Ansvarsfull AI i Azure-arbetsbelastningar
Målet med ansvarsfull AI i arbetsbelastningsdesign är att säkerställa att användningen av AI-algoritmer är rättvis, transparent och inkluderande. Väldefinierade säkerhetsprinciper är sammankopplade med fokus på konfidentialitet och integritet. Säkerhetsåtgärder måste finnas för att upprätthålla användarsekretessen, skydda data och skydda designens integritet, som inte bör missbrukas för oavsiktliga ändamål.
I AI-arbetsbelastningar fattas beslut av modeller som ofta använder ogenomskinlig logik. Användarna bör lita på systemets funktioner och känna sig säkra på att beslut fattas på ett ansvarsfullt sätt. Oetiska beteenden, till exempel manipulering, innehålls toxicitet, IP-intrång och fabricerade svar, måste undvikas.
Tänk dig ett användningsfall där ett medieunderhållningsföretag vill ge rekommendationer med hjälp av AI-modeller. Om du inte implementerar ansvarsfull AI och korrekt säkerhet kan det leda till att en dålig aktör tar kontroll över modellerna. Modellen kan potentiellt rekommendera medieinnehåll som kan leda till skadliga resultat. För organisationen kan det här beteendet leda till varumärkesskador, osäkra miljöer och juridiska problem. Därför är det viktigt och icke förhandlingsbart att upprätthålla etisk vaksamhet under hela systemets livscykel.
Etiska beslut bör prioritera säkerhets- och arbetsbelastningshantering med mänskliga resultat i åtanke. Bekanta dig med Microsofts ramverk för ansvarsfull AI och se till att principerna återspeglas och mäts i din design. Den här bilden visar ramverkets grundläggande begrepp.
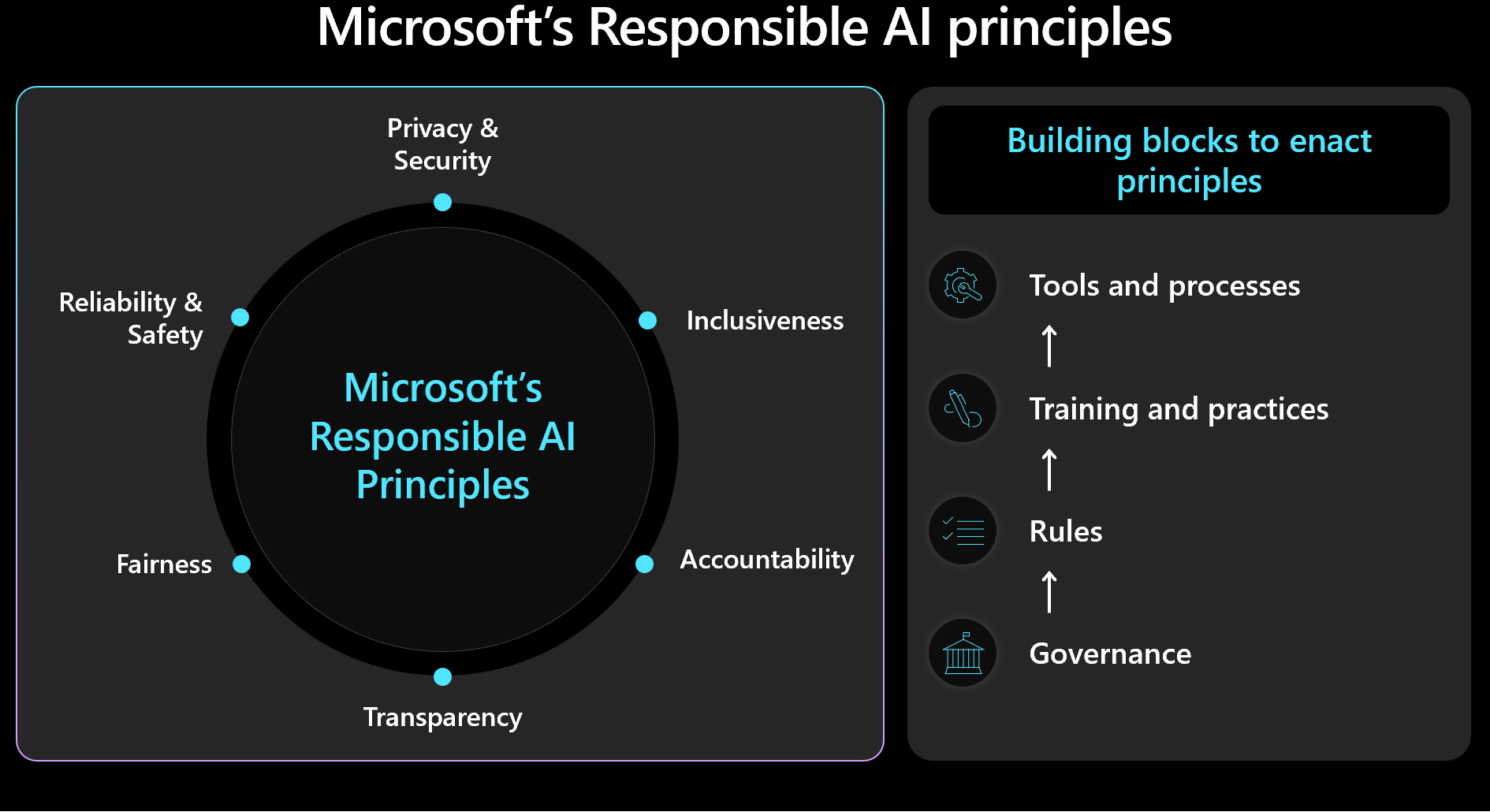
Viktigt!
Precisionen för förutsägelse och ansvarsfulla AI-mått är ofta sammankopplade. Att förbättra en modells noggrannhet kan förbättra dess rättvisa och anpassning till verkligheten. Men även om etisk AI ofta överensstämmer med noggrannhet inkluderar inte enbart noggrannhet alla etiska överväganden. Det är viktigt att verifiera dessa etiska principer på ett ansvarsfullt sätt.
Den här artikeln innehåller rekommendationer om etiskt beslutsfattande, validering av användarindata och säker användarupplevelse. Det ger också vägledning om datasäkerhet för att se till att användardata skyddas.
