Planera, skala och underhålla en affärskritisk gatewaylösning
Den här artikeln är avsedd för alla som planerar att distribuera en lokal datagateway i ett affärskritiskt scenario. En lokal datagateway är affärskritisk om den är viktig för verksamhetens normala drift och hanterar affärskritiska data.
Om affärskritiska gatewayer inte hanteras korrekt kan det uppstå misslyckade frågor eller långsamma prestanda. När du planerar, skalar och underhåller din affärskritiska gatewaylösning på rätt sätt kan sannolikheten för ett affärspåverkande problem minimeras.
Terminologi
Följande viktiga termer används i hela den här artikeln:
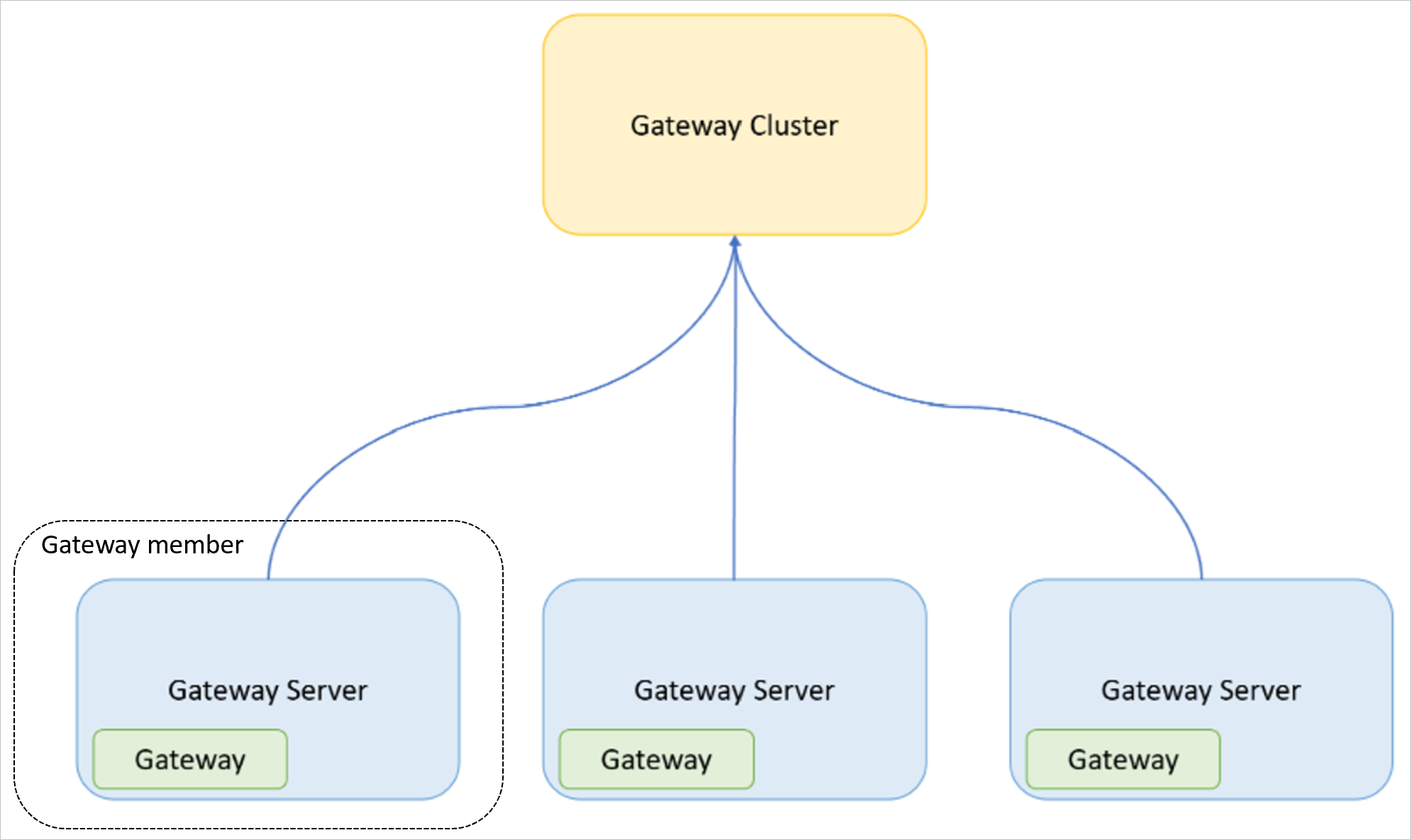
- Gateway: Det lokala datagatewayprogrammet som är installerat på en dator.
