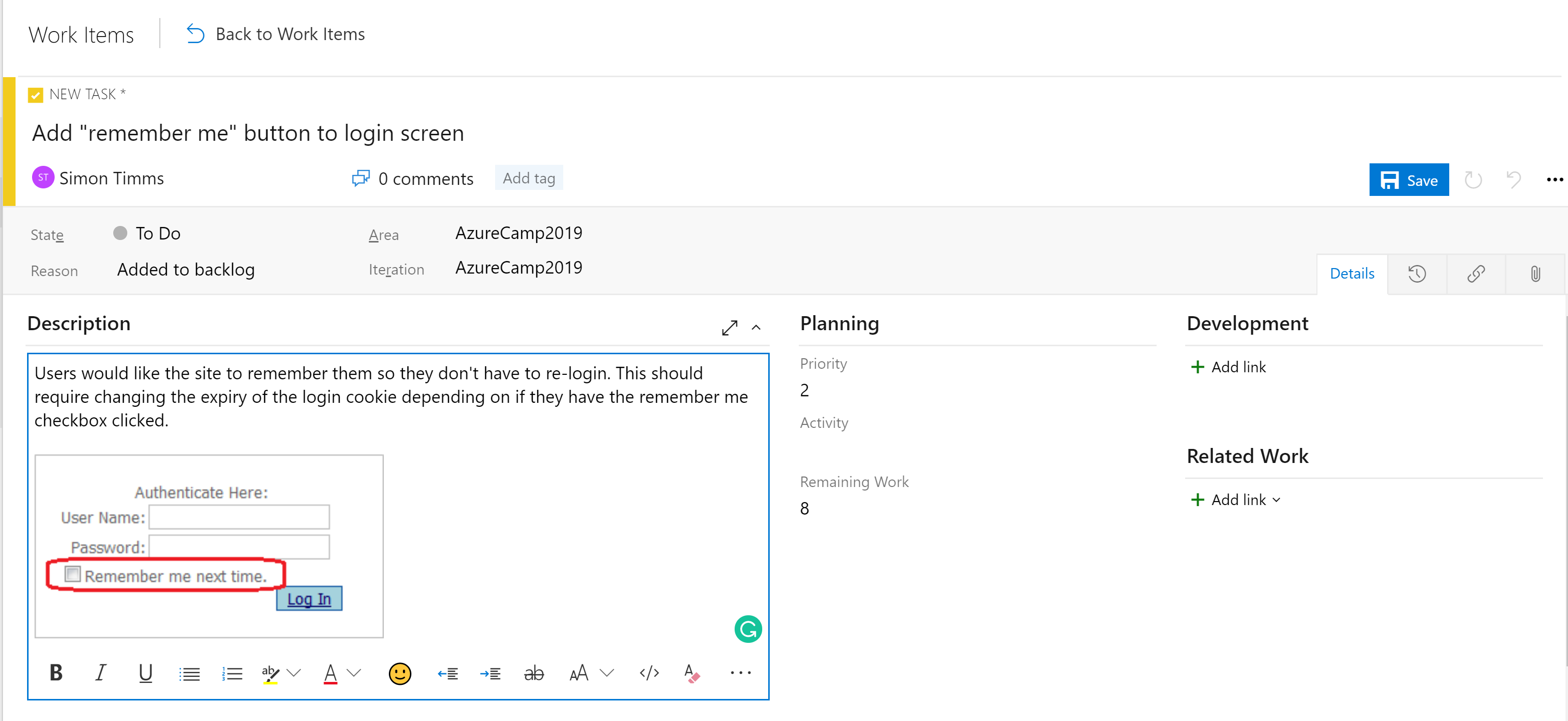
Bild 10–5 – Uppgift i Azure DevOps.
Beskrivningsfältet stöder de normala format du förväntar dig (fetstil, kursivt understreck och genomslag) och möjligheten att infoga bilder. Detta gör det till ett kraftfullt verktyg för användning när du anger arbete eller buggar.
Uppgifter kan summeras till funktioner som definierar en större arbetsenhet. Funktioner kan i sin tur rullas upp till epos. Genom att klassificera uppgifter i den här hierarkin blir det mycket enklare att förstå hur nära en stor funktion är att distribuera.

Bild 10–6 – Arbetsobjekt i Azure DevOps.
Det finns olika typer av vyer i problemen i Azure Boards. Objekt som ännu inte har schemalagts visas i kvarvarande uppgifter. Därifrån kan de tilldelas till en sprint. En sprint är en tidsruta där det förväntas att en viss mängd arbete kommer att slutföras. Det här arbetet kan omfatta uppgifter men även lösning av biljetter. Väl där kan hela sprinten hanteras från sprinttavlans avsnitt. Den här vyn visar hur arbetet fortskrider och innehåller ett nedbränt diagram för att ge en ständigt uppdaterad uppskattning av om sprinten lyckas.