Rekommendationer
Här är sammanfattningen av rekommendationerna i den här artikeln.
| Rekommendation | beskrivning |
|---|---|
| Utveckla principer som tillämpar etiska metoder i varje fas av livscykeln. | Inkludera checklistobjekt som uttryckligen anger etiska krav, skräddarsydda för arbetsbelastningskontexten. Exempel är användardatatransparens, medgivandekonfiguration och procedurer för hantering av "Rätten att bli bortglömd". ▪ Utveckla dina ansvarsfulla AI-principer ▪ Framtvinga styrning av ansvarsfulla AI-principer |
| Skydda användardata med målet att maximera sekretessen. | Samla bara in det som är nödvändigt och med rätt användarmedgivande. Använd tekniska kontroller för att skydda användarprofiler, deras data och åtkomst till dessa data. ▪ Hantera användardata etiskt ▪ Inspektera inkommande och utgående data |
| Håll AI-beslut tydliga och begripliga. | Håll tydliga förklaringar av hur rekommendationsalgoritmer fungerar och ge användarna insikter om dataanvändning och algoritmiskt beslutsfattande för att säkerställa att de förstår och litar på processen. ▪ Gör användarupplevelsen säker |
Utveckla ansvarsfulla AI-principer
Dokumentera din metod för etisk och ansvarsfull AI-användning. Uttryckligen tillståndsprinciper som tillämpas i varje steg i livscykeln så att arbetsbelastningsteamet förstår sitt ansvar. Microsofts ansvarsfulla AI-standarder ger riktlinjer, men du måste definiera vad dessa betyder specifikt för din kontext.
Principerna bör till exempel innehålla checklistobjekt för mekanismer kring transparens för användardata och medgivandekonfiguration, vilket helst gör det möjligt för användare att välja bort datainkludering. Datapipelines, analys, modellträning och andra steg måste alla respektera det valet. Ett annat exempel är procedurer för att hantera "Rätten att bli bortglömd". Kontakta organisationens etikavdelning och juridiska team för att fatta välgrundade beslut.
Skapa transparenta principer kring dataanvändning och algoritmiskt beslutsfattande för att säkerställa att användarna förstår och litar på processen. Dokumentera dessa beslut för att upprätthålla en tydlig historik för potentiella framtida rättstvister.