- Gateway-server: En Windows-dator (virtuell dator eller fysisk dator/server) som har det lokala datagatewayprogrammet installerat.
- Gatewaykluster: En uppsättning gatewayer som fungerar tillsammans (och kan vara belastningsutjämning).
- Gatewaymedlem: En gateway som ingår i ett gatewaykluster.
Följande bild visar relationen mellan de begrepp som definierats ovan.
Rekommendationer för affärskritiska gatewayer
För affärskritiska gatewayer måste gatewayerna distribueras och hanteras korrekt för att säkerställa hög tillgänglighet, bra prestanda och underhållsbar skalbarhet. Om du distribuerar gatewayer felaktigt kan det leda till dåliga prestanda, misslyckade frågor och problem med att diagnostisera potentiella problem. Det kan också hindra din förmåga att skala upp och ut gatewayerna när användningen växer.
Följ rekommendationerna i nästa avsnitt för att säkerställa optimal skalbarhet, prestanda och dataflöde.
Känna till alla dina gatewayåterställningsnycklar
Se till att alla gateway-återställningsnycklar är kända och förvaras på en säker plats. Utan en återställningsnyckel kan gatewayer inte återställas eller nedgraderas. Den här begränsningen är avsiktlig. Om du förlorar dina återställningsnycklar är det enda alternativet att skapa nya gatewayer och återskapa datakällorna. Du kan inte heller lägga till nya gatewayer i klustret utan återställningsnyckeln, vilket skulle begränsa framtida skalbarhet.
Lagra dina återställningsnycklar på en säker plats på samma sätt som du lagrar administrativa autentiseringsuppgifter, till exempel ett lösenordssäkert värde, som endast kan nås av behöriga administratörer.
