Azure Kubernetes-nätverksprinciper
Nätverksprinciper ger mikrosegmentering för poddar precis som nätverkssäkerhetsgrupper (NSG:er) ger mikrosegmentering för virtuella datorer. Implementeringen av Azure Network Policy Manager stöder standardspecifikationen för Kubernetes-nätverksprinciper. Du kan använda etiketter för att välja en grupp poddar och definiera en lista över regler för inkommande och utgående trafik för att filtrera trafik till och från dessa poddar. Läs mer om Kubernetes-nätverksprinciper i Kubernetes-dokumentationen.
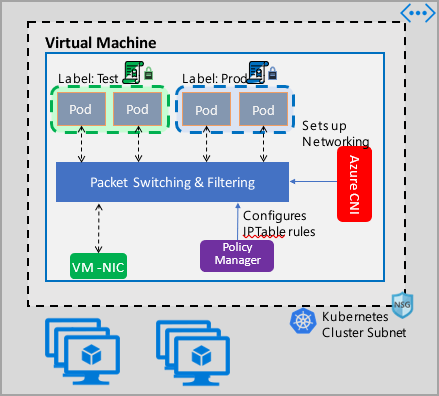
Implementeringen av Azure Network Policy Management fungerar med Azure CNI som tillhandahåller integrering av virtuella nätverk för containrar. Nätverksprinciphanteraren stöds på Linux och Windows Server. Implementeringen framtvingar trafikfiltrering genom att konfigurera tillåtna och neka IP-regler baserat på de definierade principerna i Linux IPTables eller Värdnätverkstjänst (HNS) ACLPolicies för Windows Server.
Planera säkerhet för ditt Kubernetes-kluster
När du implementerar säkerhet för klustret använder du nätverkssäkerhetsgrupper (NSG:er) för att filtrera trafik som kommer in i och lämnar klustrets undernät (nord-syd-trafik). Använd Azure Network Policy Manager för trafik mellan poddar i klustret (trafik mellan öst och väst).
Använda Azure Network Policy Manager
Azure Network Policy Manager kan användas på följande sätt för att tillhandahålla mikrosegmentering för poddar.
Azure Kubernetes Service (AKS)
Network Policy Manager är tillgängligt internt i AKS och kan aktiveras när klustret skapas.
Mer information finns i Skydda trafik mellan poddar med hjälp av nätverksprinciper i Azure Kubernetes Service (AKS).
Gör det själv (DIY) Kubernetes-kluster i Azure
För DIY-kluster installerar du först CNI-plugin-programmet och aktiverar det på varje virtuell dator i ett kluster. Detaljerade anvisningar finns i avsnittet om att distribuera plugin-programmet för ett Kubernetes-kluster som du distribuerar själv.
När klustret har distribuerats kör du följande kubectl kommando för att ladda ned och tillämpa Azure Network Policy Manager-daemonuppsättningen på klustret.
För Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
För Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
Lösningen är också öppen källkod och koden är tillgänglig på Azure Container Networking-lagringsplatsen.
Övervaka och visualisera nätverkskonfigurationer med Azure NPM
Azure Network Policy Manager innehåller informativa Prometheus-mått som gör att du kan övervaka och få en bättre förståelse för dina konfigurationer. Den tillhandahåller inbyggda visualiseringar i antingen Azure-portalen eller Grafana Labs. Du kan börja samla in dessa mått med antingen Azure Monitor eller en Prometheus-server.
Fördelar med Azure Network Policy Manager-mått
Användare kunde tidigare bara lära sig om sin nätverkskonfiguration med iptables och ipset kommandon körs i en klusternod, vilket ger utförliga och svåra att förstå utdata.
Sammantaget ger måtten:
Antal principer, ACL-regler, ipsets, ipset-poster och poster i en viss ipset
Körningstider för enskilda OS-anrop och för hantering av kubernetes-resurshändelser (median, 90:e percentilen och 99:e percentilen)
Felinformation för hantering av kubernetes-resurshändelser (dessa resurshändelser misslyckas när ett OS-anrop misslyckas)
Exempel på användningsfall för mått
Aviseringar via en Prometheus AlertManager
Se en konfiguration för dessa aviseringar på följande sätt.
Avisering när Network Policy Manager har ett fel med ett OPERATIVSYSTEM-anrop eller när en nätverksprincip översätts.