Implementering av etisk AI omfattar tre viktiga roller: forskargruppen, policyteamet och teknikteamet. Samarbete mellan dessa team bör operationaliseras. Om din organisation har ett befintligt team kan du dra nytta av deras arbete. i annat fall bör du etablera dessa metoder själv.
Ha ansvar för ansvarsfördelning:
Forskningsteamet utför riskidentifiering genom att konsultera organisationens riktlinjer, branschstandarder, lagar, förordningar och kända röda teamtaktiker.
Principteamet utvecklar principer som är specifika för arbetsbelastningen och innehåller riktlinjer från den överordnade organisationen och myndighetsregler.
Teknikteamet implementerar principerna i sina processer och slutprodukter, vilket säkerställer att de validerar och testar efterlevnad.
Varje team formaliserar sina riktlinjer, men arbetsbelastningsteamet måste vara ansvarigt för sina egna dokumenterade metoder. Teamet bör tydligt dokumentera eventuella ytterligare steg eller avsiktliga avvikelser, så att det inte finns någon tvetydighet om vad som är tillåtet. Var också transparent om eventuella brister eller oväntade resultat i lösningen.
Framtvinga styrning av ansvarsfulla AI-principer
Utforma din arbetsbelastning så att den följer organisations- och regelstyrningen. Om transparens till exempel är ett organisationskrav kan du bestämma hur det ska tillämpas på din arbetsbelastning. Identifiera områden i din design, livscykel, kod eller andra komponenter, där transparensfunktioner bör introduceras för att uppfylla den standarden.
Förstå de styrnings-, ansvars-, gransknings- och rapporteringsmandat som krävs. Se till att arbetsbelastningsdesignen godkänns och godkänns av styrningsrådet för att undvika omdesigner och minimera etiska problem eller sekretessproblem. Du kan behöva gå igenom flera lager av godkännande. Här är en typisk struktur för styrning.
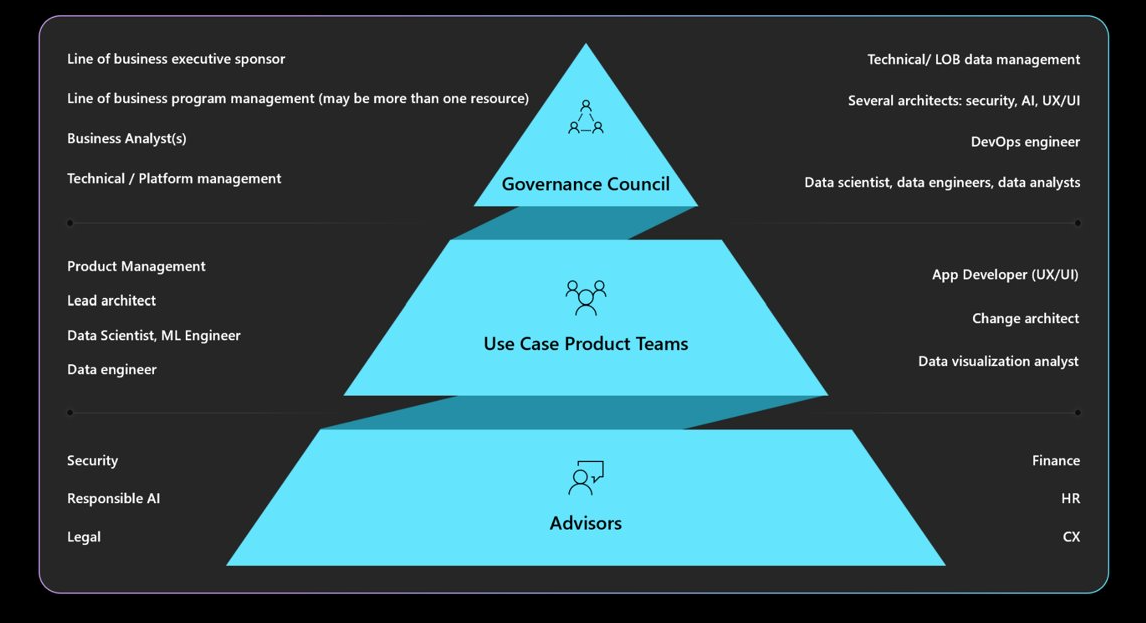
Information om organisationsprinciper och godkännare finns i Cloud Adoption Framework: Define a responsible AI strategy (Molnimplementeringsramverk: Definiera en ansvarsfull AI-strategi).