Om du för närvarande inte känner till alla dina gatewayåterställningsnycklar är detta en betydande affärsrisk. Skapa omedelbart nya gatewaykluster och börja migrera arbetsbelastningar till gatewaykluster.
Utvecklingsarbetsbelastningar och affärskritiska arbetsbelastningar
Separera utvecklingsarbetsbelastningar från affärskritiska genom att konfigurera ett eller flera development gateway-kluster och ett eller flera produktionsgatewaykluster enligt beskrivningen nedan.
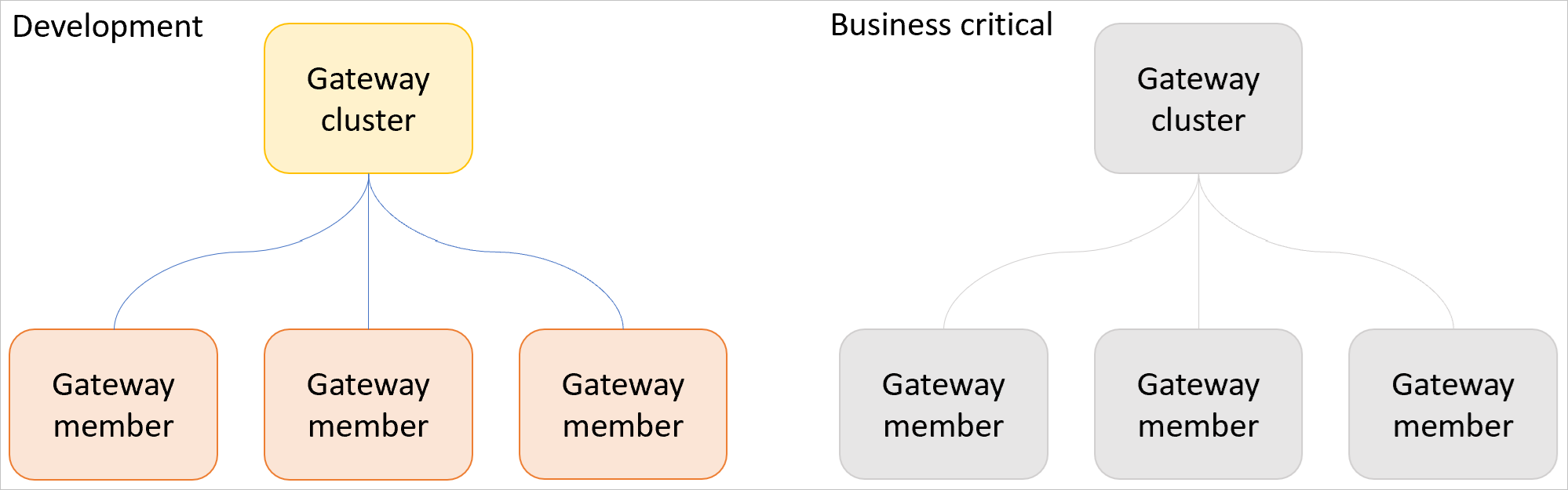
Använd ett kluster för utvecklingsgateway för att testa nya semantiska modeller, rapporter, frågor och så vidare. När en ny arbetsbelastning har verifierats migrerar du den till ett affärskritiskt gatewaykluster. Den här processen förhindrar att nya, otestade eller experimentella arbetsbelastningar får prestandapåverkan på produktionsarbetsbelastningar.
Använd även dina development gateway-kluster för att testa nya gatewayuppdateringar innan du tillämpar uppdateringar på dina affärskritiska gatewaykluster. Nya gatewayuppdateringar bör distribueras i minst 24 timmar i kluster för utvecklingsgateway innan de används på affärskritiska gatewaykluster.
Använda flera gatewaykluster
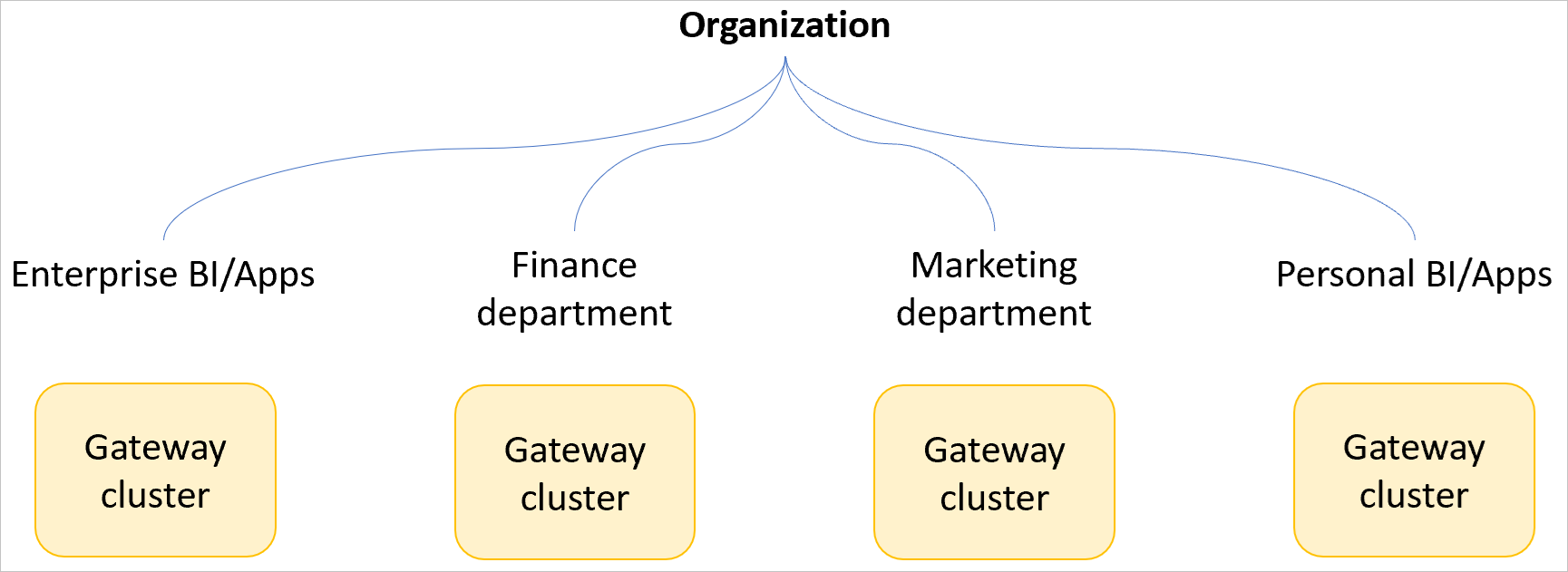
Om du skapar ett gatewaykluster för ett stort antal användare i din organisation måste du skapa flera gatewaykluster baserat på affärsenheter eller mindre för att begränsa eventuella prestandaeffekter till en liten delmängd av användarna.