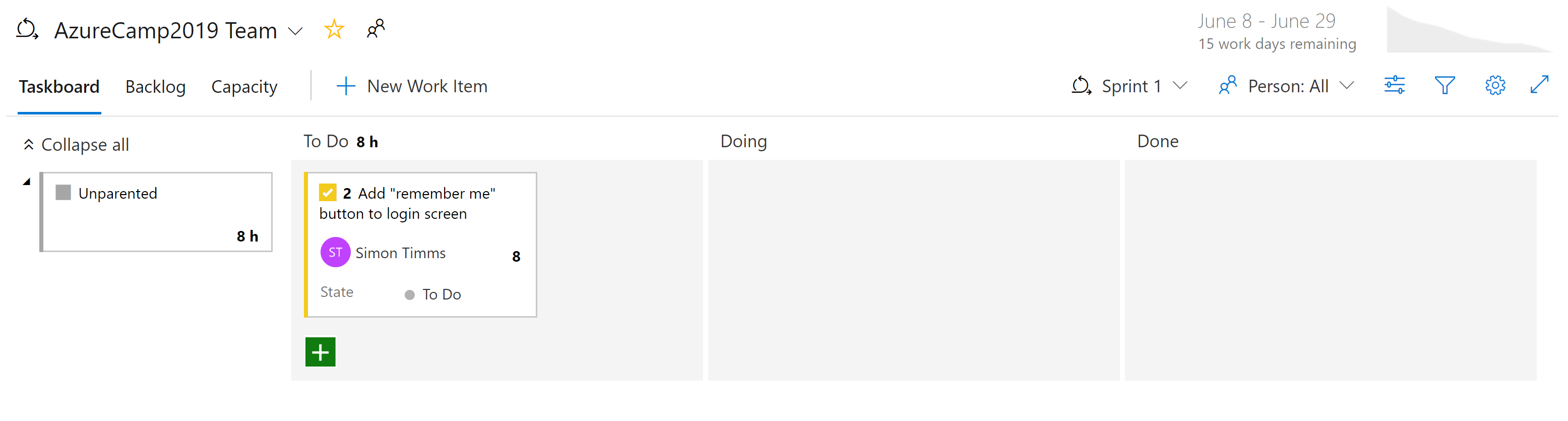
Bild 10–7 – Anslagstavla i Azure DevOps.
Vid det här laget bör det vara uppenbart att det finns en hel del makt i styrelserna i Azure DevOps. För utvecklare finns det enkla vyer över vad som bearbetas. För projektledare kan du se kommande arbeten och få en översikt över befintligt arbete. För chefer finns det gott om rapporter om resursdelning och kapacitet. Tyvärr finns det inget magiskt med molnbaserade program som eliminerar behovet av att spåra arbete. Men om du måste spåra arbete finns det några platser där upplevelsen är bättre än i Azure DevOps.
CI/CD-pipelines
Nästan ingen förändring i livscykeln för programvaruutveckling har varit så revolutionerande som tillkomsten av kontinuerlig integrering (CI) och kontinuerlig leverans (CD). När du skapar och kör automatiserade tester mot källkoden för ett projekt så snart en ändring kontrolleras i fångas misstag tidigt. Före tillkomsten av kontinuerliga integreringsversioner skulle det inte vara ovanligt att hämta kod från lagringsplatsen och upptäcka att den inte klarade tester eller inte ens kunde skapas. Detta resulterade i att källan till brytningen spårades.
Traditionellt leverans av programvara till produktionsmiljön krävde omfattande dokumentation och en lista med steg. Vart och ett av dessa steg behövde slutföras manuellt i en mycket felbenägen process.

Bild 10-8 – Checklista.
Systern till kontinuerlig integrering är kontinuerlig leverans där de nybyggda paketen distribueras till en miljö. Den manuella processen kan inte skalas för att matcha utvecklingshastigheten så automatisering blir viktigare. Checklistor ersätts av skript som kan utföra samma uppgifter snabbare och mer exakt än någon människa.
Den miljö som kontinuerlig leverans levererar till kan vara en testmiljö eller, som många stora teknikföretag gör, det kan vara produktionsmiljön. Det senare kräver en investering i högkvalitativa tester som kan ge förtroende för att en ändring inte kommer att bryta produktionen för användare. På samma sätt som kontinuerlig integrering fångade problem i koden fångar tidig kontinuerlig leverans problem i distributionsprocessen tidigt.
Vikten av att automatisera bygg- och leveransprocessen accentueras av molnbaserade program. Distributioner sker oftare och till fler miljöer, så det går inte att distribuera kantlinjer manuellt.
