Hämtningsförhöjd generation (RAG) ger LLM-kunskap
Den här artikeln beskriver hur hämtningsförhöjd generation låter LLM:er behandla dina datakällor som kunskap utan att behöva träna.
LLM:er har omfattande kunskapsbas genom träning. I de flesta scenarier kan du välja en LLM som är utformad för dina krav, men dessa LLM:er kräver fortfarande ytterligare utbildning för att förstå dina specifika data. Med hämtningsförhöjd generation kan du göra dina data tillgängliga för LLM:er utan att först träna dem på dem.
Så här fungerar RAG
Om du vill utföra hämtningsförhöjd generering skapar du inbäddningar för dina data tillsammans med vanliga frågor om dem. Du kan göra detta direkt eller skapa och lagra inbäddningarna med hjälp av en vektordatabaslösning.
När en användare ställer en fråga använder LLM dina inbäddningar för att jämföra användarens fråga med dina data och hitta den mest relevanta kontexten. Den här kontexten och användarens fråga går sedan till LLM i en prompt, och LLM ger ett svar baserat på dina data.
Grundläggande RAG-process
För att utföra RAG måste du bearbeta varje datakälla som du vill använda för hämtning. Den grundläggande processen är följande:
- Dela upp stora data i hanterbara delar.
- Konvertera segmenten till ett sökbart format.
- Lagra konverterade data på en plats som ger effektiv åtkomst. Dessutom är det viktigt att lagra relevanta metadata för citat eller referenser när LLM tillhandahåller svar.
- Mata in dina konverterade data till LLM:er i prompter.
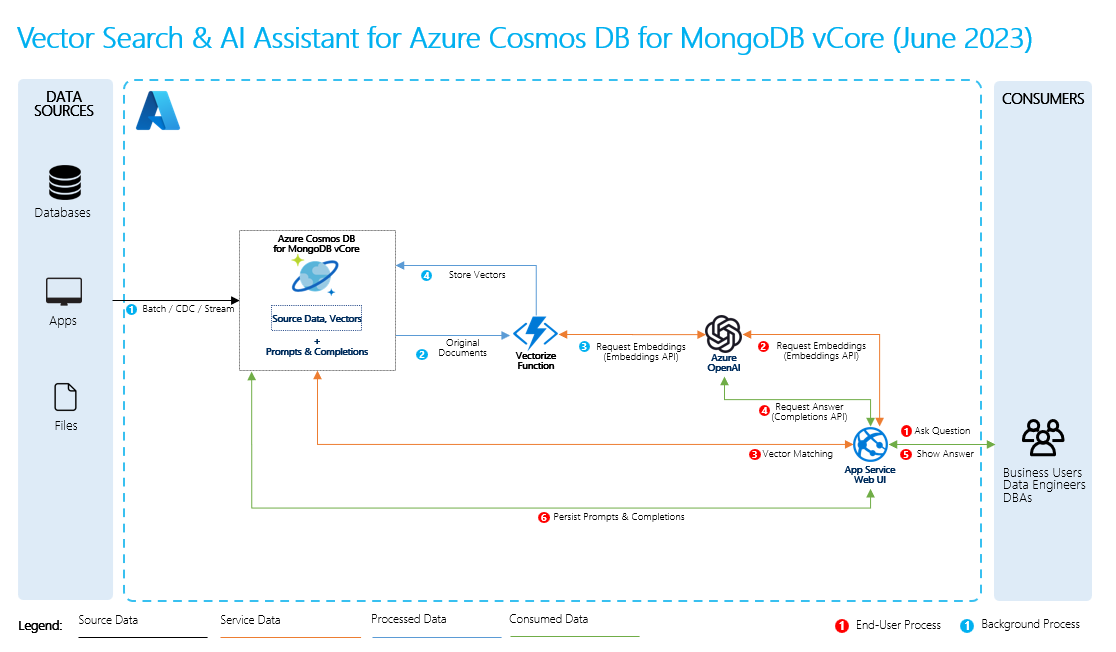
- Källdata: Det är här dina data finns. Det kan vara en fil/mapp på datorn, en fil i molnlagring, en Azure Machine Learning-datatillgång, en Git-lagringsplats eller en SQL-databas.
- Datasegmentering: Data i källan måste konverteras till oformaterad text. Orddokument eller PDF-filer måste till exempel vara öppna och konverterade till text. Texten segmenteras sedan i mindre delar.
- Konvertera texten till vektorer: Det här är inbäddningar. Vektorer är numeriska representationer av begrepp som konverteras till talsekvenser, vilket gör det enkelt för datorer att förstå relationerna mellan dessa begrepp.
- Länkar mellan källdata och inbäddningar: Den här informationen lagras som metadata i de segment som du skapade, som sedan används för att hjälpa LLM:erna att generera citat när svar genereras.