Vi rekommenderar inte att ett enda affärskritiskt gatewaykluster används för ett helt företag (om inte företaget är litet). I ett scenario med ett enda gatewaykluster kan en användare skicka en fråga som orsakar en betydande prestandapåverkan för all trafik över gatewayen. Om gatewayen används i hela företaget kan prestandapåverkan påverka hela företaget. När ett gatewaykluster används i ett helt företag kan det också vara svårare för dig att identifiera vilken fråga som kan orsaka prestandaproblem när du använder funktionen för övervakning av gatewayprestanda.
Använda gatewayens funktioner för hög tillgänglighet och belastningsutjämning
Använd alltid gatewayens funktioner för hög tillgänglighet och belastningsutjämning för alla affärskritiska gatewaykluster.
- Hög tillgänglighet: Eliminerar en enskild felpunkt.
- Belastningsutjämning: Distribuerar automatiskt arbetsbelastningen över alla gatewayservrar i klustret.
Konfigurera minst två gatewayer per gatewaykluster om en gateway skulle kopplas från av någon anledning. Den här konfigurationen säkerställer att ett enda gatewayfel inte gör att hela gatewayklustret misslyckas. Dessutom kan gränser för processor, minne och samtidighet aktiveras på gatewayerna för att bättre distribuera belastningen över gatewayklustret.
Planera och underhålla skalbarhet för gatewaykluster
Genom att konfigurera ett gatewaykluster med hjälp av våra rekommenderade riktlinjer för maskinvara och programvara kan klustret köras med bra prestanda. Gatewayer som inte skalas korrekt kan leda till dåliga prestanda. Det finns många faktorer som du måste tänka på för att ha bra prestanda i gatewayklustret.
Fastställa maskinvaruspecifikationer för gatewayserver
Gateway-serverspecifikationer (CPU, minne, disk och så vidare) är en viktig faktor, eftersom Power Query-transformeringarna i de flesta fall tillämpas på data på gatewayservern. Därför måste en gateway-server ha tillräckligt med resurser, minne och bearbetningskraft för att hantera alla datatransformeringar.
När du behöver välja en serverstorlek finns det två mått som är viktigast: Minne och CPU. Du behöver både gott om minne och processorkraft för att bearbeta power query-datatransformeringsstegen på gatewayen. Det är viktigt att gatewayservern är tillräckligt kraftfull för att bearbeta den högsta arbetsbelastningen som du har. Om gatewayservern inte kan hantera arbetsbelastningen misslyckas din direkta fråga eller datauppdatering. Det är också viktigt att förstå hur många frågor som körs samtidigt.
Dessa olika frågealternativ har en annan effekt på gatewayservern.
| Frågetyp | Gränsfaktor |
|---|---|
| Importera | Minne |
| DirectQuery | Processor |
| Live Anslut | Processor |
Under en import måste hela datauppsättningen efterfrågas och bearbetas, vilket är en minnesintensiv uppgift. Den här importen tar ofta längre tid också. DirectQueries och Live Anslut ions är ofta cpu-tunga. I de flesta fall körs direkta frågor många gånger för att endast bearbeta en liten del av data. Eftersom endast en liten del av data bearbetas är dessa direkta frågor normalt inte en minnesintensiv uppgift. Men eftersom frågorna körs många gånger på begäran kan detta vara processorintensivt.