Gör användarupplevelsen säker
Användarupplevelser bör baseras på branschriktlinjer. Dra nytta av Designbiblioteket för Microsoft Human-AI-upplevelser som innehåller principer och tillhandahåller implementering av dos och don'ts, med exempel från Microsoft-produkter och andra branschkällor.
Det finns arbetsbelastningsansvar under hela livscykeln för användarinteraktion från användarens avsikt att använda systemet, under en session och störningar på grund av systemfel. Här följer några metoder att tänka på:
Skapa transparens. Gör användarna medvetna om hur systemet genererade svaret på deras fråga.
Inkludera länkar till datakällor som konsulteras av modellen för förutsägelser för att förbättra användarnas förtroende genom att visa informationens ursprung. Datadesign bör se till att dessa källor ingår i metadata. När orkestreraren i ett program med förhöjd hämtning utför en sökning hämtar den till exempel 20 dokumentsegment och skickar de 10 översta segmenten, som tillhör tre olika dokument, till modellen som kontext. Användargränssnittet kan sedan referera till dessa tre källdokument när modellens svar visas, vilket ökar transparensen och användarförtroendet.
Transparens blir viktigare när du använder agenter, som fungerar som mellanhänder mellan klientdelsgränssnitt och serverdelssystem. I ett biljettsystem tolkar orkestreringskoden till exempel användarens avsikt och gör API-anrop till agenter för att hämta nödvändig information. Att exponera dessa interaktioner kan göra användaren medveten om systemets åtgärder.
För automatiserade arbetsflöden med flera inblandade agenter skapar du loggfiler som registrerar varje steg. Den här funktionen hjälper dig att identifiera och korrigera fel. Dessutom kan den ge användarna förklaringar till beslut, vilket operationaliserar transparensen.
Varning
När du implementerar transparensrekommendationer bör du undvika att överbelasta användaren med för mycket information. Använd en gradvis metod där du börjar med minimalt störande användargränssnittsmetoder.
Du kan till exempel visa en knappbeskrivning med en konfidenspoäng från modellen. Du kan lägga till en länk som användarna kan klicka på för att få mer information, till exempel länkar till källdokument. Den här användarinitierade metoden håller användargränssnittet icke-störande och låter användarna söka ytterligare information endast om de väljer att göra det.
Samla in feedback. Implementera feedbackmekanismer.
Undvik att överväldiga användare med omfattande enkäter efter varje svar. Använd i stället enkla, snabba feedbackmekanismer som tummen upp/ner eller klassificeringssystem för specifika aspekter av svaret på en skala från 1 till 5. Den här metoden möjliggör detaljerad feedback utan att vara påträngande, vilket hjälper till att förbättra systemet över tid. Tänk på potentiella fördomar i feedback, eftersom det kan finnas sekundära orsaker bakom användarsvar.
Implementeringen av en feedbackmekanism påverkar arkitekturen på grund av behovet av datalagring. Behandla detta som användardata och tillämpa nivåer av sekretesskontroll efter behov.
Förutom feedback om svar samlar du in feedback om användarupplevelsens effekt. Detta kan göras genom att samla in engagemangsmått via din övervakningsstack i systemet.
Operationalisera säkerhetsåtgärder för innehåll
Integrera innehållssäkerhet i varje steg i AI-livscykeln med hjälp av anpassad lösningskod, lämpliga verktyg och effektiva säkerhetsrutiner. Här följer några strategier.
Dataidentifiering. När data flyttas från inmatning till träning eller utvärdering, har du kontroller längs vägen för att minimera risken för att läcka personlig information och undvika exponering av rådata.
Con tältläge ration. Använd innehållssäkerhets-API:et som utvärderar begäranden och svar i realtid och se till att dessa API:er kan nås.
Identifiera och minimera hot. Tillämpa välkända säkerhetsrutiner på dina AI-scenarier. Du kan till exempel utföra hotmodellering och dokumentera hot och deras lindring. Vanliga säkerhetsrutiner som Red Team-övningar gäller för AI-arbetsbelastningar. Röda team kan testa om modeller kan manipuleras för att generera skadligt innehåll. Dessa aktiviteter bör integreras i AI-åtgärder.
