Prestandajustering med materialiserade vyer med dedikerad SQL-pool i Azure Synapse Analytics
I en dedikerad SQL-pool tillhandahåller materialiserade vyer en metod för lågt underhåll för komplexa analysfrågor för att få snabba prestanda utan någon frågeändring. Den här artikeln beskriver den allmänna vägledningen om hur du använder materialiserade vyer.
Materialiserade vyer jämfört med standardvyer
SQL-poolen stöder både standardvyer och materialiserade vyer. Båda är virtuella tabeller som skapas med SELECT-uttryck och presenteras för frågor som logiska tabeller. Vyer visar komplexiteten i vanliga databeräkningar och lägger till ett abstraktionslager i beräkningsändringar så att du inte behöver skriva om frågor.
En standardvy beräknar sina data varje gång vyn används. Det finns inga data lagrade på disken. Personer använder vanligtvis standardvyer som ett verktyg som hjälper till att organisera logiska objekt och frågor i en databas. Om du vill använda en standardvy måste en fråga referera direkt till den.
En materialiserad vy förberäknar, lagrar och underhåller sina data i en dedikerad SQL-pool precis som en tabell. Omkomputation behövs inte varje gång en materialiserad vy används. Det är därför frågor som använder alla eller en delmängd av data i materialiserade vyer kan få snabbare prestanda. Ännu bättre är att frågor kan använda en materialiserad vy utan att direkt referera till den, så det finns inget behov av att ändra programkoden.
De flesta standardvykraven gäller fortfarande för en materialiserad vy. Mer information om syntaxen för materialiserad vy och andra krav finns i SKAPA MATERIALISERAD VY SOM SELECT.
| Jämförelse | Visa | Materialiserad vy |
|---|---|---|
| Visa definition | Lagras i Azure-informationslagret. | Lagras i Azure-informationslagret. |
| Visa innehåll | Genereras varje gång vyn används. | Förbearbetade och lagrade i Azure-informationslagret när vyn skapades. Uppdateras när data läggs till i de underliggande tabellerna. |
| Datauppdatering | Alltid uppdaterad | Alltid uppdaterad |
| Hastighet för att hämta visningsdata från komplexa frågor | Långsam | Snabb |
| Extra lagringsutrymme | Inga | Ja |
| Syntax | CREATE VIEW | SKAPA MATERIALISERAD VY SOM SELECT |
Fördelar med materialiserade vyer
En korrekt utformad materialiserad vy ger följande fördelar:
Kortare körningstid för komplexa frågor med JOIN och mängdfunktioner. Ju mer komplex frågan är, desto högre är risken för att körningstiden ska sparas. Den största fördelen uppnås när en frågas beräkningskostnad är hög och den resulterande datauppsättningen är liten.
Frågeoptimeraren i en dedikerad SQL-pool kan automatiskt använda distribuerade materialiserade vyer för att förbättra frågekörningsplanerna. Den här processen är transparent för användare som ger snabbare frågeprestanda och kräver inte att frågor refererar direkt till de materialiserade vyerna.
Kräver lågt underhåll av vyerna. En materialiserad vy lagrar data på två platser, ett grupperat kolumnlagringsindex för de första data vid tidpunkten då vyn skapades och ett deltalager för de inkrementella dataändringarna. Alla dataändringar från bastabellerna läggs automatiskt till i deltalagret på ett synkront sätt. En bakgrundsprocess (tupppelflyttare) flyttar regelbundet data från deltalagret till vyns kolumnlagringsindex. Den här designen gör att frågor mot materialiserade vyer kan returnera samma data som att fråga bastabellerna direkt.
Data i en materialiserad vy kan distribueras annorlunda än bastabellerna.
Data i materialiserade vyer får samma fördelar med hög tillgänglighet och återhämtning som data i vanliga tabeller.
Jämfört med andra datalagerleverantörer ger de materialiserade vyer som implementeras i en dedikerad SQL-pool också följande ytterligare fördelar:
- Automatisk och synkron datauppdatering med dataändringar i bastabeller. Användaren behöver inte göra någonting.
- Brett stöd för mängdfunktioner. Se SKAPA MATERIALISERAD VY SOM SELECT (Transact-SQL).
- Stöd för frågespecifik materialiserad vyrekommendering. Se EXPLAIN (Transact-SQL).