Avisering när mediantiden för att tillämpa ändringar för en skapa-händelse var mer än 100 millisekunder.
Visualiseringar och felsökning via vår Grafana-instrumentpanel eller Azure Monitor-arbetsbok
Se hur många IPTables-regler som dina principer skapar (om du har ett stort antal IPTables-regler kan svarstiden öka något).
Korrelera klusterantal (till exempel ACL:er) till körningstider.
Hämta det människovänliga namnet på en ipset i en viss IPTables-regel (till exempel
azure-npm-487392representerarpodlabel-role:database).
Alla mått som stöds
Följande lista är över mått som stöds. Alla quantile etiketter har möjliga värden 0.5, 0.9och 0.99. Alla had_error etiketter har möjliga värden false och true, som representerar om åtgärden lyckades eller misslyckades.
| Måttnamn | beskrivning | Prometheus-måtttyp | Etiketter |
|---|---|---|---|
npm_num_policies |
antal nätverksprinciper | Mätare | - |
npm_num_iptables_rules |
antal IPTables-regler | Mätare | - |
npm_num_ipsets |
antal IPSets | Mätare | - |
npm_num_ipset_entries |
antal IP-adressposter i alla IPSets | Mätare | - |
npm_add_iptables_rule_exec_time |
runtime för att lägga till en IPTables-regel | Sammanfattning | quantile |
npm_add_ipset_exec_time |
runtime för att lägga till en IPSet | Sammanfattning | quantile |
npm_ipset_counts (avancerat) |
antal poster inom varje enskild IPSet | GaugeVec |
set_name & set_hash |
npm_add_policy_exec_time |
runtime för att lägga till en nätverksprincip | Sammanfattning |
quantile & had_error |
npm_controller_policy_exec_time |
runtime för att uppdatera/ta bort en nätverksprincip | Sammanfattning |
quantile & had_erroroperation (med värden update eller delete) |
npm_controller_namespace_exec_time |
runtime för att skapa/uppdatera/ta bort ett namnområde | Sammanfattning |
quantile & had_erroroperation (med värden create, updateeller delete) |
npm_controller_pod_exec_time |
runtime för att skapa/uppdatera/ta bort en podd | Sammanfattning |
quantile & had_erroroperation (med värden create, updateeller delete) |
Det finns också måtten "exec_time_count" och "exec_time_sum" för varje "exec_time" sammanfattningsmått.
Måtten kan skrapas via Azure Monitor för containrar eller via Prometheus.
Konfigurera för Azure Monitor
Det första steget är att aktivera Azure Monitor för containrar för ditt Kubernetes-kluster. Steg finns i Översikt över Azure Monitor för containrar. När du har aktiverat Azure Monitor för containrar konfigurerar du Azure Monitor för containrar ConfigMap för att aktivera Network Policy Manager-integrering och insamling av Prometheus Network Policy Manager-mått.
Azure Monitor för containrar ConfigMap har ett integrations avsnitt med inställningar för att samla in Network Policy Manager-mått.
De här inställningarna är inaktiverade som standard i ConfigMap. Aktivera den grundläggande inställningen collect_basic_metrics = true, samlar in grundläggande Network Policy Manager-mått. Aktivering av den avancerade inställningen collect_advanced_metrics = true samlar in avancerade mått utöver grundläggande mått.
När du har redigerat ConfigMap sparar du den lokalt och tillämpar ConfigMap på klustret på följande sätt.
kubectl apply -f container-azm-ms-agentconfig.yaml
Följande kodfragment kommer från Azure Monitor för containrar ConfigMap, som visar nätverksprinciphanterarens integrering aktiverad med avancerad måttsamling.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Avancerade mått är valfria och om du aktiverar dem aktiveras automatiskt grundläggande måttinsamling. Avancerade mått omfattar för närvarande endast Network Policy Manager_ipset_counts.
Läs mer om insamlingsinställningar för Azure Monitor för containrar i konfigurationskartan.
Visualiseringsalternativ för Azure Monitor
När network policy manager-måttsamlingen är aktiverad kan du visa måtten i Azure Portal med hjälp av containerinsikter eller i Grafana.
Visa i Azure Portal under insikter för klustret
Öppna Azure-portalen. En gång i klustrets insikter navigerar du till Arbetsböcker och öppnar Network Policy Manager (Network Policy Manager) Configuration.