Information om hur du utför red team-testning finns i Planera röd teamindelning för stora språkmodeller (LLM: er) och deras program.
Använd rätt mått. Använd lämpliga mått som är effektiva för att mäta modellens etiska beteende. Måtten varierar beroende på typen av AI-modell. Mätning av generativa modeller kanske inte gäller för regressionsmodeller. Tänk dig en modell som förutsäger förväntad livslängd och resultatet påverkar försäkringspriserna. Bias i den här modellen kan leda till etiska problem, men det problemet beror på avvikelse i grundläggande måtttestning. Att förbättra noggrannheten kan minska etiska problem, eftersom etiska mått och noggrannhetsmått ofta är sammankopplade.
Lägg till etisk instrumentation. AI-modellresultat måste vara förklarande. Du måste motivera och spåra hur slutsatsdragningar görs, inklusive de data som används för träning, de beräknade funktionerna och grunddata. I diskriminerande AI kan du motivera beslut steg för steg. För generativa modeller kan det dock vara komplicerat att förklara resultat. Dokumentera beslutsprocessen för att hantera potentiella rättsliga konsekvenser och ge insyn.
Den här förklaringsaspekten bör implementeras under hela AI-livscykeln. Datarensning, ursprung, urvalskriterier och bearbetning är viktiga steg där beslut bör spåras.
Verktyg
Verktyg för innehållssäkerhet och dataspårning, som Microsoft Purview, bör integreras. Azure AI Content Safety-API :er kan anropas från testningen för att underlätta innehållssäkerhetstestning.
Azure AI Foundry tillhandahåller mått som utvärderar modellens beteende. Mer information finns i Utvärderings- och övervakningsmått för generativ AI.
För träningsmodeller rekommenderar vi att du granskar måtten som tillhandahålls av Azure Machine Learning.
Inspektera inkommande och utgående data
Snabbinmatningsattacker, till exempel jailbreaking, är ett vanligt problem för AI-arbetsbelastningar. I det här fallet kan vissa användare försöka missbruka modellen för oavsiktliga ändamål. För att säkerställa säkerheten kontrollerar du data för att förhindra attacker och filtrera bort olämpligt innehåll. Den här analysen bör tillämpas på både användarens indata och systemets svar för att säkerställa att det finns en grundlig kon tältläge ration i både inkommande och utgående flöden.
I scenarier där du gör flera modellanrop, till exempel via Azure OpenAI, för att hantera en enda klientbegäran kan det vara kostsamt och onödigt att tillämpa innehållssäkerhetskontroller på varje anrop. Överväg att centralisera det arbetet i arkitekturen samtidigt som du behåller säkerheten som ett ansvar på serversidan. Anta att en arkitektur har en gateway framför modellslutpunkten för slutsatsdragning för att avlasta vissa serverdelsfunktioner. Den gatewayen kan utformas för att hantera innehållssäkerhetskontroller för både begäranden och svar som serverdelen kanske inte stöder internt. En gateway är en vanlig lösning, men ett orkestreringslager kan hantera dessa uppgifter effektivt i enklare arkitekturer. I båda fallen kan du selektivt tillämpa dessa kontroller när det behövs, vilket optimerar prestanda och kostnader.
Inspektionerna bör vara multimodala och omfatta olika format. När du använder multimodala indata, till exempel bilder, är det viktigt att analysera dem för dolda meddelanden som kan vara skadliga eller våldsamma. Dessa meddelanden kanske inte visas omedelbart, ungefär som osynlig pennanteckning, och kräver noggrann kontroll. Använd verktyg som API:er för innehållssäkerhet för det här ändamålet.
Om du vill tillämpa sekretess- och datasäkerhetsprinciper kontrollerar du användardata och grunddata för efterlevnad av sekretessregler. Kontrollera att data är sanerade eller filtrerade när de flödar genom systemet. Data från tidigare kundsupportkonversationer kan till exempel fungera som grunddata. Den bör saneras innan den återanvänds.
Hantera användardata etiskt
Etiska metoder omfattar noggrann hantering av användardatahantering. Detta inkluderar att veta när du ska använda data och när du ska undvika att förlita sig på användardata.