Vanliga scenarier
Materialiserade vyer används vanligtvis i följande scenarier:
Behov av att förbättra prestandan för komplexa analysfrågor mot stora data i storlek
Komplexa analysfrågor använder vanligtvis fler aggregeringsfunktioner och tabellkopplingar, vilket orsakar mer beräkningsintensiva åtgärder som shuffles och kopplingar i frågekörning. Det är därför dessa frågor tar längre tid att slutföra, särskilt i stora tabeller.
Användare kan skapa materialiserade vyer för de data som returneras från vanliga beräkningar av frågor, så det krävs ingen omberäkning när dessa data behövs av frågor, vilket ger lägre beräkningskostnader och snabbare frågesvar.
Behöver snabbare prestanda utan eller minsta frågeändringar
Schema- och frågeändringar i informationslager hålls vanligtvis till ett minimum för att stödja ETL-regelbundna åtgärder och rapportering. Personer kan använda materialiserade vyer för frågeprestandajustering om kostnaden för vyerna kan kompenseras av att frågeprestandan ökar.
Jämfört med andra justeringsalternativ, till exempel skalning och statistikhantering, är det en mycket mindre effektfull produktionsförändring för att skapa och underhålla en materialiserad vy och dess potentiella prestandavinst är också högre.
- Att skapa eller underhålla materialiserade vyer påverkar inte de frågor som körs mot bastabellerna.
- Frågeoptimeraren kan automatiskt använda de distribuerade materialiserade vyerna utan direkt vyreferens i en fråga. Den här funktionen minskar behovet av frågeändring i prestandajusteringen.
Behöver en annan strategi för datadistribution för snabbare frågeprestanda
Azure Data Warehouse är ett distribuerat och massivt parallellt bearbetningssystem (MPP).
Synapse SQL är ett distribuerat frågesystem som gör det möjligt för företag att implementera scenarier för informationslager och datavirtualisering med hjälp av vanliga T-SQL-upplevelser som är bekanta för datatekniker. Den utökar också funktionerna i SQL för att hantera scenarier för direktuppspelning och maskininlärning. Data i en informationslagertabell distribueras över 60 noder med någon av tre distributionsstrategier (hash, round_robin eller replikerad).
Datadistributionen anges när tabellen skapas och förblir oförändrad tills tabellen tas bort. Materialiserad vy som en virtuell tabell på disk stöder hash- och round_robin datadistributioner. Användare kan välja en datadistribution som skiljer sig från bastabellerna, men optimal för prestanda för frågor som ofta använder vyerna.
Designvägledning
Här är den allmänna vägledningen om hur du använder materialiserade vyer för att förbättra frågeprestanda:
Utforma för din arbetsbelastning
Innan du börjar skapa materialiserade vyer är det viktigt att ha en djup förståelse för din arbetsbelastning när det gäller frågemönster, prioritet, frekvens och storleken på resulterande data.
Användare kan köra EXPLAIN WITH_RECOMMENDATIONS <SQL_statement> för de materialiserade vyer som rekommenderas av frågeoptimeraren. Eftersom dessa rekommendationer är frågespecifika kanske en materialiserad vy som gynnar en enskild fråga inte är optimal för andra frågor i samma arbetsbelastning.
Utvärdera dessa rekommendationer med dina arbetsbelastningsbehov i åtanke. De ideala materialiserade vyerna är de som gynnar arbetsbelastningens prestanda.
Var medveten om kompromissen mellan snabbare frågor och kostnaden
För varje materialiserad vy finns det en datalagringskostnad och en kostnad för att underhålla vyn. När data ändras i bastabellerna ökar storleken på den materialiserade vyn och dess fysiska struktur ändras också.
För att undvika försämrad frågeprestanda underhålls varje materialiserad vy separat av informationslagermotorn, inklusive flytt av rader från deltalager till segmenten för kolumnlagringsindex och konsolidering av dataändringar.
Underhållsarbetsbelastningen ökar när antalet materialiserade vyer och bastabelländringar ökar. Användarna bör kontrollera om kostnaden för alla materialiserade vyer kan kompenseras av frågeprestandavinsten.
Du kan köra den här frågan för listan över materialiserad vy i en databas:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Alternativ för att minska antalet materialiserade vyer:
Identifiera vanliga datauppsättningar som ofta används av komplexa frågor i din arbetsbelastning. Skapa materialiserade vyer för att lagra dessa datauppsättningar så att optimeraren kan använda dem som byggstenar när du skapar körningsplaner.