Beroende på din arbetsbelastning bör du överväga att optimera gatewayservern för minne eller CPU.
När du ska skala ett gatewaykluster
Skalning är en viktig aspekt av ett affärskritiskt gatewaykluster. När din användning med gatewayklustret växer måste gatewayklustret skalas upp och/eller skalas ut för att säkerställa bra prestanda. Vi rekommenderar att du börjar skala ut ett gatewaykluster om du tidigare har skalat upp gatewayerna i klustret.
Att skala och distribuera trafikbelastningen mellan enskilda noder i ett kluster är en komplex process som varierar beroende på varje enskilt scenario. Det finns ingen slutgiltig modell för att säkerställa att all gatewaytrafik kommer att betjänas förutsägbart, men gränserna nedan anger ett skalningsbehov. I allmänhet rekommenderar vi att du skalar ut (lägger till noder i klustret) företrädesvis för att skala upp (öka CPU, RAM eller diskutrymme på enskilda noder). Utskalning tenderar att vara mer effektivt i hela systemets förmåga att hantera extra trafik. Utskalning har också en positiv inverkan på den totala bandbredd som klustret kan bearbeta, medan uppskalning i allmänhet inte gör det. När en eller flera gatewaynoder visar tecken på att nå tröskelvärdena som beskrivs nedan bör du överväga att skala ut klustret starkt.
CPU: PROCESSORn är över 80 % under längre tidsperioder, men enstaka korta (under 5 minuter) toppar som maxar processorer är inte onormala.
RAM: Tillgängligt minne sjunker under 20 % regelbundet.
Disk: Ledigt diskutrymme sjunker ofta under 5 GB. Det här doppet kan också tyda på ett behov av att konfigurera cachelagrings- eller spoolingkataloger mer strategiskt.
Samtidighet: Köra fler än 40 frågor samtidigt på en enda nod.
Eftersom uppdateringar och frågor som distribueras över gatewaynoder kan ha vitt skilda profiler rekommenderar vi också att extra granskning görs på långvariga eller minnesintensiva jobb. Frågeoptimering kan i sådana fall ha en enorm inverkan på prestanda och skalbarhet, inte bara för enskilda rapporter och uppdateringar, utan på systemet som helhet. Vi rekommenderar att du isolerar aktuella uppdateringar till ett enda dedikerat gatewaykluster för att utvärdera prestandaegenskaper och utföra optimering med hjälp av frågeplansdiagnostik, vikningsindikatorer och alla andra publicerade prestandarekommendationer. Den här isoleringen minimerar mängden data som hämtas och mängden efterbearbetning som krävs. Den här isoleringen kan också användas som en långsiktig strategi för att binda långvariga ETL-jobb till ett dedikerat gatewaykluster för att minska konkurrensen med andra vanliga uppdateringar i organisationen.