Slutsatsdragning utan att dela användardata. Om du vill dela användardata på ett säkert sätt med andra organisationer för insikter använder du en clearinghouse-modell. I det här scenariot tillhandahåller organisationer data till en betrodd tredje part, som tränar en modell med hjälp av aggregerade data. Den här modellen kan sedan användas av alla institutioner, vilket ger delade insikter utan att exponera enskilda datauppsättningar. Målet är att använda modellens slutsatsdragningsfunktioner utan att dela detaljerade träningsdata.
Främja mångfald och inkludering. När användardata är nödvändiga använder du en mängd olika data, inklusive underrepresenterade genrer och skapare, för att minimera bias. Implementera funktioner som uppmuntrar användare att utforska nytt och varierat innehåll. Ha kontinuerlig övervakning av användning och justera rekommendationer för att undvika att överreplikering av en enskild innehållstyp.
Respektera "Rätten att bli bortglömd". Undvik att använda användardata när det är möjligt. Se till att "Rätten att bli bortglömd" efterlevs genom att ha nödvändiga åtgärder på plats för att se till att användardata tas bort noggrant.
För att säkerställa efterlevnad kan det finnas begäranden om att ta bort användardata från systemet. För mindre modeller kan detta uppnås genom omträning med data som utesluter personlig information. För större modeller, som kan bestå av flera mindre, oberoende tränade modeller, är processen mer komplex och kostnaden och ansträngningen är betydande. Sök juridisk och etisk vägledning om hur du hanterar dessa situationer och se till att detta ingår i din policy för ansvarsfull AI, som beskrivs i Utveckla ansvarsfulla AI-principer.
Behåll på ett ansvarsfullt sätt. När det inte går att ta bort data får du uttryckligt användarmedgivande för datainsamling och tillhandahåller tydliga sekretesspolicyer. Samla endast in och behålla data när det är absolut nödvändigt. Ha åtgärder på plats för att ta bort data aggressivt när de inte längre behövs. Rensa till exempel chatthistorik så snart det är praktiskt och anonymisera känsliga data före kvarhållning. Kontrollera att avancerade krypteringsmetoder används för dessa vilande data.
Supportförklarbarhet. Spåra beslut i systemet för att stödja förklaringskrav. Utveckla tydliga förklaringar av hur rekommendationsalgoritmer fungerar och ge användarna insikter om varför specifikt innehåll rekommenderas för dem. Målet är att säkerställa att AI-arbetsbelastningar och deras resultat är transparenta och motiverade, med information om hur beslut fattas, vilka data som användes och hur modeller tränades.
Kryptera användardata. Indata måste krypteras i varje steg i databearbetningspipelinen från det ögonblick då användaren anger data. Detta inkluderar data när de flyttas från en punkt till en annan, där de lagras och under slutsatsdragning, om det behövs. Balansera säkerhet och funktioner men strävar efter att hålla data privata under hela livscykeln.
Information om krypteringstekniker finns i Programdesign.
Tillhandahålla robusta åtkomstkontroller. Flera typer av identiteter kan potentiellt komma åt användardata. Implementera rollbaserad åtkomstkontroll (RBAC) för både kontrollplanet och dataplanet, som omfattar kommunikation mellan användare och system.
Upprätthålla även rätt användarsegmentering för att skydda sekretessen. Till exempel kan Copilot för Microsoft 365 söka efter och ge svar baserat på en användares specifika dokument och e-postmeddelanden, vilket säkerställer att endast innehåll som är relevant för användaren nås.
Information om hur du framtvingar åtkomstkontroller finns i Programdesign.
Minska ytan. En grundläggande strategi för den välarkitekterade ramverkets säkerhetspelare är att minimera attackytan och härda resurser. Den här strategin bör tillämpas på standardmetoder för slutpunktssäkerhet genom att strikt kontrollera API-slutpunkter, exponera endast viktiga data och undvika onödig information i svar. Designvalet bör balanseras mellan flexibilitet och kontroll.
Kontrollera att det inte finns några anonyma slutpunkter. I allmänhet bör du undvika att ge klienterna mer kontroll än nödvändigt. I de flesta scenarier behöver klienter inte justera hyperparametrar förutom i experimentella miljöer. För vanliga användningsfall, till exempel interaktion med en virtuell agent, bör klienter endast kontrollera viktiga aspekter för att garantera säkerheten genom att begränsa onödig kontroll.
Mer information finns i Programdesign.