Azure Builds
Azure DevOps tillhandahåller en uppsättning verktyg för att göra kontinuerlig integrering och distribution enklare än någonsin. De här verktygen finns under Azure Pipelines. Den första av dem är Azure Builds, som är ett verktyg för att köra YAML-baserade byggdefinitioner i stor skala. Användare kan antingen ta med egna byggdatorer (bra för om bygget kräver en minutiöst konfigurerad miljö) eller använda en dator från en ständigt uppdaterad pool med virtuella Azure-värddatorer. Dessa värdbaserade byggagenter är förinstallerade med ett brett utbud av utvecklingsverktyg för inte bara .NET-utveckling utan för allt från Java till Python till i Telefon utveckling.
DevOps innehåller ett brett utbud av färdiga byggdefinitioner som kan anpassas för alla versioner. Versionsdefinitionerna definieras i en fil som heter azure-pipelines.yml och checkas in på lagringsplatsen så att de kan versionshanteras tillsammans med källkoden. Detta gör det mycket enklare att göra ändringar i bygg-pipelinen i en gren eftersom ändringarna kan checkas in på just den grenen. Ett exempel azure-pipelines.yml på hur du skapar ett ASP.NET webbprogram i fullständigt ramverk visas i bild 10–9.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Bild 10–9 – Ett exempel azure-pipelines.yml
Den här byggdefinitionen använder ett antal inbyggda uppgifter som gör det lika enkelt att skapa byggen som att bygga en Lego-uppsättning (enklare än den gigantiska Millennium Falcon). NuGet-uppgiften återställer till exempel NuGet-paket, medan VSBuild-uppgiften anropar Visual Studio-byggverktygen för att utföra den faktiska kompilering. Det finns hundratals olika uppgifter tillgängliga i Azure DevOps, med tusentals fler som underhålls av communityn. Det är troligt att någon redan har skapat en oavsett vilka bygguppgifter du vill köra.
Byggen kan utlösas manuellt, genom en incheckning, enligt ett schema eller när en annan version har slutförts. I de flesta fall är det önskvärt att bygga vidare på varje incheckning. Versioner kan filtreras så att olika versioner körs mot olika delar av lagringsplatsen eller mot olika grenar. Detta möjliggör scenarier som att köra snabba versioner med minskad testning på pull-begäranden och köra en fullständig regressionssvit mot bagageutrymmet varje natt.
Slutresultatet av en version är en samling filer som kallas byggartefakter. Dessa artefakter kan skickas vidare till nästa steg i byggprocessen eller läggas till i en Azure Artifacts-feed, så att de kan användas av andra versioner.
Versioner av Azure DevOps
Byggen tar hand om att kompilera programvaran till ett leveransbart paket, men artefakterna måste fortfarande skickas ut till en testmiljö för att slutföra kontinuerlig leverans. För detta använder Azure DevOps ett separat verktyg med namnet Versioner. Verktyget Versioner använder samma aktivitetsbibliotek som var tillgängligt för versionen, men introducerar begreppet "faser". En fas är en isolerad miljö där paketet är installerat. En produkt kan till exempel använda en utveckling, en kvalitetssäkring och en produktionsmiljö. Koden levereras kontinuerligt till utvecklingsmiljön där automatiserade tester kan köras mot den. När dessa tester har godkänts flyttas versionen till QA-miljön för manuell testning. Slutligen skickas koden till produktion där den är synlig för alla.

Bild 10–10 – Versionspipeline
Varje steg i bygget kan utlösas automatiskt när föregående fas har slutförts. I många fall är detta dock inte önskvärt. Att flytta kod till produktion kan kräva godkännande från någon. Verktyget Versioner stöder detta genom att tillåta godkännare i varje steg i versionspipelinen. Regler kan konfigureras så att en viss person eller grupp av personer måste signera en version innan den tas i produktion. Dessa portar möjliggör manuella kvalitetskontroller och även för efterlevnad av eventuella regelkrav som rör kontroll av vad som hamnar i produktion.
Alla får en bygg-pipeline
Det kostar ingenting att konfigurera många byggpipelines, så det är fördelaktigt att ha minst en byggpipeline per mikrotjänst. Helst kan mikrotjänster distribueras oberoende till alla miljöer, så att var och en kan släppas via sin egen pipeline utan att släppa en massa orelaterad kod är perfekt. Varje pipeline kan ha en egen uppsättning godkännanden som möjliggör variationer i byggprocessen för varje tjänst.
Versionsutgåvor
En nackdel med att använda funktionen Versioner är att den inte kan definieras i en incheckad azure-pipelines.yml fil. Det finns många anledningar till att du kanske vill göra det från att ha versionsdefinitioner per gren till att inkludera ett versionsskelett i projektmallen. Lyckligtvis pågår arbetet med att flytta några av stegens stöd till build-komponenten. Detta kallas för flerstegsversion och den första versionen är tillgänglig nu!