Skala upp ett gatewaykluster
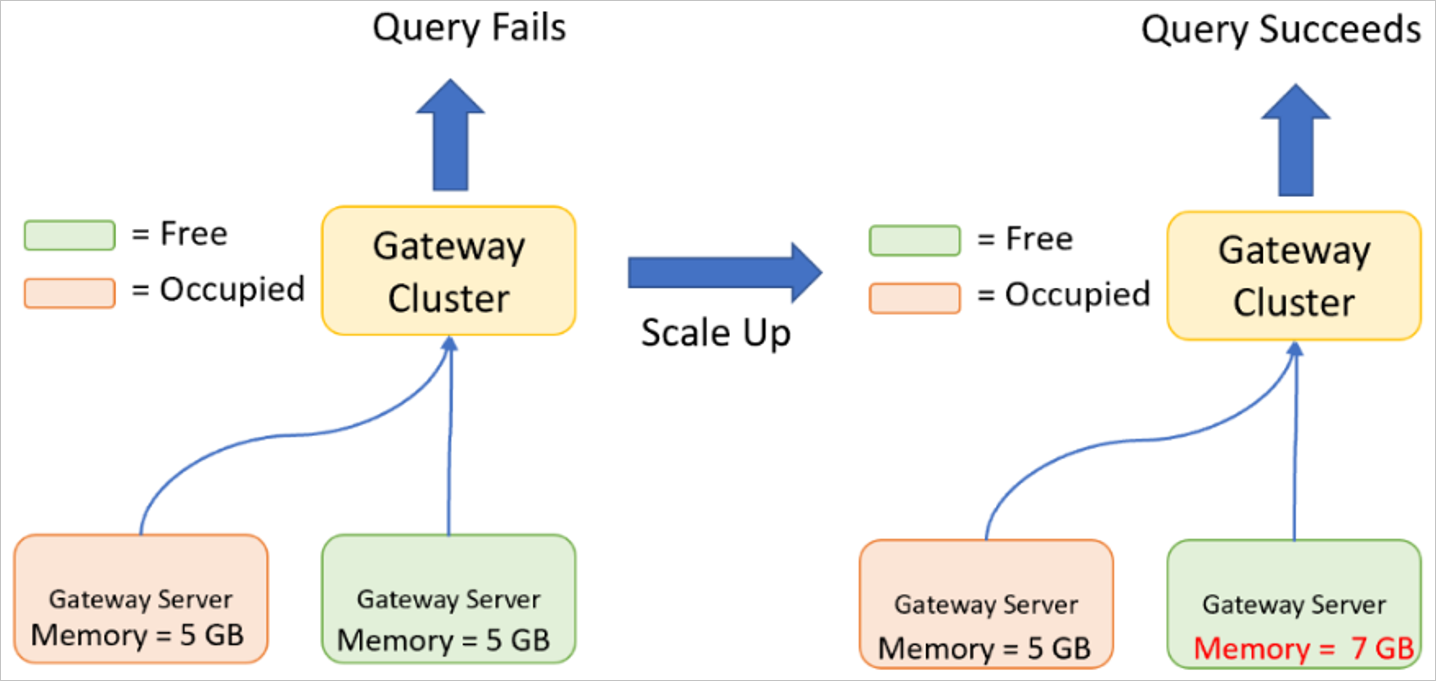
Uppskalning är när du ökar specifikationerna (CPU, minne, disk och så vidare) för dina gatewayservrar.
Det kan krävas uppskalning om maximal cpu eller minne uppnås när gatewayen kör en eller flera frågor. En fråga kan bara köras på en gatewayserver, varför gatewayservern måste ha tillräckligt med resurser tillgängliga för att bearbeta hela frågan tillsammans med resulterande data.
Skala ut ett gatewaykluster
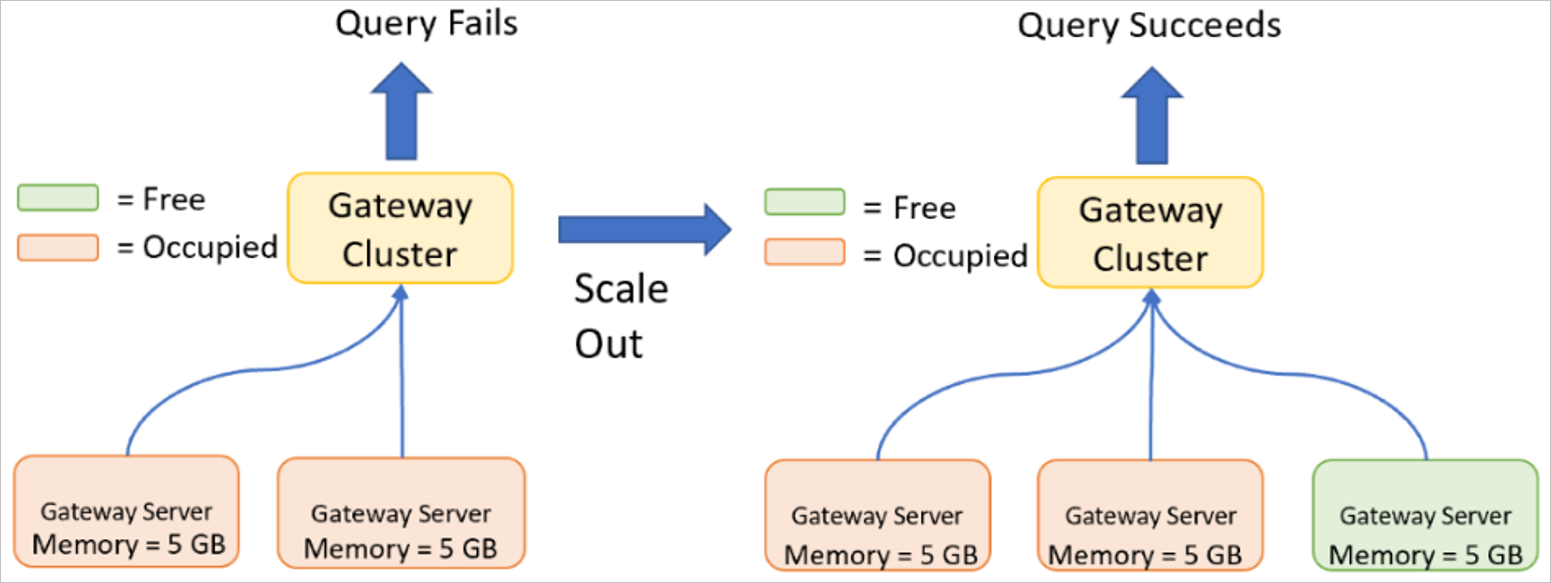
Utskalning krävs om gatewayservern redan har höga specifikationer (det vill säga att gatewayservern redan har skalats upp) eller om du har nått gränserna för vad en enskild gatewayserver kan hantera på grund av antalet samtidiga frågor som körs. Bredbaserad belastningsökning i hela gatewaymedlemsuppsättningen är en bra indikation på att skalning av ett kluster genom att lägga till noder är rätt åtgärd. När du ska skala ett gatewaykluster finns specifika tröskelvärden som anger när det är dags att skala. Mer information om utskalning finns i Använda gatewayens funktioner för hög tillgänglighet och belastningsutjämning.
Skala genom att skapa nya gatewaykluster
Om resursanvändningen för ditt gatewaykluster är hög eller ett exceptionellt stort antal användare är beroende av ett gatewaykluster kan ett nytt gatewaykluster skapas. En delmängd av arbetsbelastningen kan sedan migreras