Förutom att visa arbetsboken kan du också köra frågor direkt mot Prometheus-måtten i "Loggar" under avsnittet insikter. Den här frågan returnerar till exempel alla mått som samlas in.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Du kan också fråga log analytics direkt för måtten. Mer information finns i Komma igång med Log Analytics-frågor.
Visa i Grafana-instrumentpanelen
Konfigurera Grafana Server och konfigurera en log analytics-datakälla enligt beskrivningen här. Importera sedan Grafana-instrumentpanelen med en Log Analytics-serverdel till dina Grafana Labs.
Instrumentpanelen har visuella objekt som liknar Azure-arbetsboken. Du kan lägga till paneler i diagrammet och visualisera Network Policy Manager-mått från tabellen InsightsMetrics.
Konfigurera för Prometheus-servern
Vissa användare kan välja att samla in mått med en Prometheus-server i stället för Azure Monitor för containrar. Du behöver bara lägga till två jobb i din skrapkonfiguration för att samla in Mått för Network Policy Manager.
Om du vill installera en Prometheus-server lägger du till den här helm-lagringsplatsen i klustret:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
lägg sedan till en server
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
där prometheus-server-scrape-config.yaml består av:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Du kan också ersätta azure-npm-node-metrics jobbet med följande innehåll eller införliva det i ett befintligt jobb för Kubernetes-poddar:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Konfigurera aviseringar för AlertManager
Om du använder en Prometheus-server kan du konfigurera en AlertManager så här. Här är en exempelkonfiguration för de två aviseringsregler som beskrevs tidigare:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Visualiseringsalternativ för Prometheus
När du använder en Prometheus Server stöds endast Grafana-instrumentpanelen.
Om du inte redan har gjort det konfigurerar du Grafana-servern och konfigurerar en Prometheus-datakälla. Importera sedan vår Grafana-instrumentpanel med en Prometheus-serverdel till dina Grafana Labs.
De visuella objekten för den här instrumentpanelen är identiska med instrumentpanelen med en serverdel för containerinsikter/log analytics.
Exempelinstrumentpaneler
Här följer några exempelinstrumentpaneler för Network Policy Manager-mått i containerinsikter (CI) och Grafana.
ANTAL CI-sammanfattningar
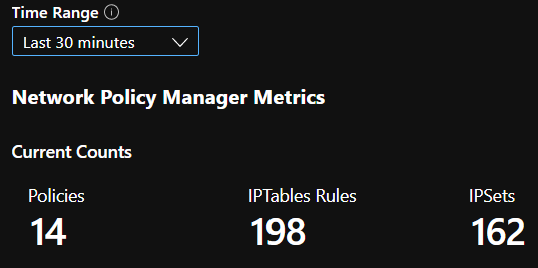
CI räknas över tid

CI IPSet-poster

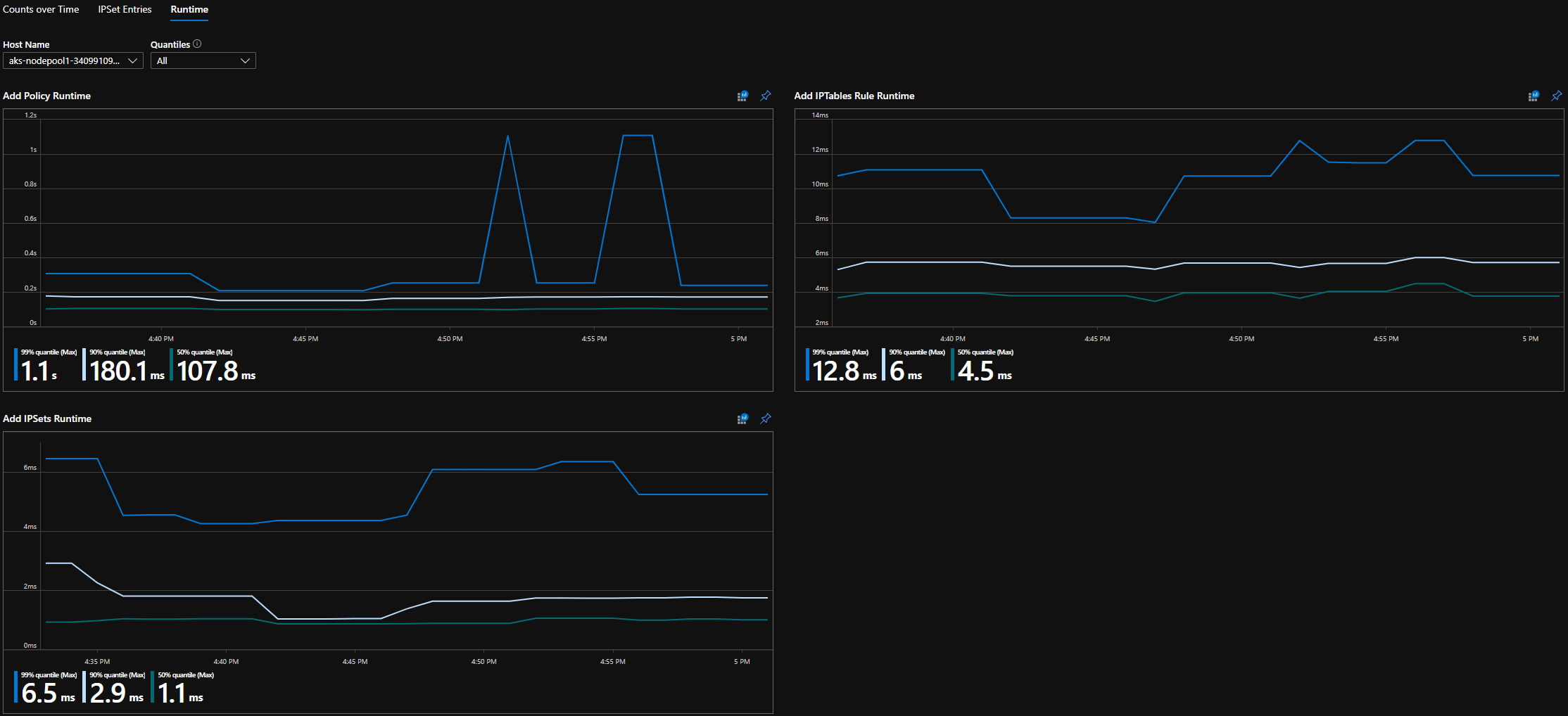
CI-körnings quantiles
Antal sammanfattningar av Grafana-instrumentpaneler
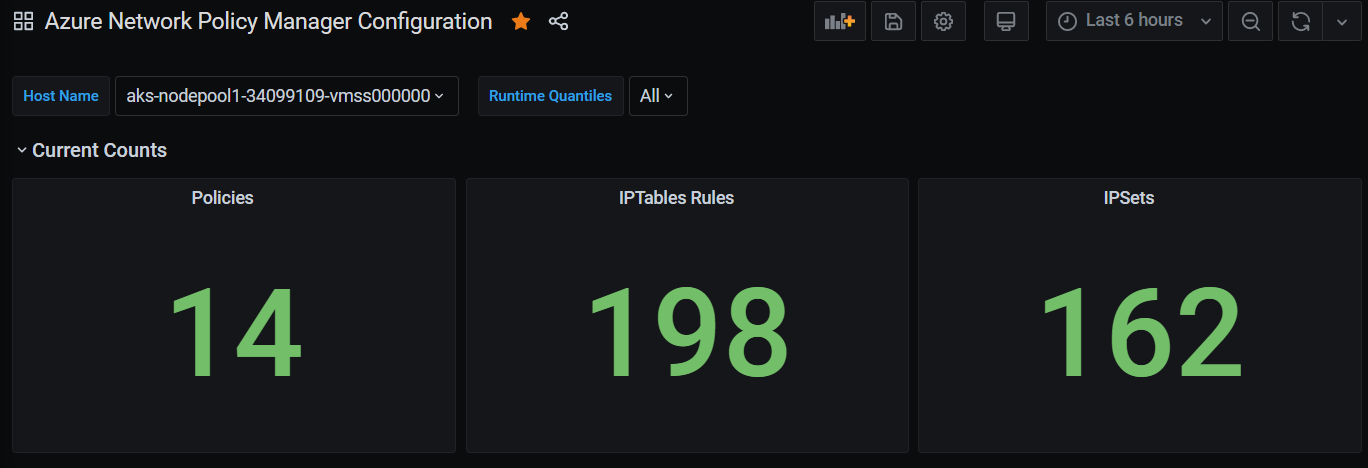
Antal Grafana-instrumentpaneler över tid

Poster för GRAFANA-instrumentpanelens IPSet

Grafana-instrumentpanelens körnings quantiles