Ta bort de materialiserade vyer som har låg användning eller som inte längre behövs. En inaktiverad materialiserad vy underhålls inte, men den medför fortfarande lagringskostnader.
Kombinera materialiserade vyer som skapats i samma eller liknande bastabeller även om deras data inte överlappar varandra. Om du kombinerar materialiserade vyer kan det resultera i en större vy i storlek än summan av de separata vyerna, men kostnaden för visningsunderhåll bör minska. Exempel:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Det är inte alla prestandajusteringar som kräver frågeändring
Datalageroptimeraren kan automatiskt använda distribuerade materialiserade vyer för att förbättra frågeprestanda. Det här stödet tillämpas transparent på frågor som inte refererar till vyerna och för frågor som använder aggregeringar som inte stöds när materialiserade vyer skapas. Ingen frågeändring krävs. Du kan kontrollera en frågas beräknade körningsplan för att bekräfta om en materialiserad vy används.
- Mer information om hur du hämtar den faktiska körningsplanen finns i Övervaka din dedikerade SQL-poolarbetsbelastning i Azure Synapse Analytics med DMV:er.
- Du kan hämta en beräknad körningsplan via SQL Server Management Studio (SSMS) eller SET-SHOWPLAN_XML.
Övervaka materialiserade vyer
En materialiserad vy lagras i informationslagret precis som en tabell med grupperat columnstore-index (CCI). Läsning av data från en materialiserad vy omfattar genomsökning av indexet och tillämpning av ändringar från deltalagret. När antalet rader i Delta Store är för högt kan det ta längre tid att matcha en fråga från en materialiserad vy än att fråga bastabellerna direkt.
För att undvika försämring av frågeprestanda är det en bra idé att köra DBCC-PDW_SHOWMATERIALIZEDVIEWOVERHEAD för att övervaka vyns overhead_ratio (total_rows/base_view_row). Om overhead_ratio är för hög bör du överväga att återskapa den materialiserade vyn så att alla rader i deltalagret flyttas till kolumnlagringsindexet.
Cachelagring av materialiserad vy och resultatuppsättning
Dessa två funktioner introduceras i en dedikerad SQL-pool ungefär samtidigt för justering av frågeprestanda. Cachelagring av resultatuppsättningar används för att uppnå hög samtidighet och snabba svarstider från repetitiva frågor mot statiska data.
Om du vill använda det cachelagrade resultatet måste formatet för den cachebegärande frågan matcha den fråga som skapade cachen. Dessutom måste det cachelagrade resultatet gälla för hela frågan.
Materialiserade vyer tillåter dataändringar i bastabellerna. Data i materialiserade vyer kan tillämpas på en del av en fråga. Det här stödet gör att samma materialiserade vyer kan användas av olika frågor som delar viss beräkning för snabbare prestanda.
Exempel
I det här exemplet används en TPCDS-liknande fråga som hittar kunder som spenderar mer pengar via katalog än i butiker. Den identifierar också de kunder som föredras och deras ursprungsland/ursprungsregion. Frågan omfattar att välja DE 100 ÖVERSTA posterna från UNION för tre under-SELECT-instruktioner som involverar SUM() och GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Kontrollera frågans beräknade körningsplan. Det finns 18 blandningar och 17 kopplingsåtgärder, vilket tar längre tid att köra.
Nu ska vi skapa en materialiserad vy för var och en av de tre sub-SELECT-uttrycken.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Kontrollera körningsplanen för den ursprungliga frågan igen. Nu ändras antalet kopplingar från 17 till 5 och det finns ingen blandning längre. Välj ikonen Filteråtgärd i planen. Dess utdatalista visar att data läse från de materialiserade vyerna i stället för bastabeller.
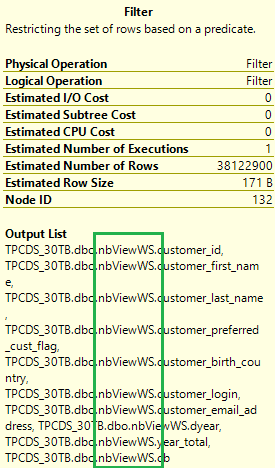
Med materialiserade vyer körs samma fråga mycket snabbare utan någon kodändring.
Nästa steg
Fler utvecklingstips finns i Översikt över Synapse SQL-utveckling.