till det nya gatewayklustret. När ett stort antal användare förlitar sig på ett enda gatewaykluster ökar sannolikheten för att en användare kan skicka en fråga som orsakar en betydande prestandapåverkan i hela gatewayklustret avsevärt.
Ett exceptionellt stort antal användare som förlitar sig på ett enda gatewaykluster är en indikator på att ett nytt gatewaykluster ska skapas.
Övervaka och felsöka gatewayprestanda
Det är viktigt att övervaka övergripande prestanda för affärskritiska gatewayer med hjälp av funktionen för övervakning av gatewayprestanda. Du kan också använda den här funktionen för att felsöka prestandaproblem, identifiera flaskhalsar och identifiera frågor som påverkar övergripande gatewayprestanda. Den här funktionen är också ett viktigt verktyg för att hjälpa dig att avgöra när du skalar ett gatewaykluster.
Om du identifierar en fråga som har stor inverkan på gatewayen, vilket resulterar i dåliga övergripande prestanda, kanske du kan skriva om frågan så att den blir mer effektiv och minimera prestandapåverkan.
Om Microsoft identifierar dåliga prestanda som orsakas av en gateway eller en gatewayrelaterad komponent, till exempel en Power BI Premium-kapacitet som är överbelastad, måste den överbelastade komponenten åtgärdas genom att skala eller minska belastningen. Microsoft undersöker inte dåliga prestanda när en gateway eller en gatewayrelaterad komponent är överbelastad.